








已在GitHub开源与本博客同步的YOLOv8_RK3588_object_pose
项目,地址:https://github.com/A7bert777/YOLOv8_RK3588_object_pose
详细使用教程,可参考README.md或参考本博客第六章 模型部署
一、项目回顾
博主之前有写过YOLO11、YOLOv8目标检测&图像分割、YOLOv10目标检测、MoblieNetv2图像分类的模型训练、转换、部署文章,感兴趣的小伙伴可以了解下:
【YOLO11部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8部署至RK3588】模型训练→转换rknn→部署全流程
【YOLOv8seg部署RK3588】模型训练→转换rknn→部署全流程
【YOLOv10部署RK3588】模型训练→转换rknn→部署流程
【MobileNetv2图像分类部署至RK3588】模型训练→转换rknn→部署流程
YOLOv8n部署RK3588开发板全流程(pt→onnx→rknn模型转换、板端后处理检测)
最近做了一个YOLOv8 pose的关键点检测项目,涉及模型训练、转ONNX、转RKNN量化以及RK3588开发板调试部署,查了下CSDN上暂未有关于YOLOv8 pose在RK系列开发板的免费详细教程,遂开此文,相互学习。
二、文件梳理
YOLOv8 pose的训练、转换、部署所需四个项目文件:
第一个:YOLOv8模型训练项目文件(链接在此),
第二个:瑞芯微仓库中YOLOv8的pt转onnx项目文件(链接在此);
第三个:用于在虚拟机中进行onnx转rknn的虚拟环境配置项目文件(链接在此);
第四个:在开发板上做模型部署的项目文件(链接在此)。
注:
1.第四个项目文件中的内容很多,里面涉及到rknn模型转换以及模型部署的所有内容,所以该文件在模型转换中也要与第三个文件配合使用。
2.我上面的四个链接都是已经链接到项目的对应版本了,打开链接后直接git clone或者download zip即可。
这四个文件的版本如下:
第一个模型训练文件是v8.3之前的版本,因为v8.3之后就是YOLO11了,此处选择的是v8.2.82
第二个ONNX转换文件为默认main分支
第三个文件rknn-toolkit2为v2.1.0
第四个文件rknn_model_zoo也用v2.1.0(rknn-toolkit2尽量和rknn_model_zoo版本一致)
如图所示:
三、YOLOv8-pose模型训练
YOLOv8-pose的模型训练和此前的YOLOv8、YOLOv10基本一致。
先从训练环境搭建开始,YOLOv8-pose的环境搭建非常简单,不需要再pip install -r requirements.txt和pip install -e .了。
步骤如下:
1. conda create -n yolov8 python=3.9
2. conda activate yolov8
3. pip install ultralytics
配置好环境后,把另外一些必要的文件准备好:
自己创建一个train.py脚本,放在和ultralytics文件夹同级位置,然后把ultralytics文件夹中的yolov8.yaml文件复制出来,在把yolov8n.pt放进来,因为训练开始前会用预训练权重进行Automatic Mixed Precision(AMP自动混合精度)check,如果你没放预训练权重,终端会自己下载,但是速度较慢,所以先提前放置过来。
train.py内容如下:
from ultralytics import YOLO
# 加载模型
model = YOLO("yolov8-pose.yaml") # 从头开始构建新模型
#model = YOLO("yolov8n.pt") # 加载预训练模型(推荐用于训练)
# Use the model
# 以下设置最好不要改动!!!可能会出现关键点漂移的问题
results = model.train(
data="knob-pose.yaml",
epochs=300,
batch=4,
augment=False, # 关闭所有数据增强
degrees=0, # 旋转角度=0
translate=0, # 平移=0
scale=0, # 缩放=0
shear=0, # 剪切=0
flipud=0, # 上下翻转概率=0
fliplr=0 # 左右翻转概率=0
)
yolov8.yaml内容如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
knob-pose.yaml文件如下:
# Ultralytics YOLO 🚀, AGPL-3.0 license
# Custom Knob Pose Dataset Configuration
# Dataset paths (absolute paths already specified)
train: /xxx/Dataset/Patrol_system/Knob/Knob_KeyPoint_Dataset/v2_new_koutu_dataset/v2/images/train
val: /xxx/Dataset/Patrol_system/Knob/Knob_KeyPoint_Dataset/v2_new_koutu_dataset/v2/images/val
# Keypoints configuration
kpt_shape: [2, 2] # 2 keypoints (head, tail), each with (x,y,visibility)
#flip_idx: [1, 0] # When image is flipped horizontally, head<->tail should swap
flip_idx: [] # 设为空列表,禁用翻转交换
# Classes
names:
0: knob
# No need for download section since using custom dataset
执行train.py文件:python train.py,训练完成后,如下所示:

四、PT转ONNX
把前面训练得到的PT模型放置到第二个项目文件中
注:我把PT模型重命名为4_8_knob_pose_head_tail_best.pt,把第二项目文件重命名为ultralytics_yolov8_pt2onnx_8.2.82,其余照旧。
注:放yolov8n.pt是为了避免自动下载模型,因为要做AMP自动混合精度检测,提前放模型进去,避免龟速下载。
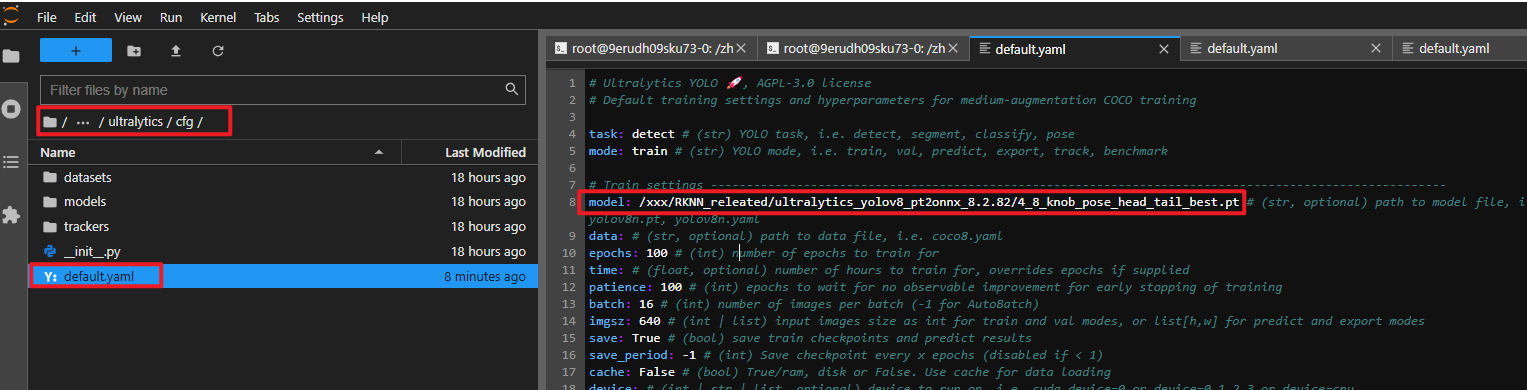
调整 ./ultralytics/cfg/default.yaml 中 model 文件路径,默认为 yolov8n.pt,若自己训练模型,请调接至对应的路径。支持检测、分割、姿态、旋转框检测模型。我修改的结果如下:
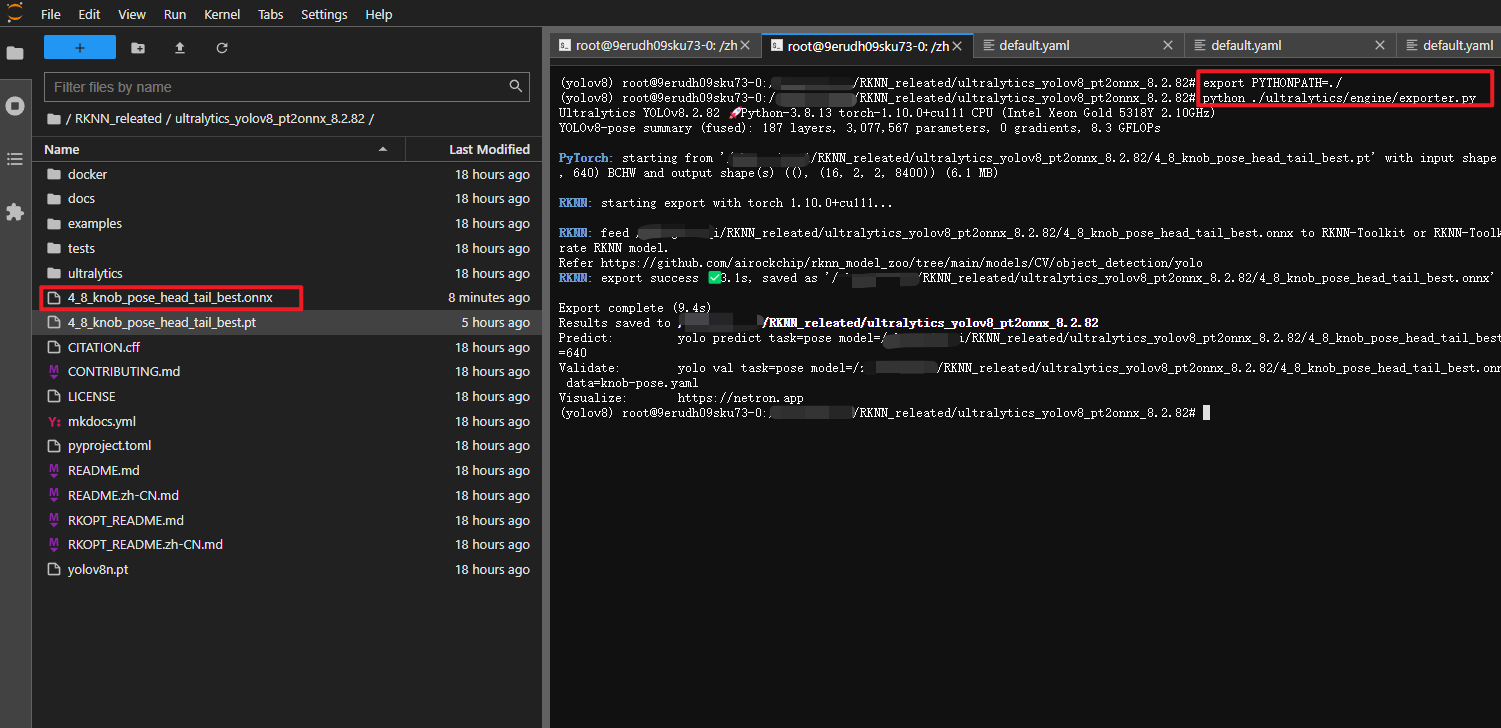
修改完default.yaml后,在终端输入:
export PYTHONPATH=./
python ./ultralytics/engine/exporter.py
执行完毕后,会生成 4_8_knob_pose_head_tail_best.onnx 模型,如下所示:
★★★
这里要着重说一下,如果你之前在配置yolov8的conda环境时,命令如下:pip install ultralytics,那么你的环境列表中应该有当前最新版本的ultralytics,输入conda list -n xxx,查询你现在环境中的ultralytics版本,博主此时的最新版本为8.3.112
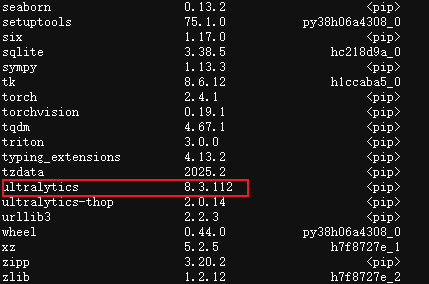
但是你在ultralytics_yolov8_pt2onnx_8.2.82文件夹下运行python ./ultralytics/engine/exporter.py时,终端应该会显示8.2.82版本:
 ,
,
这是合理的,因为在瑞芯微提供的ultralytics_yolov8中,他们使用的ultralytics即ultralytics文件夹是8.2.82的,而当前工作目录下的 ultralytics 8.2.82文件夹覆盖了已安装的包版本:
所以说,瑞芯微统一提供了一个使用8.2.82版本的ultralytics(并在此基础上做了微调)供模型转换。
得到onnx模型后,用netron工具打开,看输入输出是否正常:
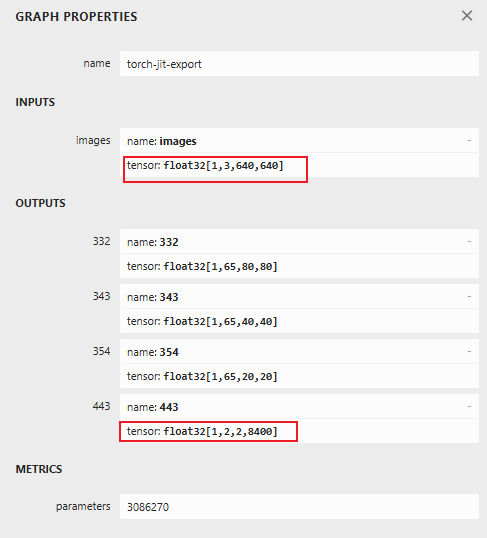
输入统一都是1×3×640×640,输出的话,前面三个大家都是统一的,即1×65×80×80,1×65×40×40,1×65×20×20,这是对应80×80、40×40、20×20大小的特征图,最后一个输出1×2×2×8400,每个人不一样,1为batchsize,2为关键点,2为x,y,8400为8400个anchor:80×80+40×40+20×20=8400。
以下是瑞芯微官方ONNX模型和自己转换的ONNX模型的对比:
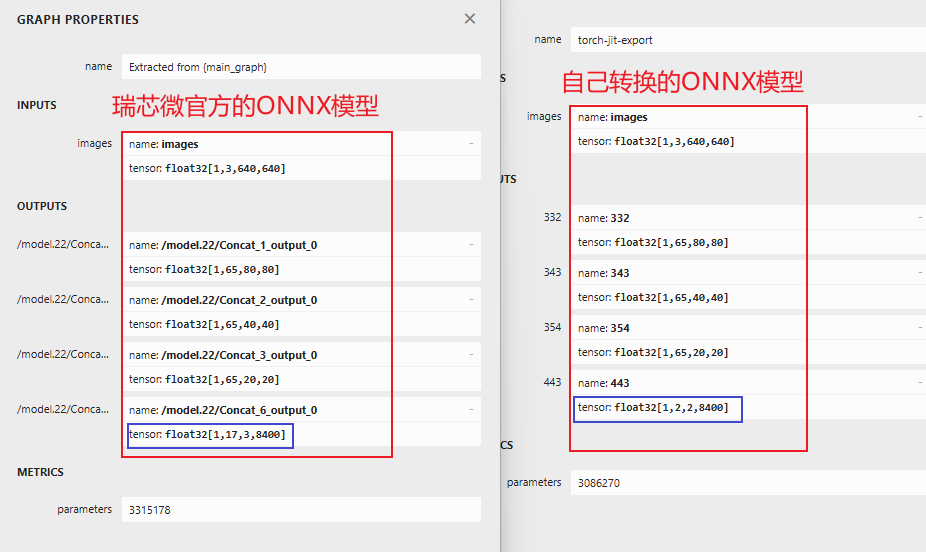
至于说为什么瑞芯微官方的ONNX模型输出的第三个参数为3,是因为在训练的时候,x,y,visible参数设置了3,而我设置为2:

,所以,如果大家为了能够直接适配我的板端部署代码,建议在训练的时候,也在yaml文件中设置为2
五、ONNX转RKNN
在进行这一步的时候,如果你是在云服务器上运行,请先确保你租的卡能支持RKNN的转换运行。博主是在自己的虚拟机中进行转换。
先安装转换环境
这里我们先conda create -n rknn210 python=3.8创建环境,创建完成如下所示:
现在需要用到rknn-toolkit2-2.1.0文件。
进入rknn-toolkit2-2.1.0\rknn-toolkit2-2.1.0\rknn-toolkit2\packages文件夹下,看到如下内容:
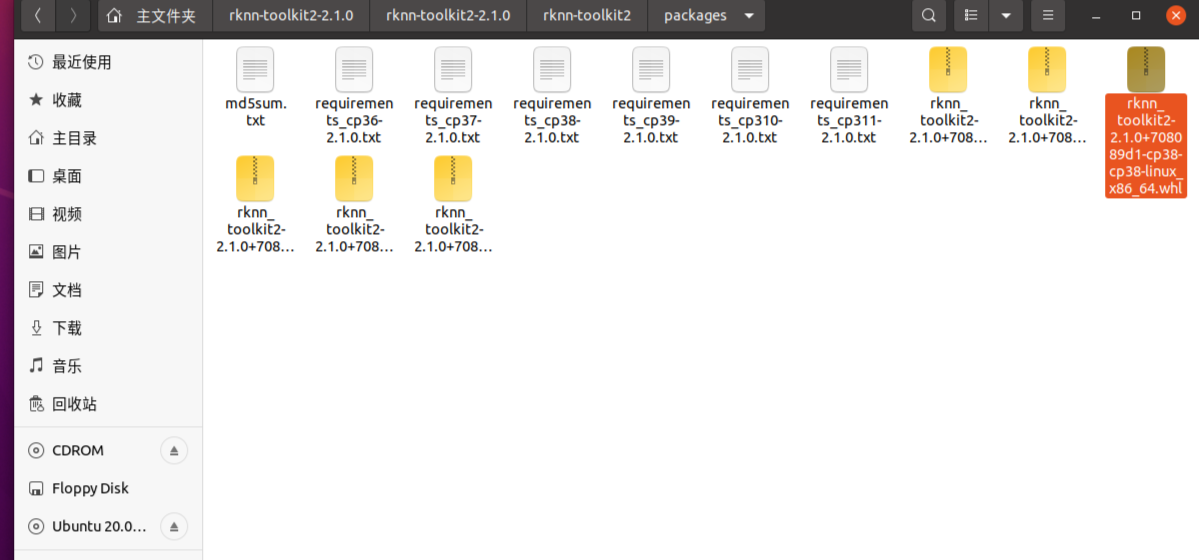
在终端激活环境,在终端输入pip install -r requirements_cp38-2.1.0.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
然后再输入pip install rknn_toolkit2-2.1.0+708089d1-cp38-cp38-linux_x86_64.whl
然后,我们的转rknn环境就配置完成了。
现在要进行模型转换,其实大家可以参考rknn_model_zoo-2.1.0\examples\yolov8_pose下的README指导进行转换:
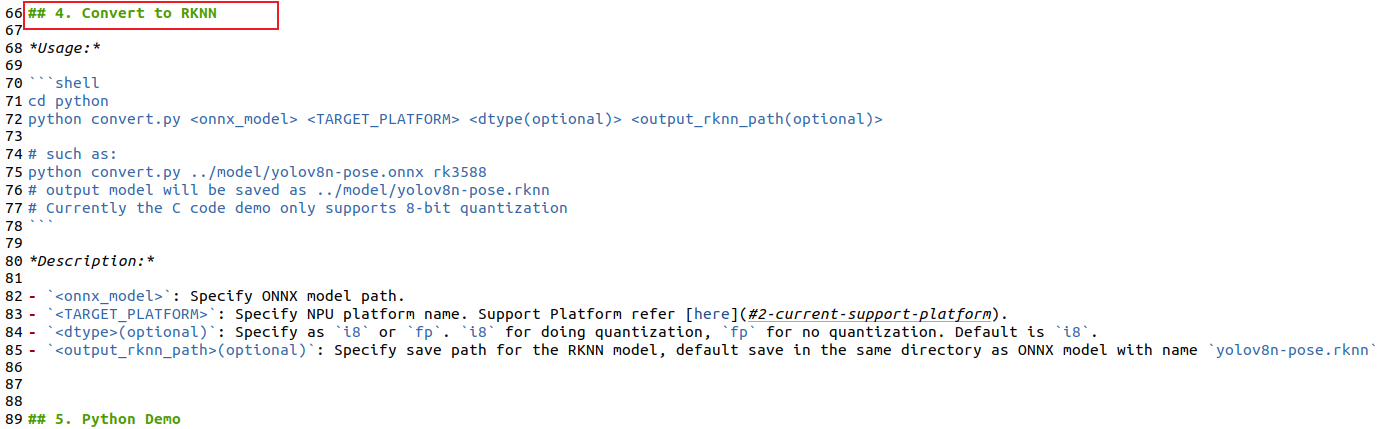
这里我也详细再说一遍转换流程:先进入rknn_model_zoo-2.1.0\examples\yolov8_pose\python文件夹,先打开convert.py,进行适配参数修改:
第一步:
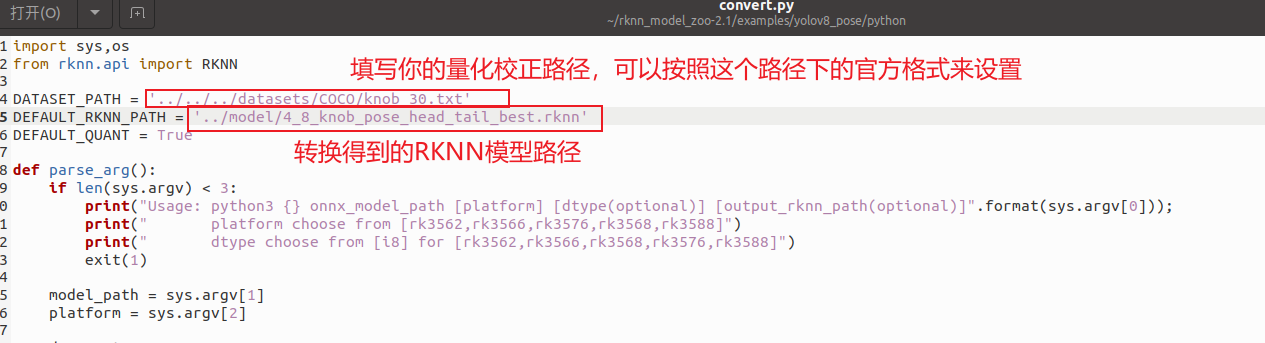
第二步:
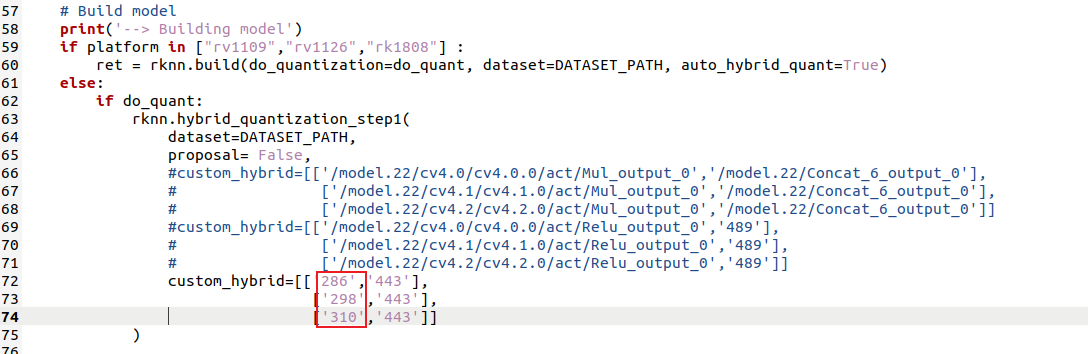
修改convert.py中的custom_hybrid :
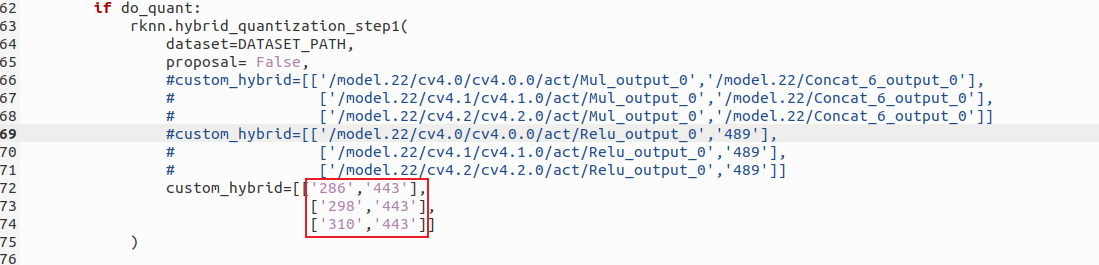
这一步极为重要,直接关系到你的模型在开发板上能否正常运行以及运行后的效果!
所谓custom_hybrid ,是指用于指定混合量化时的 自定义量化节点对。每个子列表包含两个节点:
第一个节点:需要量化的操作(如卷积层输出)。
第二个节点:该量化操作的后续节点(如 Concat 层的输入节点)
RKNN Toolkit 会根据这两个节点的连接关系,确定量化的范围。
下面来讲如何修改custom_hybrid:
用netron打开你的onnx模型,找到图示位置,即16×64×3×3Conv、16×128×3×3Conc、16×256×3×3Conv:,找到这几个Conv下的激活函数即Relu(因为我用的是Relu激活函数,如果你的是Silu或Mul激活函数,也无所谓,都会在此处显示,以此类推)
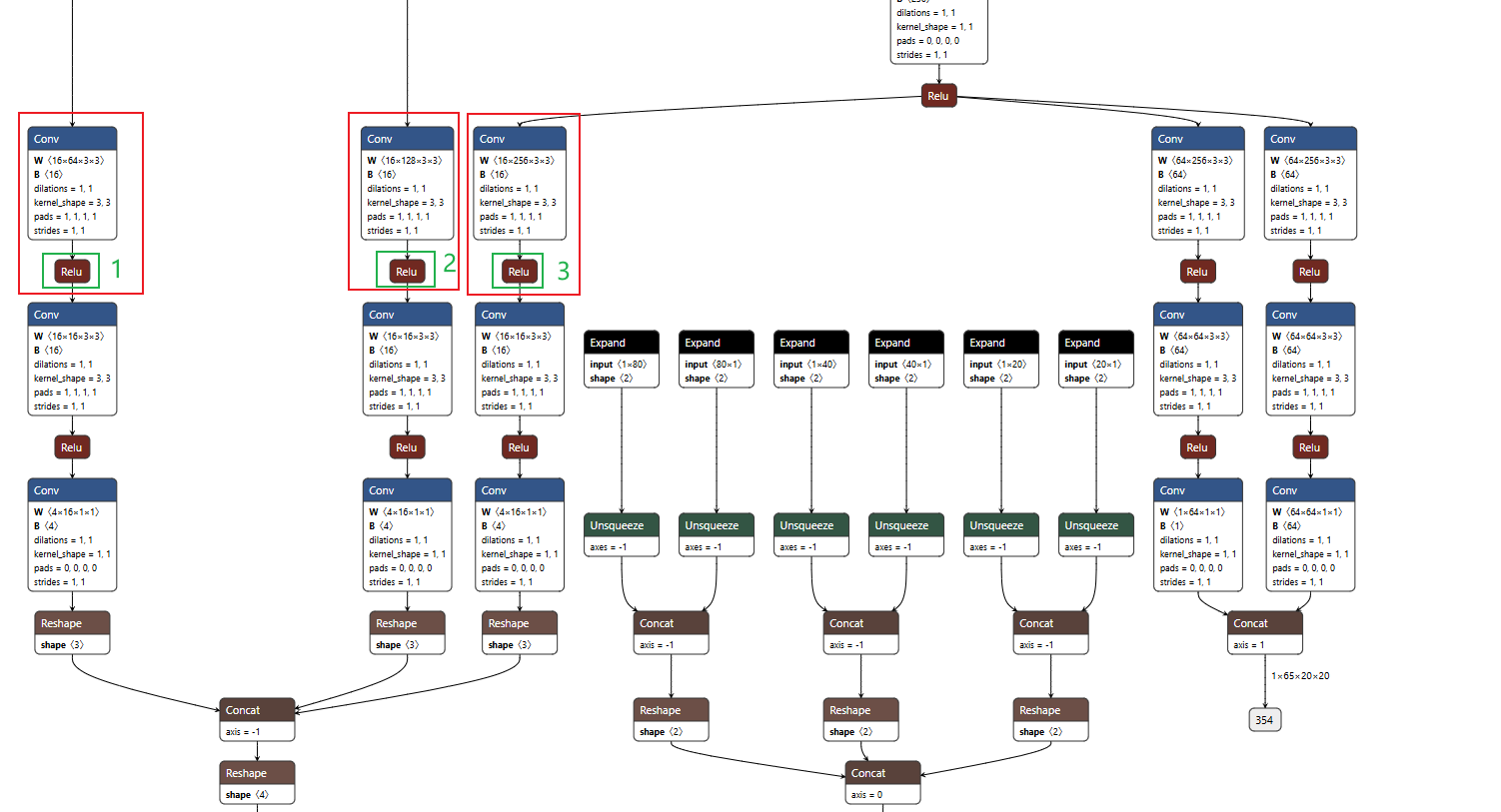
先点击图中1号Relu,如下所示:
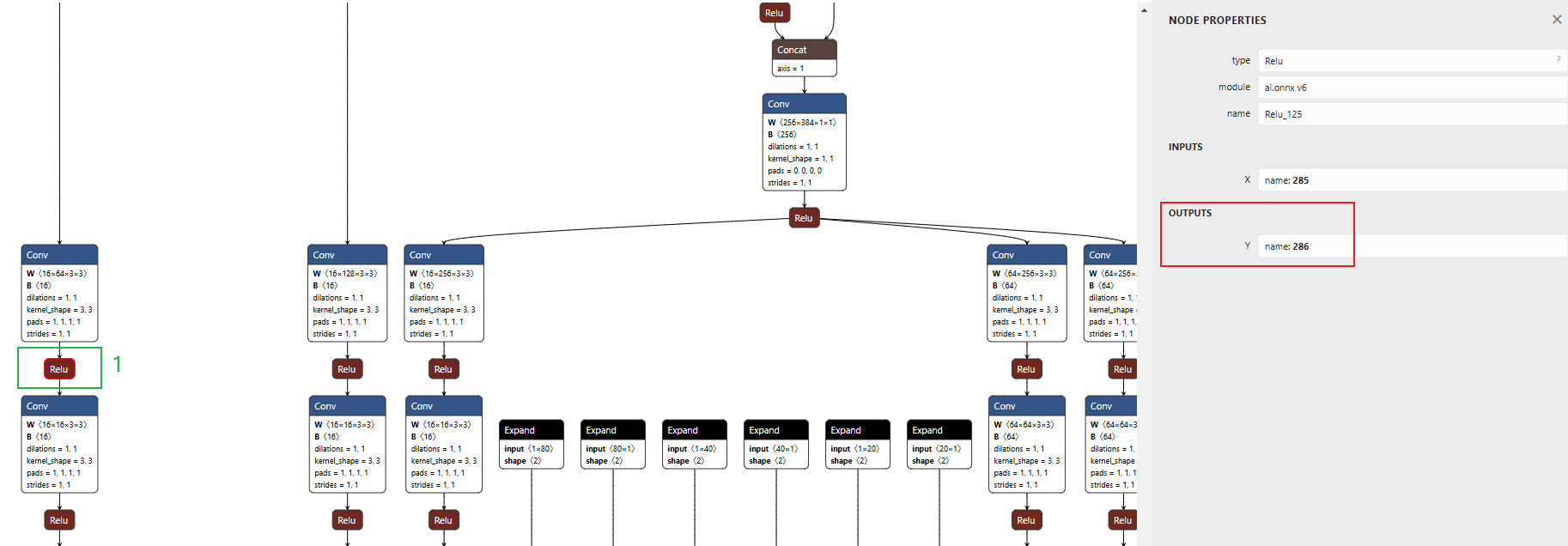
可以看到,1号Relu的输出名name是286,依次类推,我们看到2号和3号的输出名name是298和310
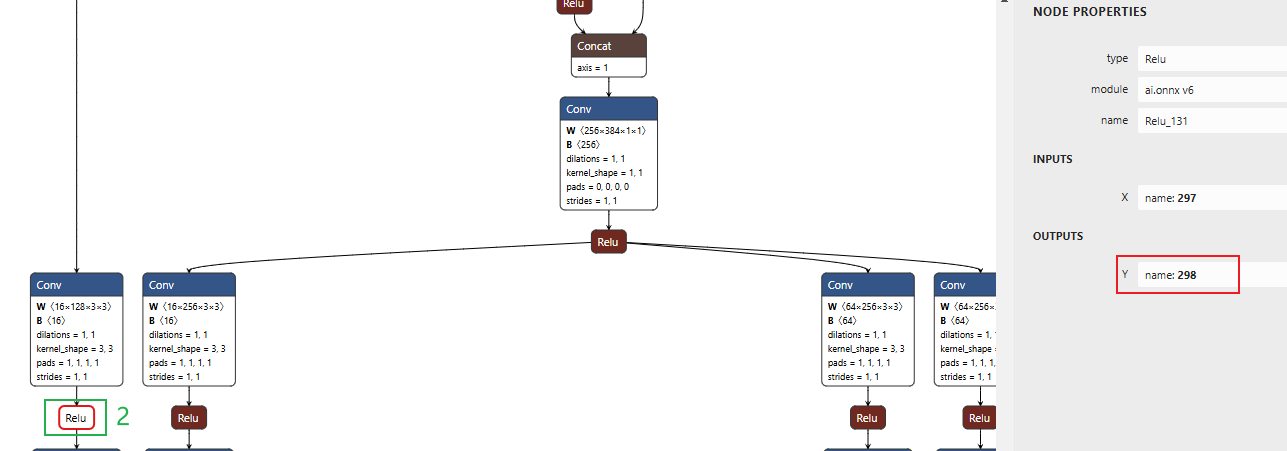
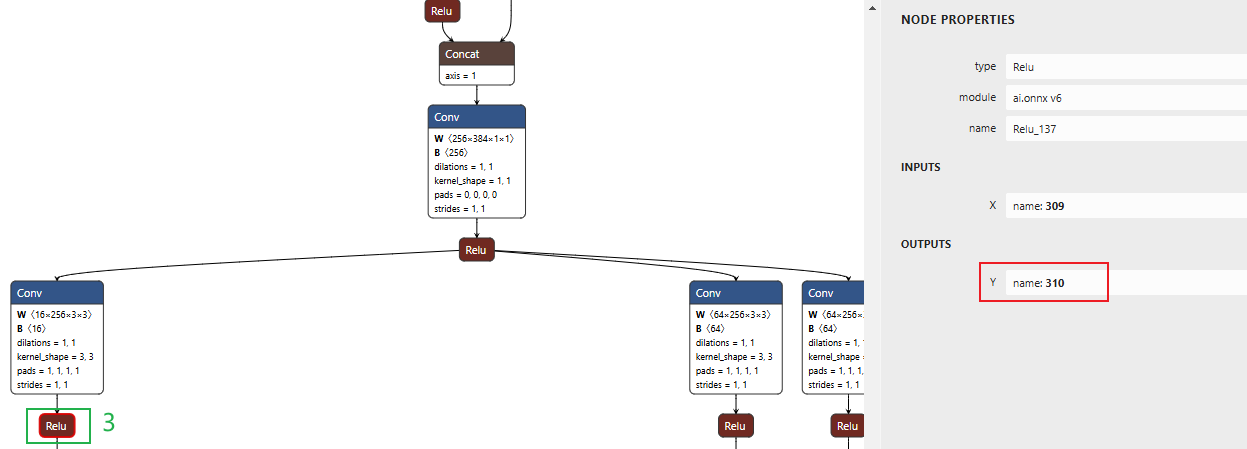 ,然后,把找到的286,298和310写到convert.py中的该位置处:
,然后,把找到的286,298和310写到convert.py中的该位置处:
最后,再用netron工具,打开onnx模型,查下最终的输出名:
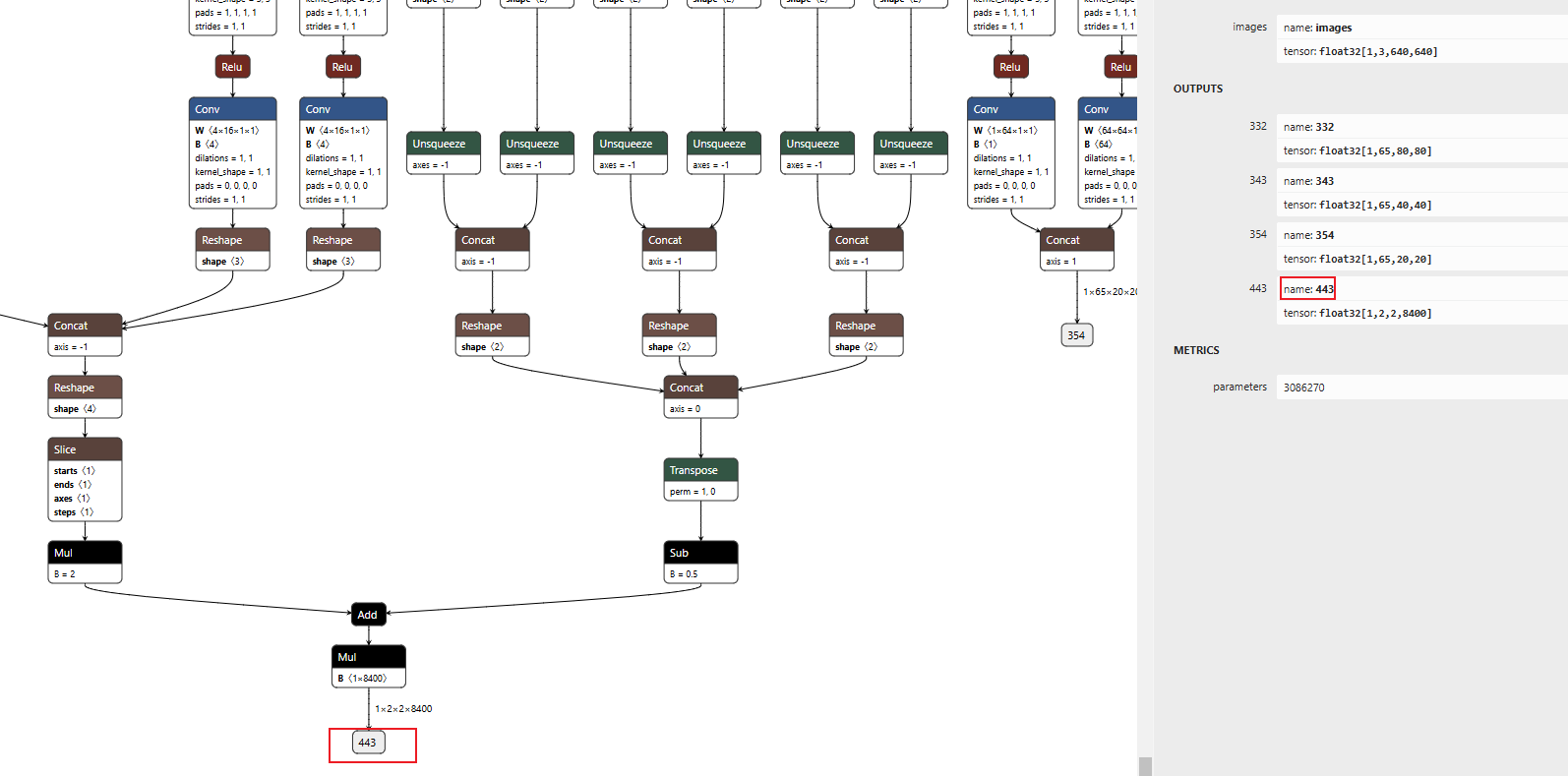
,可以看到,最终的输出是443,此时在convert.py的此处均修改为443:
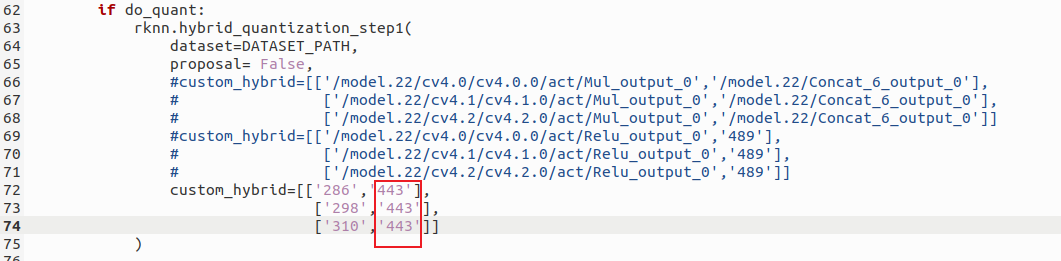
当然,此处完全根据你自己转出的ONNX模型中对应节点的名称来,有的是纯数字,有的是很长的地址如/model.22/cv4.2/cv4.2.0/act/Relu_output_0,都无所谓,只要找对位置即可。
修改完成后,在yolov8_pose/model下放自己的ONNX模型,然后在yolov8_pose/python下启动终端并启动环境,执行命令:python convert.py ../model/4_8_knob_pose_head_tail_best.onnx rk3588

结果如下:
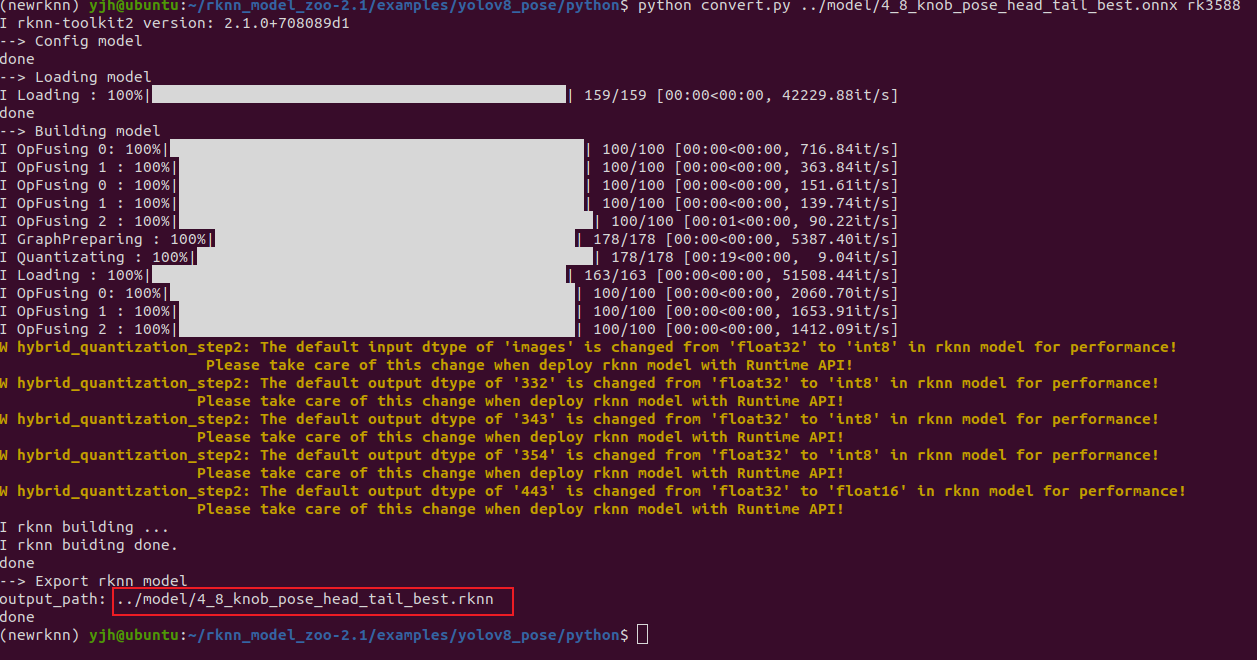
可以看到,我们的模型转换并量化成功。
转换后的rknn模型已保存在model文件夹下。
将该模型复制到win主机下,用netron打开,如下所示:
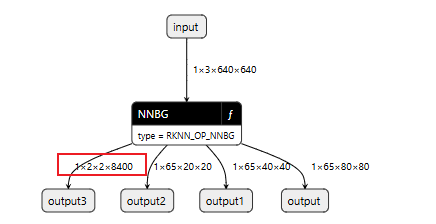
可以看到,我们的模型为1×2×2×8400,和瑞芯微官方ONNX模型转出的RKNN模型对比如下:

可以看到,唯一不同的是,我们的output3是1×2×2×8400,官方的output3是1×17×3×8400。
2和17:是每个目标的关键点数量
2和3:是x,y,visible,我训练时没有加visible,所以为2
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
拓展:
这里讲一下为什么要在convert.py中进行修改,而不是直接将py文件中的proposal设为True,如下所示:
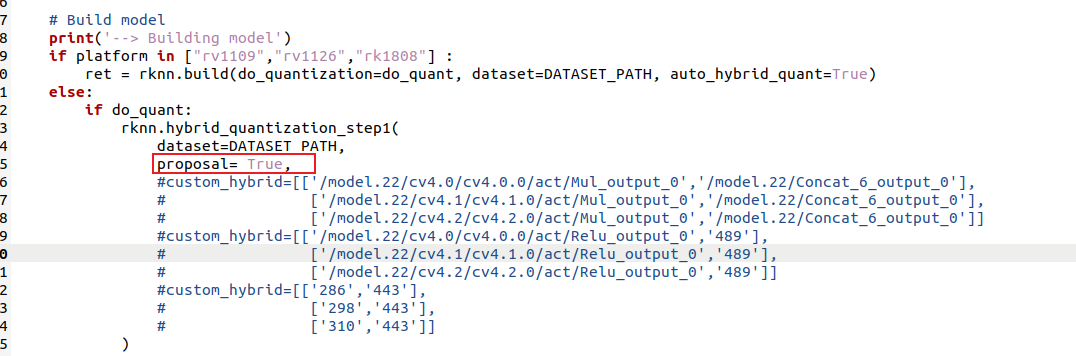
在我把proposal设为True后,表示启用自动建议混合量化节点,这个时候的量化由RKNN-Toolkit自动完成,此时执行转换命令,似乎也能成功,如下所示:
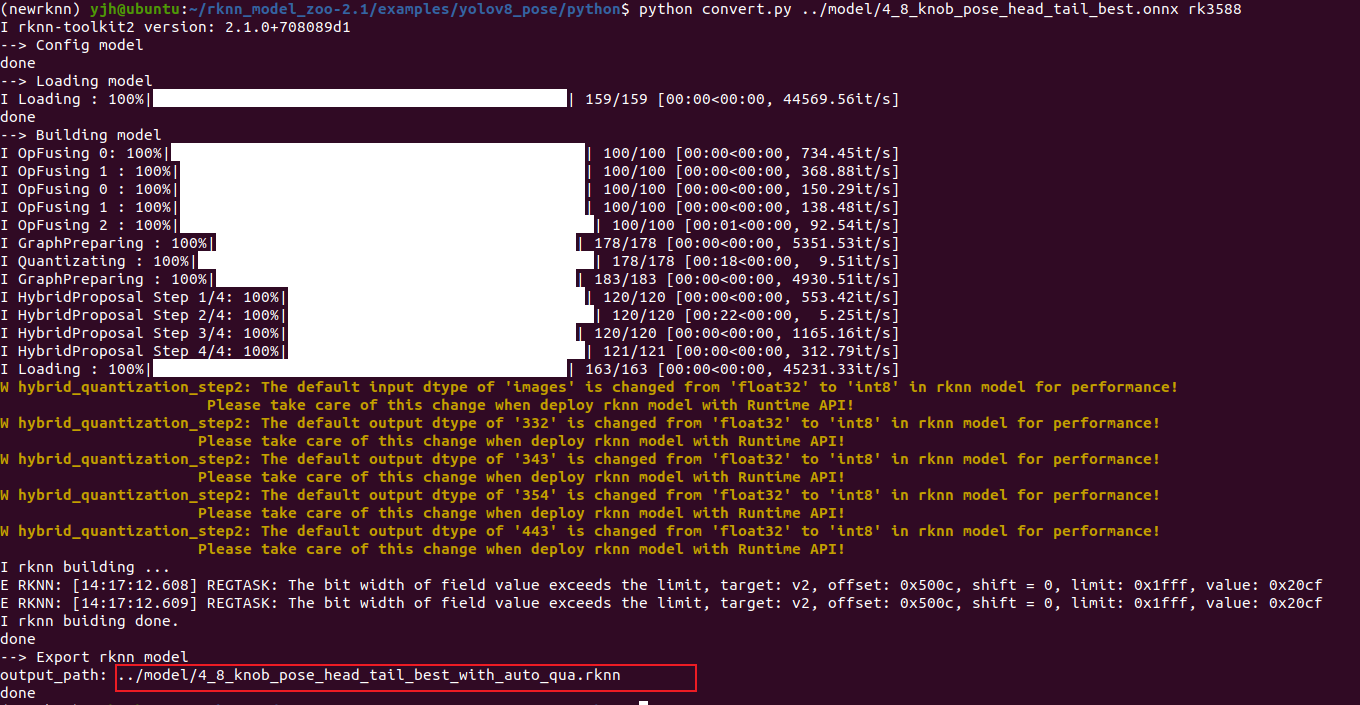
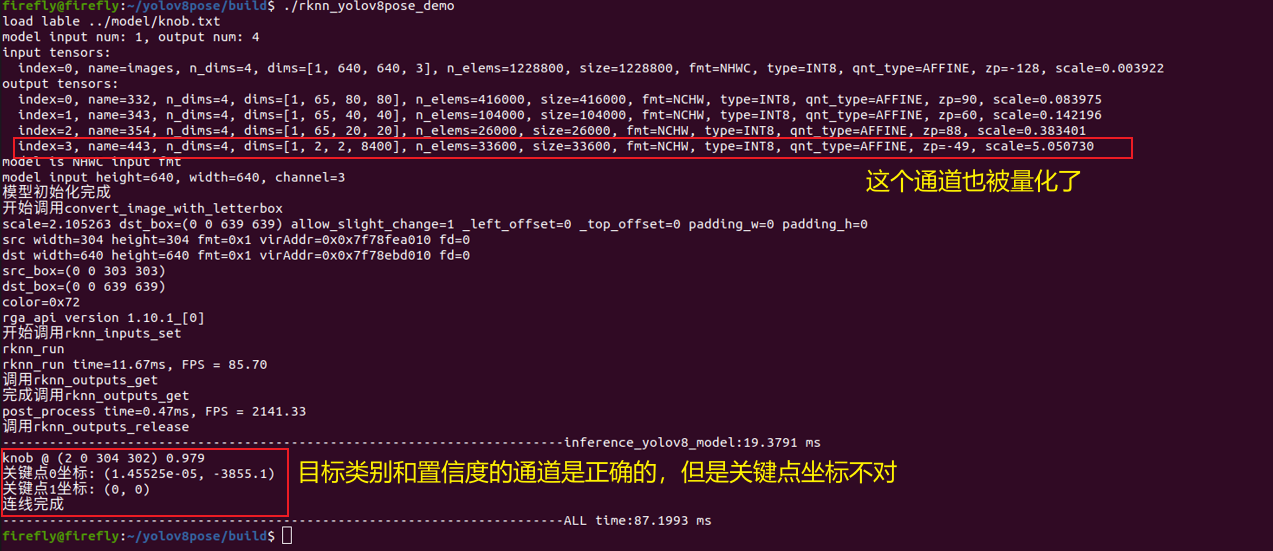
但如果我们去用这个rknn模型在开发板上推理时,终端会显示如下:
作为对比,同样的一张输入图片,用proposal设为False后修改custom_hybrid参数后转出的rknn模型再去推理,如下所示:
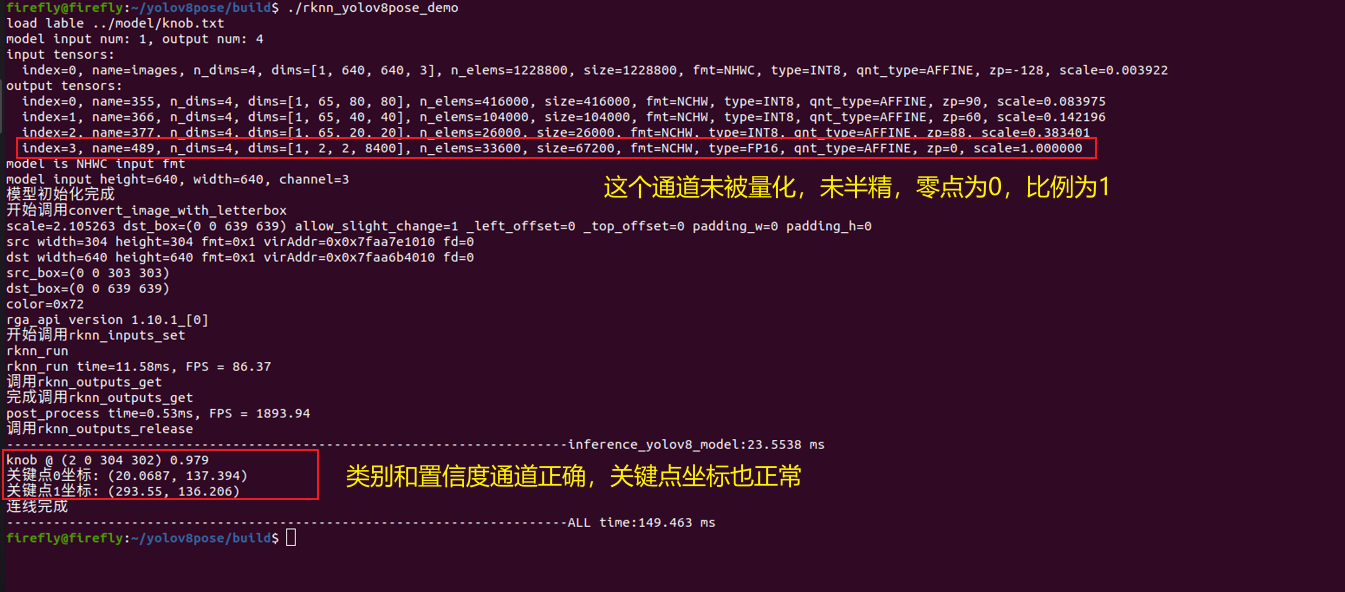
换言之,如果想用瑞芯微官方提供的推理、后处理代码,关键点输出通道是不能被量化的,因此选择自动量化后,所有通道均被量化,与代码不再适配,导致关键点坐标输出错误,因此方便起见,采用手动设置custom_hybrid参数方法。
各位大佬可以自己写下推理和后处理代码,以适配全自动量化的各个通道输出(狗头)
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
六、模型部署
如果前面流程都已实现,模型的结构也没问题的话,则可以进行最后一步:模型端侧部署。
我已经帮大家做好了所有的环境适配工作,科学上网后访问博主GitHub仓库:YOLOv8_RK3588_object_pose 进行简单的路径修改就即可编译运行。
重点:请大家举手之劳,帮我的仓库点个小星星
点了小星星的同学可以免费帮你解决转模型与部署过程中遇到的问题。
git clone后把项目复制到开发板上,按如下流程操作:
①:cd build,删除所有build文件夹下的内容
②:cd src 修改main.cc,修改main函数中的如下三个内容:

将这三个参数改成自己的绝对路径,
并根据自己的情况设置skeleton:

③:cd src 修改postprocess.cc下的txt标签的相对路径:
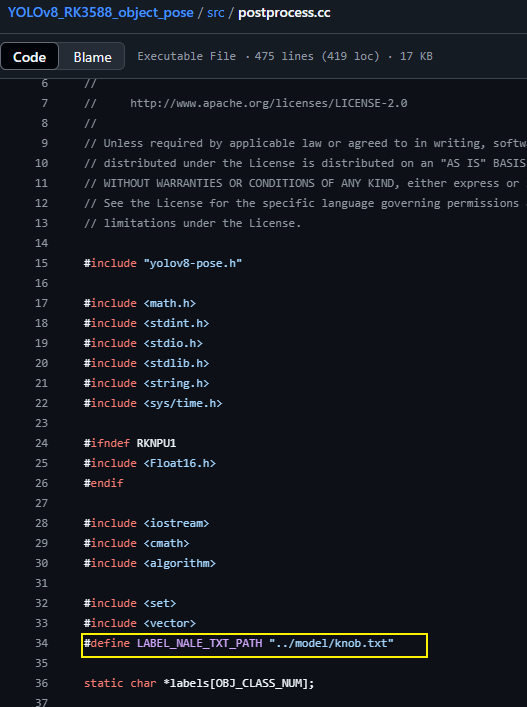
解释一下,这个标签路径中的内容如下所示:
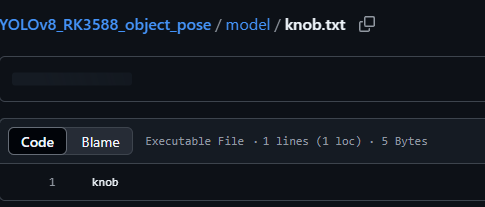
其实就是你在训练yolov8时在yaml配置文件中的类别名
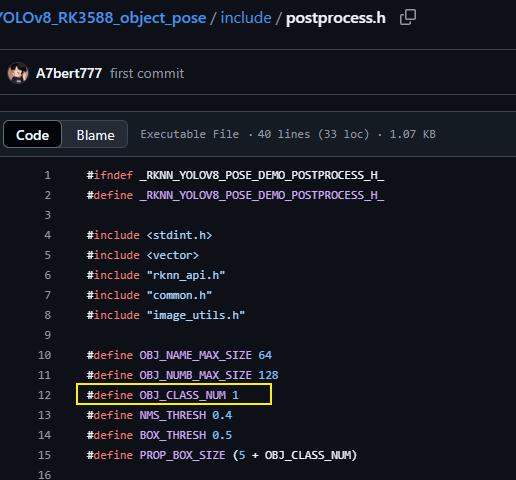
④修改include/postprocess.h 中的宏 OBJ_CLASS_NUM
⑤:把你之前训练好并已转成RKNN格式的模型放到YOLOv8_RK3588_object_pose/model文件夹下,然后把你要检测的所有图片都放到YOLOv8_RK3588_object_pose/inputimage下。
在运行程序后,生成的结果图片在YOLOv8_RK3588_object_pose/outputimage下
⑥:进入build文件夹进行编译
cd build
cmake ..
make
在build下生成可执行文件文件:rknn_yolov8pose_demo
在build路径下输入
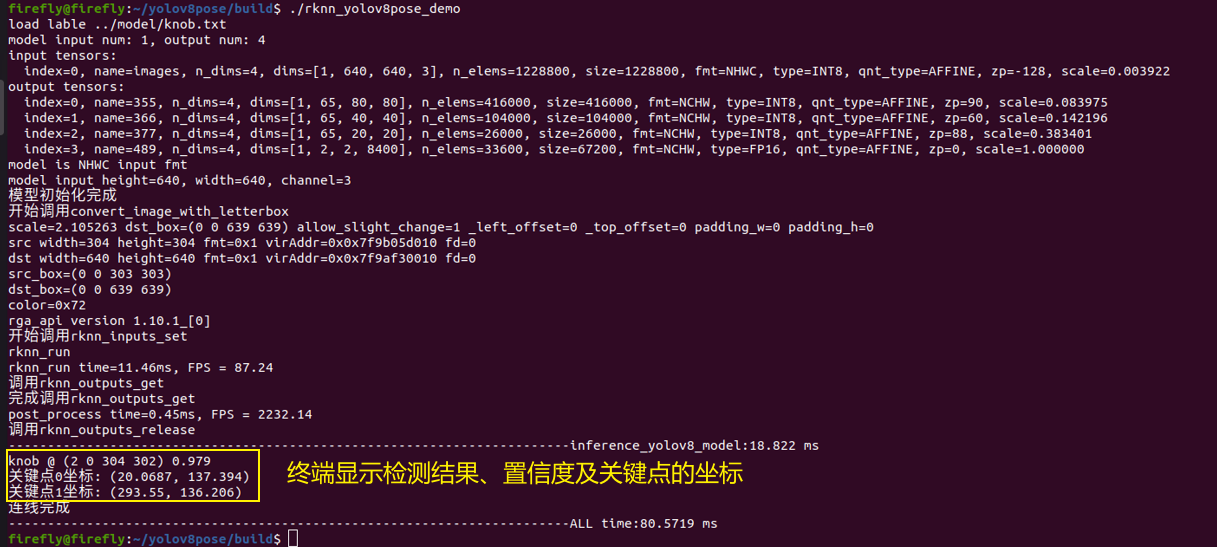
./rknn_yolov8pose_demo
运行结果如下所示:
原inputimage文件夹下的图片:

在执行完./rknn_yolov8pose_demo后在outputimage下的输出结果图片:
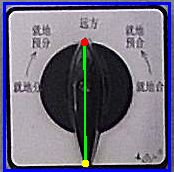
原inputimage文件夹下的图片:

在执行完./rknn_yolov8pose_demo后在outputimage下的输出结果图片:

注:由于我的检测结果几乎就是整个图片,所以蓝色的检测框和图片大小几乎一致,导致目标框左上角的目标类别和置信度看不到,不过没关系,可以在终端看到,得分非常高,接近100,关键点的位置检测也非常准。
上述即博主此次更新的YOLOv8-pose部署RK3588,包含PT转ONNX转RKNN的全流程步骤,欢迎交流!


















 1402
1402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









