






一、模型介绍
1、从几何角度:高斯分布是由多个高斯分布叠加而成的,运用加权平均

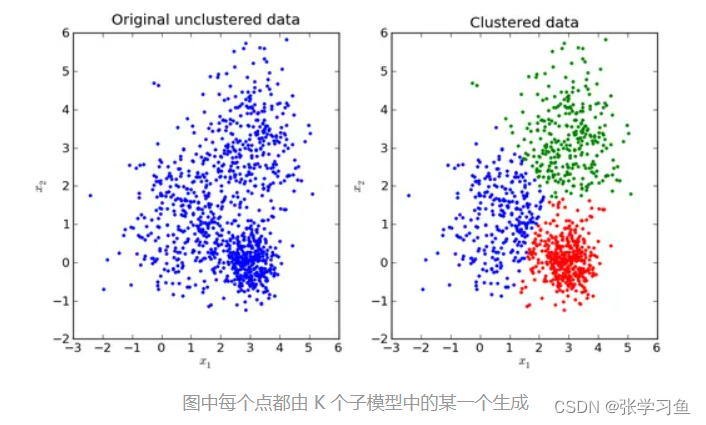

混合模型里面,有多个高斯分布,向上左图中,红绿蓝可以为三个不同的高斯分布,上右图有两个高斯分布,PS这些高斯分布都是重合的。一个x可以属于每个高斯分布,但它属于哪个高斯分布的概率是不同的,属于第k个高斯分布的概率为,它自己在这个高斯分布里面的概率为
;两个相乘,自然为这个x在这个混合模型里面的概率啦。

接下来的部分,就是要学习和
的参数,其中
就是
,用来确定单高斯模型的位置和幅度。
计算参数:
二、最大似然
对于单高斯模型,可以用最大似然法(Maximum likelihood)估算参数的值。
但是对于高斯混合模型不行(这个地方的具体数学运算不清楚)
三、EM算法求解
1、是无监督分类模型,没有使用点的类别来学习模型参数
2、EM算法中:
E步骤:用来预测每一个点属于不同类别的概率
M步骤:求极大,计算新一轮迭代的模型参数。用估计的分类来更新每一个高斯分布的平均值方差,以及当前类别的先验概率
重复以上两个步骤,指导分布收敛(M步骤不再作用)
3、初始化方案会影响分类结构,不同的初始化导出的结果不同
argmax是一种函数,是对函数求参数(集合)的函数。(详细求解步骤学完概率论再来)
结论:
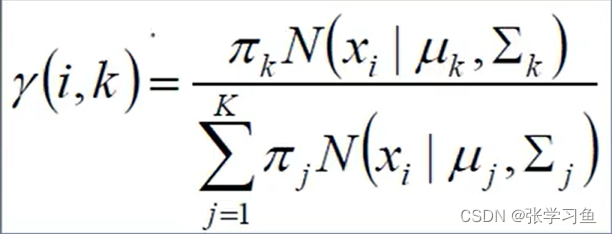

左边式子的意思是,第i号样本,属于第k个类别的概率;先设置,
和
,算出
后,就可以求
,完成一次对
的更新,同理对
和
进行更新,
和
是同一个意思,其中
是多参数的高斯模型,不止
的那种。
不断重复,上面这些值就都可以确定了。
其中(正态分布的值)是用下面的式子计算,对于参数不止
参数的高斯分布,用下下面的式子计算,其中
是协方差矩阵,表示有多个参数的意思。
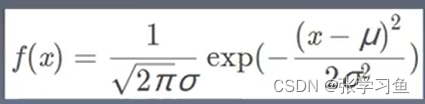
高斯模型(x为单变量)
给出任意x,就可以得到它出现的概率。
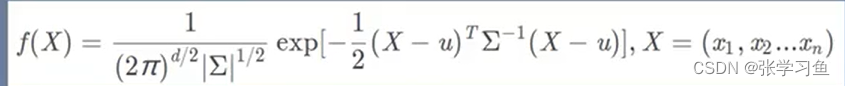
当X有多个特征,多变量,X就为矩阵了。同理也是向量,如
是
的均值。。。这样就可以把单变量模型转变为多变量的概率密度函数了
(问题:这些参数都是什么意思,为什么可以算出新值)
四、高斯混合模型原代码实现(两个代码方法)
二分类(两个高斯分布)
import numpy as np
import matplotlib.pyplot as pit
# 生成均值为1.71,标准差为0.056的数据
np.random.seed(0)
mu_m = 1.71 #期望
sigma_m = 0.056 #标准差
num_m = 10000 #数据个数为10000
rand_data_m = np.random.normal(mu_m,sigma_m,num_m) #生成数据
y_m = np.ones(num_m) #生成标签
# 生成均值为1.58,标准差为0.056的数据
np.random.seed(0)
mu_w = 1.58 #期望
sigma_w = 0.051 #标准差
num_w = 10000 #数据个数为10000
rand_data_w = np.random.normal(mu_w,sigma_w,num_w) #生成数据
y_w = np.zeros(num_w) #生成标签
# 把两组数据整合
data = np.append(rand_data_m,rand_data_w)
data = data.reshape(-1,1)
y = np.append(y_m,y_w)
print(data)
print(y)
# 迭代数据
# 引入多变量的正态分布multivariate_normal函数,用于计算
from scipy.stats import multivariate_normal
num_iter = 1000 # 迭代次数
n,d = data.shape
# 初始化参数,随机初始化
# 此处为二分类才会这样,若有多个高斯分布,那就不能写死,用循环从1-k,mu1到muk,同理sigma和pi,但sklearn可以直接完成这个工作,所以没必要写循环
mu1 = data.min(axis = 0)
mu2 = data.max(axis = 0)
sigma1 = np.identity(d) # sigma是一个数,而且本实验是单变量;sigma在多变量的情况下是一个矩阵,也许就不能用identity了
sigma2 = np.identity(d)
pi = 0.5
for i in range(num_iter):
# print('in')
# 计算gamma
# 此处为二分类才会这样,若有多个高斯分布,那就不能写死,用循环从1-k,mu1到muk,同理sigma和pi
norm1 = multivariate_normal(mu1,sigma1)
norm2 = multivariate_normal(mu2,sigma2)
tau1 = pi*norm1.pdf(data) # ? # pi,乘以该数分类到男生高斯分布的概率
tau2 = (1-pi)*norm2.pdf(data)
gamma = tau1/(tau1+tau2) # 指的是,几号数据的第几个类别,是一个向量
# 计算mu1
mu1 = np.dot(gamma,data)/np.sum(gamma)
# 计算mu2
mu2 = np.dot(1-gamma,data)/np.sum(1-gamma)
# 计算sigma1
sigma1 = np.dot(gamma*(data-mu1).T,data-mu1 )/np.sum(gamma) # 为了避免维度错误,要么gamma*(data-mu1).T先乘,要么(data-mu1).T*,data-mu1,总之要先乘(data-mu1).T
#计算sigma2
sigma2 = np.dot((1-gamma)*(data-mu2).T,data-mu2)/np.sum(1-gamma)
# 计算pi
pi = np.sum(gamma)/n
print('类别概率:\t',pi)
print('均值:\t',mu1,mu2)
print('方差:\n',sigma1,'\n\n',sigma2,'\n')多个高斯分布,运用Skearn实现高斯混合模型
这个好用一点,可用于多个高斯分布,
但问题:如果这个类别的高斯分布,不止 怎么办?作一个多维的矩阵,放到GaussianMixture里面?
怎么办?作一个多维的矩阵,放到GaussianMixture里面?
找到了Sklearn的文档,感觉写的很好,有一点原理:https://www.sklearncn.cn/20/
但是里面的例子阅读起来有困难,以后有空再回来:GMM covariances — scikit-learn 1.2.0 documentation
多个高斯分布,运用Skearn实现高斯混合模型
解释:给它已知的混合的数据data,这些数据分别属于多个高斯分布,但是它们混杂再来一起,现在就是要看,给你这些数据的信息,看它属于哪个高斯分布。

具体过程就是,你先告诉它,有几个高斯分布,然后通过sklearn把这几个高斯分布迭代训练出来(上图)。最后用predict预测,就能知道这组数据里,每一个数据属于哪个高斯分布了(下图)。

注意:y(y_m和y_w合并而成)是我们在这道例题里已知的量,实际运用上是不知道的。我们的目的就是为了得到y_hat,预测的值。
y_hat是由sklearn.predict出来的,它的标签默认就是0、1,它的0和1,与我们在生成数据时,对y_m和y_w规定标签为0、1无关,这里把两者设置一样,只是为了作对比。
import numpy as np
import matplotlib.pyplot as pit
import sklearn
# 生成数据一
np.random.seed(0)
mu_m = 1.71 #期望
sigma_m = 0.056 #标准差
num_m = 10000 #数据个数为10000
rand_data_m = np.random.normal(mu_m,sigma_m,num_m) #生成数据
y_m = np.ones(num_m) #生成标签.标签为1,就是数据1里的数据
# print(rand_data_m)
# 生成数据二
np.random.seed(0)
mu_w = 1.58 #期望
sigma_w = 0.051 #标准差
num_w = 10000 #数据个数为10000
rand_data_w = np.random.normal(mu_w,sigma_w,num_w) #生成数据
y_w = np.zeros(num_w) #生成标签,标签为2,就是数据2里的数据
# print(y_w)
# 两个数据合并
data = np.append(rand_data_m,rand_data_w)
print(data)
data = data.reshape(-1,1)
y = np.append(y_m,y_w)
# print(data)
# print(y)
# 更新
from sklearn.mixture import GaussianMixture
g = GaussianMixture(n_components = 2,covariance_type = 'full',tol = 1e-6,max_iter = 1000) # 主要看n_components(多少种分类)和max_iter(迭代次数)这两个参数
g.fit(data) # 用返回的数据g,fit一下data,fit后就会训练
print('类别概率:\t',g.weights_[1])
print('类别概率:\t',g.weights_[0])
print('均值:\t\n',g.means_,'\n') #输出均值
print('方差:\n',g.covariances_,'\n')
# 用于预测
from sklearn.metrics import accuracy_score
y_hat = g.predict(data) # 对聚完类的数据进行预测,预测完返回预测结果
print(type(y_hat))
print(y_hat)
print(accuracy_score(y,y_hat)) # 与实际结果进行比较,看看精确度能达到多少学习对象:
机器学习-白板推导系列(十)-EM算法(Expectation Maximization)_哔哩哔哩_bilibili统计模型(3)—EM算法_哔哩哔哩_bilibili
【07-11-1高斯混合模型原生代码实现】 https://www.bilibili.com/video/BV1M94y1R7VY/?share_source=copy_web&vd_source=98fbab4e0ff3ef4e18cd477db479634d















 4351
4351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









