









1.背景
1.类似于青出于蓝而胜于蓝,故事可以挑战别那么大,出于蓝而近似蓝就好了
2.看似是来自于同个类型,但是是两个类型
3.A强模型,B模型效果差,让B向A学习,看看人家咋学的
4.但是同时B模型也不能只向A模型(强模型)学,也得学学标准答案(老大也可能出错)
2.什么是蒸馏
1.现在效果好的都基本上是大模型,设备和环境资源都好,大模型一般都效果好
2.但是缺点是:应用可能麻烦点,比较耗费资源,可能下游任务设备一般般,那咋整
3.那我们就得用小一点的模呗,比如resnet152用不了那咱们就用resnet18
4.但是现在咱们最终想模型尽量小,但是效果也要接近大一点的模型,既要用小的18层的也要让他效果尽可能进阶152的.
5.可解释性方面,目前无法证明。
6.模型参数量越大,效果一定越好吗?不一定,越来越平稳的曲线,有上限
7.模型的参数量相同,训练策略不同,得到的结果也可能完全不同
8.那么我们就得想想能不能利用点不同的训练策略让咱们模型既小又好?
3.蒸馏需要的内容
1.类似于以物体检测的例子
T模型生成一些伪标签,然后把这些标签交给S模型来进行学习
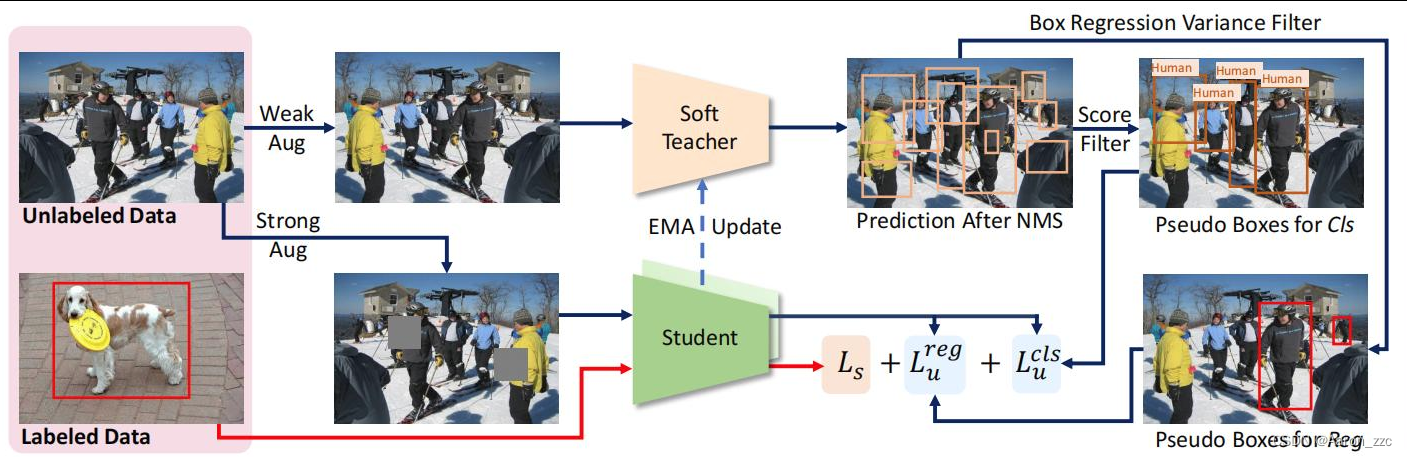
4.蒸馏要学什么?
1.我们也需要有俩模型(一大一小),可以用不同层数,甚至完全不同,比如resnet不同层数,yolo中s m l x,也可以yolo和mask-rcnn(理论可行)
2.其中大的模型叫T,它是训练好的,效果也挺好的,然后给它冻住
3.小的模型叫S,它是要来训练的,得让它学到T里面的知识,尽可能接近T
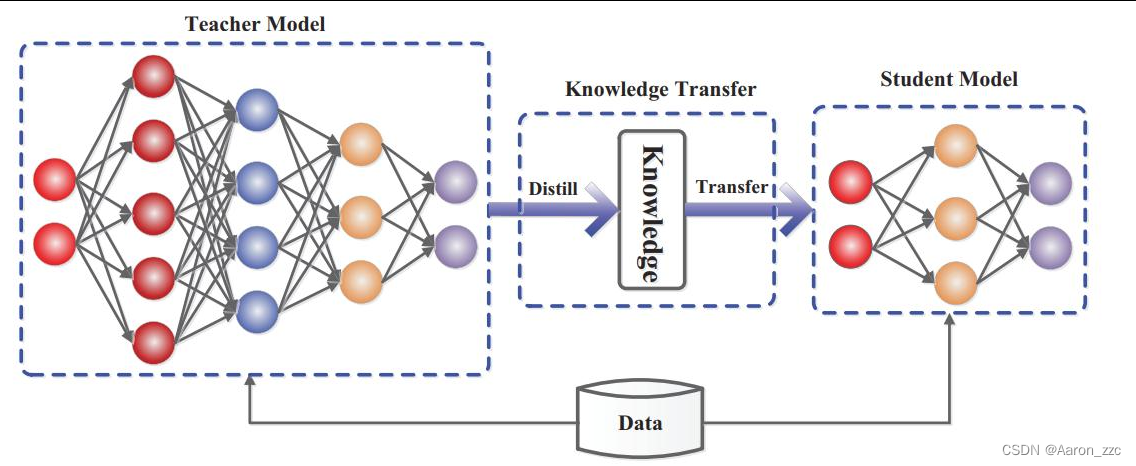
5.基本思想
类似于Teacher把会的东西通过一种表现形式交给student
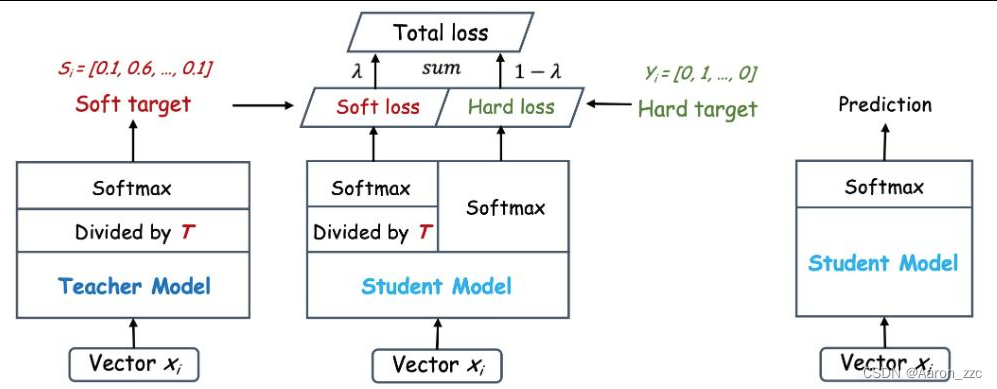
6.那么蒸馏要学什么呢?
T模型教S学的不是最终的一个结果,而是解题过程,也就相当于分布
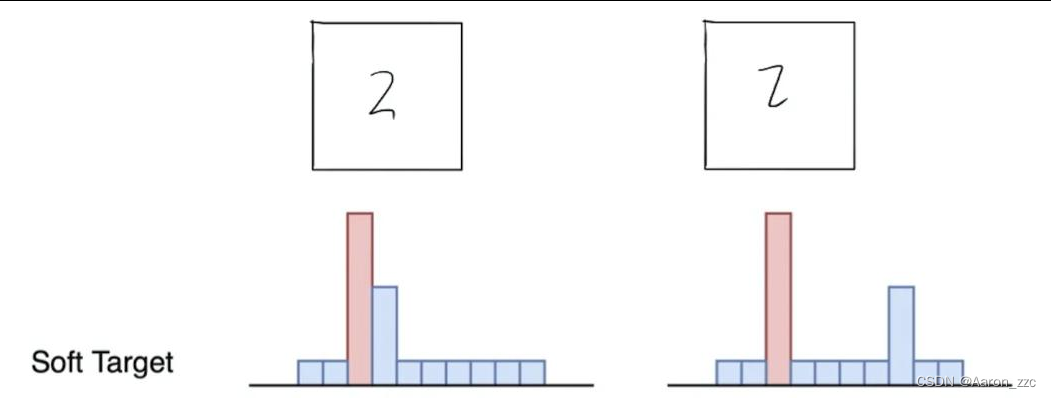
7.那么蒸馏要学什么呢?
左边的2更像3,右边的2更像7,这时候得让模型知道像谁,但是是谁
类似于我打碎东西不听话,回来揍我一顿就hard,给我讲别人家孩子咋咋滴就soft)
 Temperature的作用
Temperature的作用
1.温度就是说对预测结果进行概率重新设计
2.默认温度为1就相当于还是softmax
3.温度越高相当于多样性越丰富(雨露均沾)
4.温度越低相当于越希望得到最准的那个

8. 知识蒸馏的作用
1.不仅可以应用于结果上
FeatureBased就是加在特征上,但是一般还需要通过额外卷积或者FC
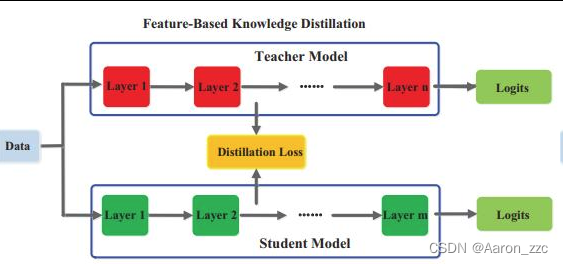
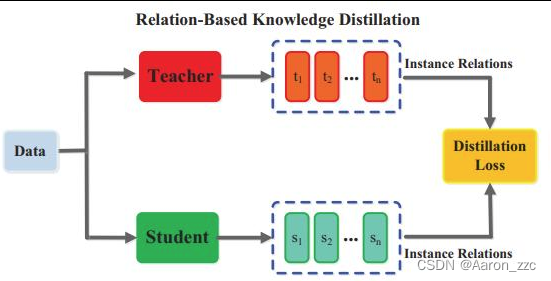
RelationBased就类似对比学习,Batch里面兄弟几个之间的差异也要类似
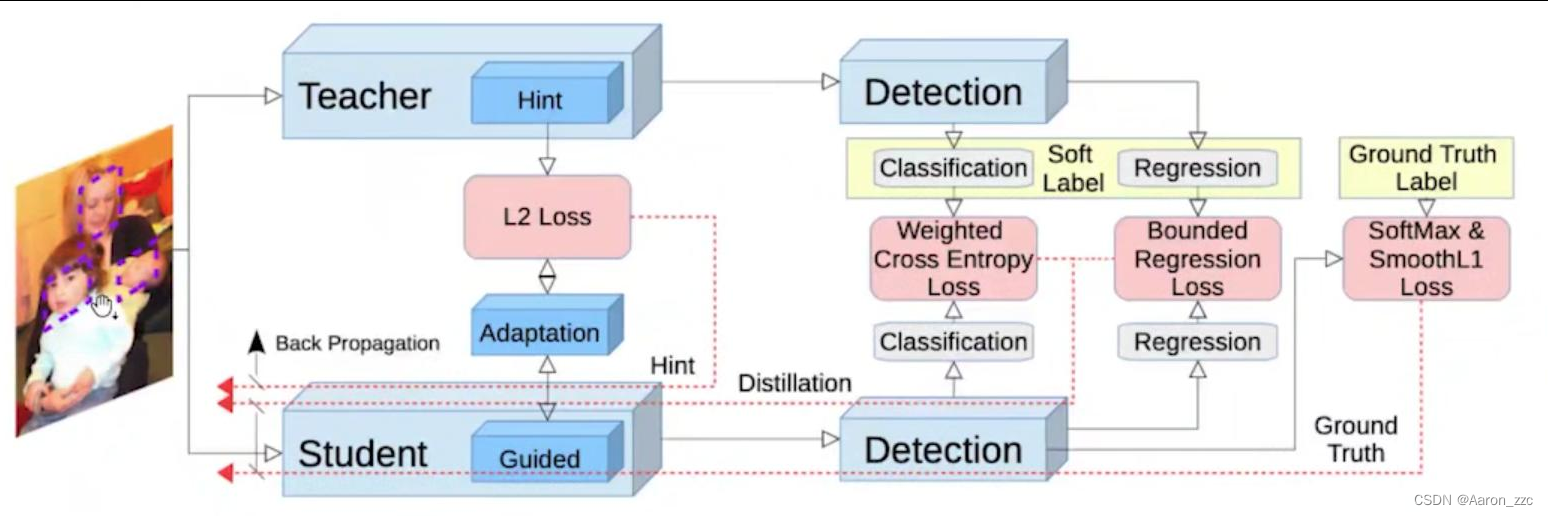
2.在物体检测领域应用
1.Backbone上要尽可能一致,分类和回归预测结果也要类似
2.其实类似半监督任务,T输出伪标签,让S来进行学习
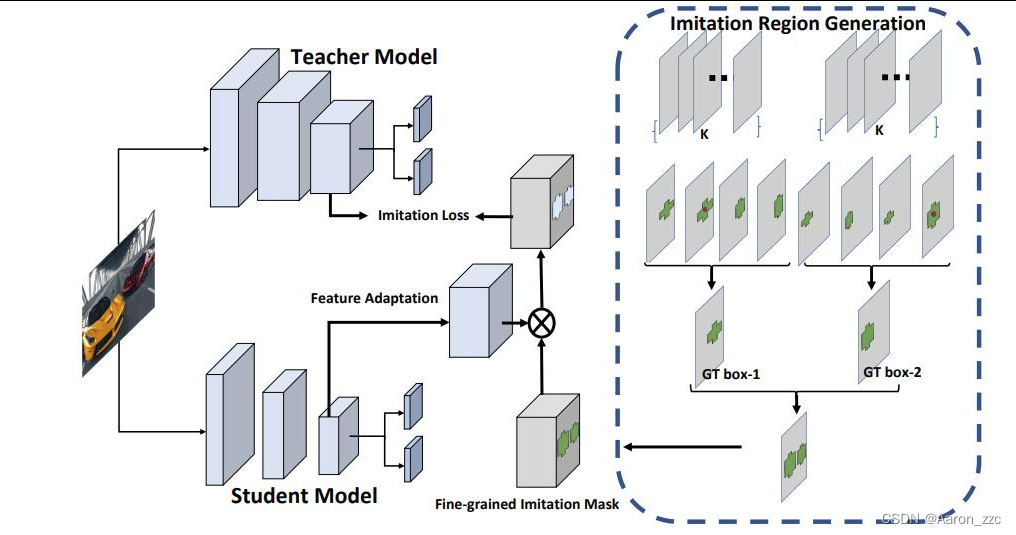
 3.backbone如何做的更好?
3.backbone如何做的更好?
(1)设计MASK机制区别对待
只取前景区域来进行计算
相当于正样本Anchor参与
 (2)只考虑前景有点不太合适,能不能对背景进行加权呢?(以及正负样本)
(2)只考虑前景有点不太合适,能不能对背景进行加权呢?(以及正负样本)
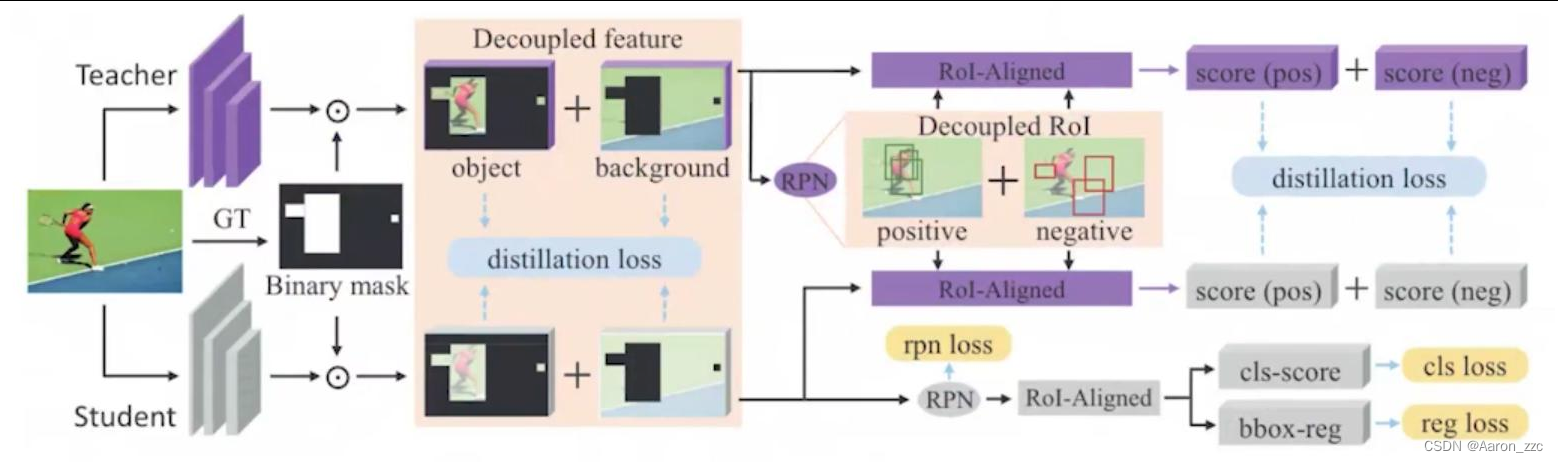 (3)重点区域不应该只考虑前背景
(3)重点区域不应该只考虑前背景
差异的地方才是空点考虑的
同样设计MASK机制
这回MASK重点在结果差异上
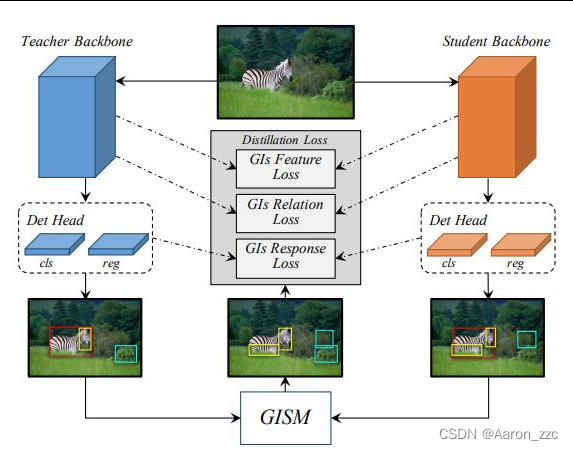 (4)黑箱操作,一顿设计一定对吗?
(4)黑箱操作,一顿设计一定对吗?
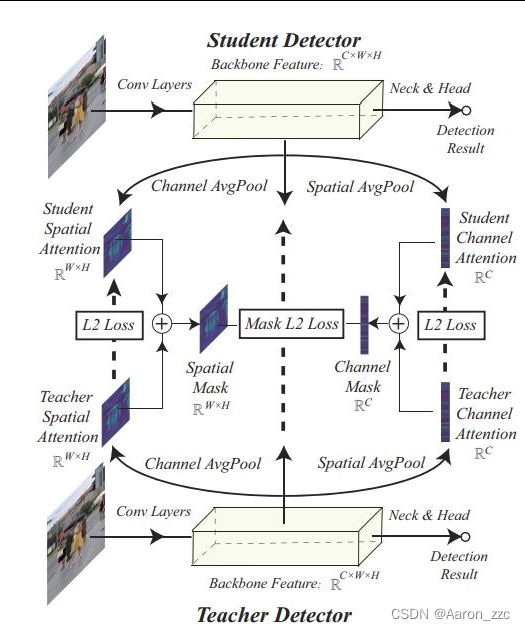
把mask这东西交给Attention来做吧
首先空间和通道维度计算权重,蒸馏下
再将mask结果应用到特征LOSS计算上
9.拓展分析-多T RL
不一定是一对一,可以是多个对一个
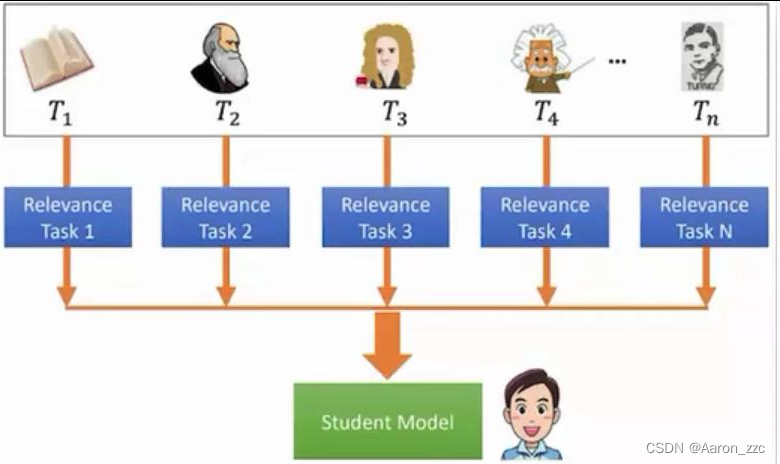
那么,
9.1如何选择不同阶段的T模型呢?设计权重?如何融合呢?
大模型上效果好的,你小模型一定能学的明白吗?
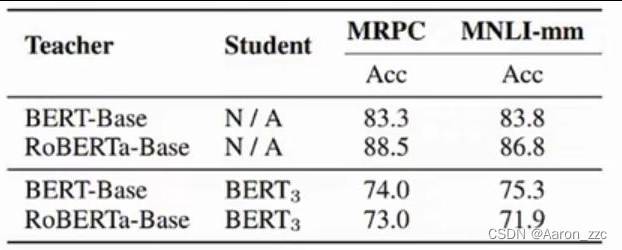
可能在模型学习的过程中也得根据S模型的学习情况来选择路线
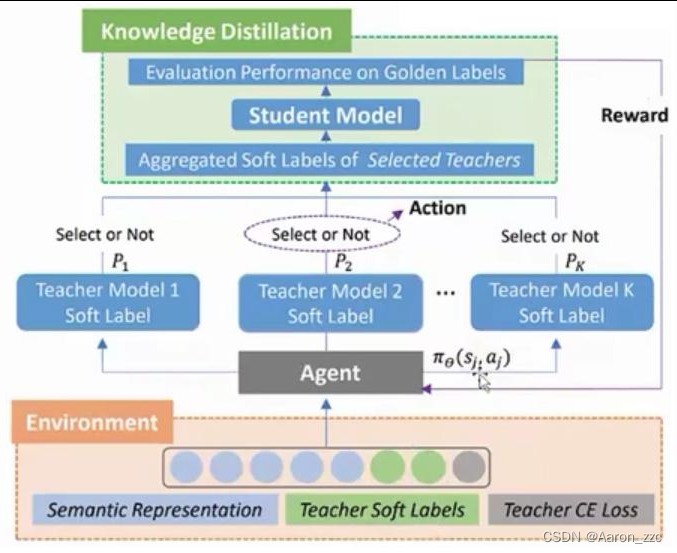
9.2
Agent来学习如何选择策略(老师)
Action中0/1就是不选/选择
根据选择情况来让S模型去学
将S的评估结果当作奖励值反馈
10.拓展分析-解耦
你现在喜欢干啥,玩新游戏?认识新朋友?学一项新技术?
之前旧的技术哪个吸引你了最近?之前的V7的make vgg great again
那蒸馏这么多新技术,它也想make谁谁谁great一下子?还真有
咱们刚才都说了结果上(logits)算损失不如特征层面上算损失,难道。。。拓展分析-解耦
T要教给S两件事:1.这件事难度有多大 2.啥导致了这件事难(错误分布)
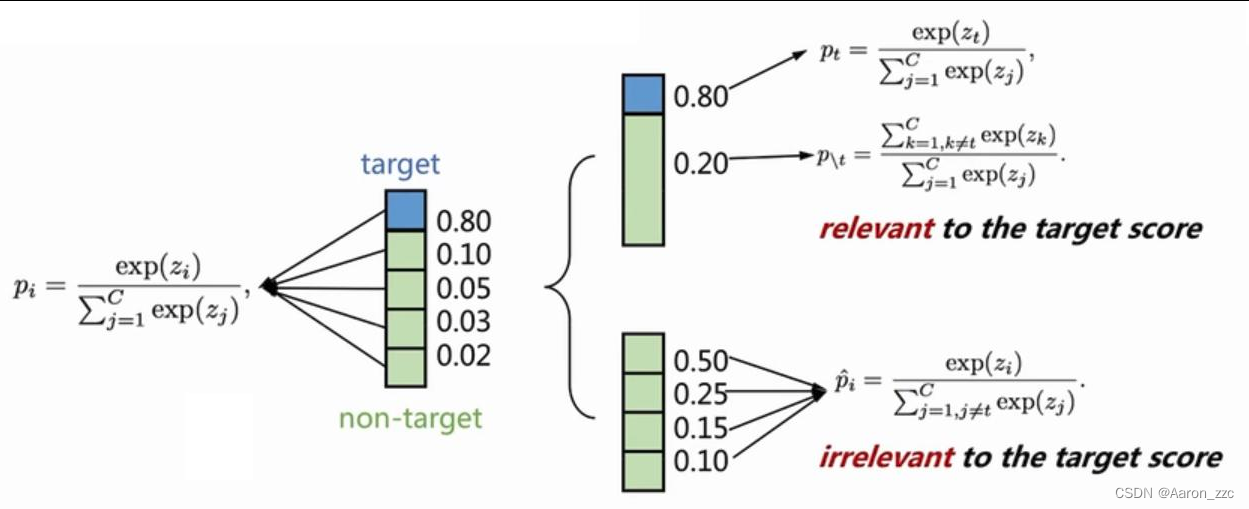 TCKD:Target Class KD(例如左图0.99,右图0.70);NC:Non-target Class
TCKD:Target Class KD(例如左图0.99,右图0.70);NC:Non-target Class
 2.实验跑出来得出结论,对TCKD和NCKD 添加的效果对比,
2.实验跑出来得出结论,对TCKD和NCKD 添加的效果对比,
其中TCKD是置信度,NCKD是错误分布
看起来应该是TCKD来捣乱的
基本结果就是他俩一起用可能还不如一个
他们之间存在着啥矛盾?能不能调节下
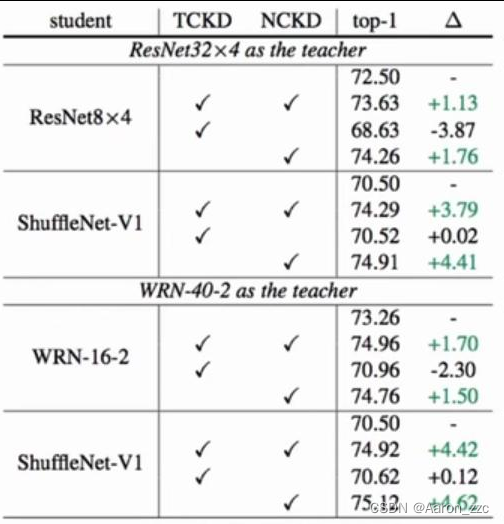
结论:1.TCKD适用于难度较大的数据集,越离谱它可能越有用
随机数据增强与随机改变一些标签的情况下是有效果提升的
 2.他们出现的问题和矛盾点:
2.他们出现的问题和矛盾点:
预测的准,没利用错误分布
预测不准,利用错误分布
都没预测准,利用有啥用呢
 解决:
解决:
好聚好散
分别权重
各自损失
最后叠加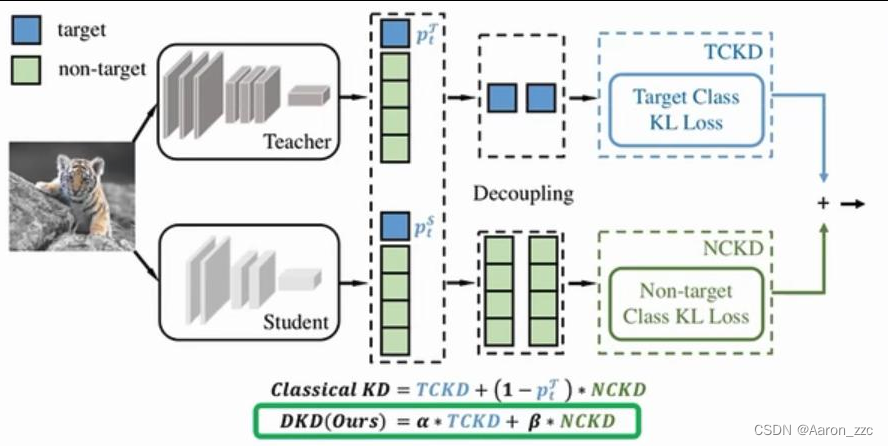
Q.知识迁移和知识蒸馏的区别
迁移:是模型大小差不多的,把效果较好的模型,迁移到另外的模型上。
参考论文:
1.Reinforced Multi-Teacher Selection for Knowledge Distillation
2.Decoupled Knowledge Distillation

















 1088
1088

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









