







Dota数据集切割以及保存为yolo和voc格式——HBB
针对dota目标检测数据集,对image size大于1920的图像进行切割,重叠250个像素点,并且会沿着最后的边缘切割出1920*1920的图像
百度云链接为:链接:https://pan.baidu.com/s/17sabm7k-rZsc5TIvN3pdhw
提取码:nedl
从DOTA1.5的标注中生成YOLO格式标注——HBB
需要修改的位置
from PIL import Image,ImageDraw
import numpy as np
import os
import matplotlib.pyplot as plt
def get_anno(x1,y1,x2,y2,a,c,file):
l1 = a[:,0] < x2-5
l2 = a[:,1] < y2-5
l3 = a[:,2] > x1+5
l4 = a[:,3] > y1+5
l12 = np.logical_and(l1,l2)
l23 = np.logical_and(l3,l4)
l = np.logical_and(l23,l12)
a = a[l]
c = c[l]
a[:,::2] -= x1
a[:,1::2] -= y1
a[:,:2] = (a[:,:2] + a[:,2:])/2
a[:,2:] = (a[:,2:] - a[:,:2])*2
a[:,::2] /= (x2-x1)
a[:, 1::2] /= (y2 - y1)
with open(file,'w+')as f:
for c_,a_ in zip(c,a):
c_ = classnames_v1_5.index(c_)
f.write(str(c_)+' ')
for a__ in a_:
f.write(str(a__)+' ')
f.write('\n')
def read_txt(txt):
with open(txt,'r')as f:
a = f.readlines()[2:]
c = [i.split(' ')[8] for i in a]
a = [i.split(' ')[:6] for i in a]
a = np.array(a,dtype=float)
a = np.concatenate([a[:,:2],a[:,-2:]],axis=1)
return a,np.array(c,dtype=object)
classnames_v1_5 = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field', 'small-vehicle',
'large-vehicle', 'ship', 'tennis-court','basketball-court', 'storage-tank',
'soccer-ball-field', 'roundabout', 'harbor', 'swimming-pool', 'helicopter',
'container-crane']
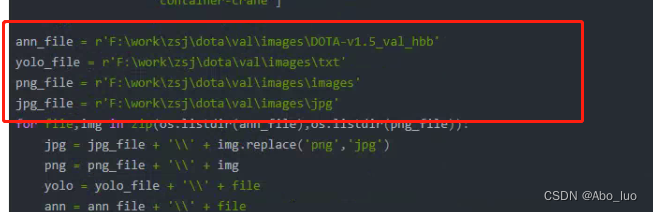
ann_file = r'F:\work\zsj\dota\val\images\DOTA-v1.5_val_hbb'
yolo_file = r'F:\work\zsj\dota\val\images\txt'
png_file = r'F:\work\zsj\dota\val\images\images'
jpg_file = r'F:\work\zsj\dota\val\images\jpg'
for file,img in zip(os.listdir(ann_file),os.listdir(png_file)):
jpg = jpg_file + '\\' + img.replace('png','jpg')
png = png_file + '\\' + img
yolo = yolo_file + '\\' + file
ann = ann_file + '\\' + file
try:
a, c = read_txt(ann)
image = Image.open(png)
q = 0
if image.size[0] > 1920 or image.size[1] > 1920:
for i in range(image.size[0] // 1600):
for j in range(image.size[1] // 1600):
img_ = image.crop((i * 1600, j * 1600, i * 1600 + 1920, j * 1600 + 1920))
jpg_ = jpg.replace('.jpg', '%d.jpg' % q)
yolo_ = yolo.replace('.txt', '%d.txt' % q)
get_anno(i * 1600, j * 1600, i * 1600 + 1920, j * 1600 + 1920, a, c, yolo_)
img_.save(jpg_)
q += 1
img_ = image.crop((i * 1600, image.size[1] - 1920, i * 1600 + 1920, image.size[1]))
jpg_ = jpg.replace('.jpg', '%d.jpg' % q)
yolo_ = yolo.replace('.txt', '%d.txt' % q)
get_anno(i * 1600, image.size[1] - 1920, i * 1600 + 1920, image.size[1], a, c, yolo_)
img_.save(jpg_)
q += 1
for j in range(image.size[1] // 1600):
img_ = image.crop((image.size[0] - 1920, j * 1600, image.size[0], j * 1600 + 1920))
jpg_ = jpg.replace('.jpg', '%d.jpg' % q)
yolo_ = yolo.replace('.txt', '%d.txt' % q)
get_anno(image.size[0] - 1920, j * 1600, image.size[0], j * 1600 + 1920, a, c, yolo_)
img_.save(jpg_)
q += 1
img_ = image.crop((image.size[0] - 1920, image.size[1] - 1920, image.size[0], image.size[1]))
jpg_ = jpg.replace('.jpg', '%d.jpg' % q)
yolo_ = yolo.replace('.txt', '%d.txt' % q)
get_anno(image.size[0] - 1920, image.size[1] - 1920, image.size[0], image.size[1], a, c, yolo_)
img_.save(jpg_)
q += 1
else:
# jpg_ = jpg.replace('.jpg', '%d.jpg' % q)
# yolo_ = yolo.replace('.txt', '%d.txt' % q)
get_anno(0, 0, image.size[0], image.size[1], a, c, yolo)
image.save(jpg)
# print(img + ' finished!')
except:
print(img + 'failed')
根据得到的YOLO格式转换成PASCAL VOC格式
需要进行修改的位置
__Author__ = "Shliang"
__Email__ = "shliang0603@gmail.com"
import os
import xml.etree.ElementTree as ET
from xml.dom.minidom import Document
import cv2
import multiprocessing
from tqdm import tqdm
'''
import xml
xml.dom.minidom.Document().writexml()
def writexml(self,
writer: Any,
indent: str = "",
addindent: str = "",
newl: str = "",
encoding: Any = None) -> None
'''
class YOLO2VOCConvert:
def __init__(self, txts_path, xmls_path, imgs_path):
self.txts_path = txts_path # 标注的yolo格式标签文件路径
self.xmls_path = xmls_path # 转化为voc格式标签之后保存路径
self.imgs_path = imgs_path # 读取读片的路径个图片名字,存储到xml标签文件中
self.classes = ['granulocyte', 'mitotic figure', 'tumor cell', 'other/ambigous cells',
'binucleated cell', 'multinukleated cell', 'Mitotic figure lookalike']
# 从所有的txt文件中提取出所有的类别, yolo格式的标签格式类别为数字 0,1,...
# writer为True时,把提取的类别保存到'./Annotations/classes.txt'文件中
def search_all_classes(self, writer=False):
# 读取每一个txt标签文件,取出每个目标的标注信息
all_names = set()
txts = os.listdir(self.txts_path)
# 使用列表生成式过滤出只有后缀名为txt的标签文件
txts = [txt for txt in txts if txt.split('.')[-1] == 'txt']
print(len(txts), txts)
# 11 ['0002030.txt', '0002031.txt', ... '0002039.txt', '0002040.txt']
for txt in txts:
txt_file = os.path.join(self.txts_path, txt)
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
all_names.add(int(object[0]))
# print(objects) # ['2 0.506667 0.553333 0.490667 0.658667\n', '0 0.496000 0.285333 0.133333 0.096000\n', '8 0.501333 0.412000 0.074667 0.237333\n']
print("所有的类别标签:", all_names, "共标注数据集:%d张" % len(txts))
return list(all_names)
def yolo2voc(self):
# 创建一个保存xml标签文件的文件夹
if not os.path.exists(self.xmls_path):
os.mkdir(self.xmls_path)
# 把上面的两个循环改写成为一个循环:
imgs = os.listdir(self.imgs_path)
txts = os.listdir(self.txts_path)
txts = [txt for txt in txts if not txt.split('.')[0] == "classes"] # 过滤掉classes.txt文件
print(txts)
# 注意,这里保持图片的数量和标签txt文件数量相等,且要保证名字是一一对应的 (后面改进,通过判断txt文件名是否在imgs中即可)
if len(imgs) == len(txts): # 注意:./Annotation_txt 不要把classes.txt文件放进去
map_imgs_txts = [(img, txt) for img, txt in zip(imgs, txts)]
txts = [txt for txt in txts if txt.split('.')[-1] == 'txt']
print(len(txts), txts)
for img_name, txt_name in map_imgs_txts:
# 读取图片的尺度信息
print("读取图片:", img_name)
img = cv2.imread(os.path.join(self.imgs_path, img_name))
height_img, width_img, depth_img = img.shape
print(height_img, width_img, depth_img) # h 就是多少行(对应图片的高度), w就是多少列(对应图片的宽度)
# 获取标注文件txt中的标注信息
all_objects = []
txt_file = os.path.join(self.txts_path, txt_name)
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
all_objects.append(object)
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
# 创建xml标签文件中的标签
xmlBuilder = Document()
# 创建annotation标签,也是根标签
annotation = xmlBuilder.createElement("annotation")
# 给标签annotation添加一个子标签
xmlBuilder.appendChild(annotation)
# 创建子标签folder
folder = xmlBuilder.createElement("folder")
# 给子标签folder中存入内容,folder标签中的内容是存放图片的文件夹,例如:JPEGImages
folderContent = xmlBuilder.createTextNode(self.imgs_path.split('/')[-1]) # 标签内存
folder.appendChild(folderContent) # 把内容存入标签
annotation.appendChild(folder) # 把存好内容的folder标签放到 annotation根标签下
# 创建子标签filename
filename = xmlBuilder.createElement("filename")
# 给子标签filename中存入内容,filename标签中的内容是图片的名字,例如:000250.jpg
filenameContent = xmlBuilder.createTextNode(txt_name.split('.')[0] + '.jpg') # 标签内容
filename.appendChild(filenameContent)
annotation.appendChild(filename)
# 把图片的shape存入xml标签中
size = xmlBuilder.createElement("size")
# 给size标签创建子标签width
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(width_img))
width.appendChild(widthContent)
size.appendChild(width) # 把width添加为size的子标签
# 给size标签创建子标签height
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(height_img)) # xml标签中存入的内容都是字符串
height.appendChild(heightContent)
size.appendChild(height) # 把width添加为size的子标签
# 给size标签创建子标签depth
depth = xmlBuilder.createElement("depth") # size子标签width
depthContent = xmlBuilder.createTextNode(str(depth_img))
depth.appendChild(depthContent)
size.appendChild(depth) # 把width添加为size的子标签
annotation.appendChild(size) # 把size添加为annotation的子标签
# 每一个object中存储的都是['2', '0.506667', '0.553333', '0.490667', '0.658667']一个标注目标
for object_info in all_objects:
# 开始创建标注目标的label信息的标签
object = xmlBuilder.createElement("object") # 创建object标签
# 创建label类别标签
# 创建name标签
imgName = xmlBuilder.createElement("name") # 创建name标签
imgNameContent = xmlBuilder.createTextNode(self.classes[int(object_info[0])])
imgName.appendChild(imgNameContent)
object.appendChild(imgName) # 把name添加为object的子标签
# 创建pose标签
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose) # 把pose添加为object的标签
# 创建truncated标签
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
# 创建difficult标签
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
# 先转换一下坐标
# (objx_center, objy_center, obj_width, obj_height)->(xmin,ymin, xmax,ymax)
x_center = float(object_info[1])*width_img + 1
y_center = float(object_info[2])*height_img + 1
xminVal = int(x_center - 0.5*float(object_info[3])*width_img) # object_info列表中的元素都是字符串类型
yminVal = int(y_center - 0.5*float(object_info[4])*height_img)
xmaxVal = int(x_center + 0.5*float(object_info[3])*width_img)
ymaxVal = int(y_center + 0.5*float(object_info[4])*height_img)
# 创建bndbox标签(三级标签)
bndbox = xmlBuilder.createElement("bndbox")
# 在bndbox标签下再创建四个子标签(xmin,ymin, xmax,ymax) 即标注物体的坐标和宽高信息
# 在voc格式中,标注信息:左上角坐标(xmin, ymin) (xmax, ymax)右下角坐标
# 1、创建xmin标签
xmin = xmlBuilder.createElement("xmin") # 创建xmin标签(四级标签)
xminContent = xmlBuilder.createTextNode(str(xminVal))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
# 2、创建ymin标签
ymin = xmlBuilder.createElement("ymin") # 创建ymin标签(四级标签)
yminContent = xmlBuilder.createTextNode(str(yminVal))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
# 3、创建xmax标签
xmax = xmlBuilder.createElement("xmax") # 创建xmax标签(四级标签)
xmaxContent = xmlBuilder.createTextNode(str(xmaxVal))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
# 4、创建ymax标签
ymax = xmlBuilder.createElement("ymax") # 创建ymax标签(四级标签)
ymaxContent = xmlBuilder.createTextNode(str(ymaxVal))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object) # 把object添加为annotation的子标签
f = open(os.path.join(self.xmls_path, txt_name.split('.')[0]+'.xml'), 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
import matplotlib.pyplot as plt
def yolo2voc(img_name,txt_name,xmls_path,imgs_path,txts_path,classes):
print("读取图片:", img_name)
img = cv2.imread(os.path.join(imgs_path, img_name))
height_img, width_img, depth_img = img.shape
# height_img, width_img, depth_img = 640,640,3
# print(height_img, width_img, depth_img) # h 就是多少行(对应图片的高度), w就是多少列(对应图片的宽度)
# 获取标注文件txt中的标注信息
all_objects = []
txt_file = os.path.join(txts_path, txt_name)
with open(txt_file, 'r') as f:
objects = f.readlines()
for object in objects:
object = object.strip().split(' ')
all_objects.append(object)
print(object) # ['2', '0.506667', '0.553333', '0.490667', '0.658667']
# 创建xml标签文件中的标签
xmlBuilder = Document()
# 创建annotation标签,也是根标签
annotation = xmlBuilder.createElement("annotation")
# 给标签annotation添加一个子标签
xmlBuilder.appendChild(annotation)
# 创建子标签folder
folder = xmlBuilder.createElement("folder")
# 给子标签folder中存入内容,folder标签中的内容是存放图片的文件夹,例如:JPEGImages
folderContent = xmlBuilder.createTextNode(imgs_path.split('/')[-1]) # 标签内存
folder.appendChild(folderContent) # 把内容存入标签
annotation.appendChild(folder) # 把存好内容的folder标签放到 annotation根标签下
# 创建子标签filename
filename = xmlBuilder.createElement("filename")
# 给子标签filename中存入内容,filename标签中的内容是图片的名字,例如:000250.jpg
filenameContent = xmlBuilder.createTextNode(txt_name.split('.')[0] + '.jpg') # 标签内容
filename.appendChild(filenameContent)
annotation.appendChild(filename)
# 把图片的shape存入xml标签中
size = xmlBuilder.createElement("size")
# 给size标签创建子标签width
width = xmlBuilder.createElement("width") # size子标签width
widthContent = xmlBuilder.createTextNode(str(width_img))
width.appendChild(widthContent)
size.appendChild(width) # 把width添加为size的子标签
# 给size标签创建子标签height
height = xmlBuilder.createElement("height") # size子标签height
heightContent = xmlBuilder.createTextNode(str(height_img)) # xml标签中存入的内容都是字符串
height.appendChild(heightContent)
size.appendChild(height) # 把width添加为size的子标签
# 给size标签创建子标签depth
depth = xmlBuilder.createElement("depth") # size子标签width
depthContent = xmlBuilder.createTextNode(str(depth_img))
depth.appendChild(depthContent)
size.appendChild(depth) # 把width添加为size的子标签
annotation.appendChild(size) # 把size添加为annotation的子标签
# 每一个object中存储的都是['2', '0.506667', '0.553333', '0.490667', '0.658667']一个标注目标
for object_info in all_objects:
# 开始创建标注目标的label信息的标签
object = xmlBuilder.createElement("object") # 创建object标签
# 创建label类别标签
# 创建name标签
imgName = xmlBuilder.createElement("name") # 创建name标签
imgNameContent = xmlBuilder.createTextNode(classes[int(object_info[0])])
imgName.appendChild(imgNameContent)
object.appendChild(imgName) # 把name添加为object的子标签
# 创建pose标签
pose = xmlBuilder.createElement("pose")
poseContent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(poseContent)
object.appendChild(pose) # 把pose添加为object的标签
# 创建truncated标签
truncated = xmlBuilder.createElement("truncated")
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
# 创建difficult标签
difficult = xmlBuilder.createElement("difficult")
difficultContent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultContent)
object.appendChild(difficult)
# 先转换一下坐标
# (objx_center, objy_center, obj_width, obj_height)->(xmin,ymin, xmax,ymax)
x_center = float(object_info[1])*width_img + 1
y_center = float(object_info[2])*height_img + 1
xminVal = int(x_center - 0.5*float(object_info[3])*width_img) # object_info列表中的元素都是字符串类型
yminVal = int(y_center - 0.5*float(object_info[4])*height_img)
xmaxVal = int(x_center + 0.5*float(object_info[3])*width_img)
ymaxVal = int(y_center + 0.5*float(object_info[4])*height_img)
# 创建bndbox标签(三级标签)
bndbox = xmlBuilder.createElement("bndbox")
# 在bndbox标签下再创建四个子标签(xmin,ymin, xmax,ymax) 即标注物体的坐标和宽高信息
# 在voc格式中,标注信息:左上角坐标(xmin, ymin) (xmax, ymax)右下角坐标
# 1、创建xmin标签
xmin = xmlBuilder.createElement("xmin") # 创建xmin标签(四级标签)
xminContent = xmlBuilder.createTextNode(str(xminVal))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
# 2、创建ymin标签
ymin = xmlBuilder.createElement("ymin") # 创建ymin标签(四级标签)
yminContent = xmlBuilder.createTextNode(str(yminVal))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
# 3、创建xmax标签
xmax = xmlBuilder.createElement("xmax") # 创建xmax标签(四级标签)
xmaxContent = xmlBuilder.createTextNode(str(xmaxVal))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
# 4、创建ymax标签
ymax = xmlBuilder.createElement("ymax") # 创建ymax标签(四级标签)
ymaxContent = xmlBuilder.createTextNode(str(ymaxVal))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox)
annotation.appendChild(object) # 把object添加为annotation的子标签
f = open(os.path.join(xmls_path, txt_name.split('.')[0]+'.xml'), 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
def print_error(value):
print("error: ", value)
if __name__ == '__main__':
print('开始运行主线程')
multiprocessing.freeze_support()
multiprocessing.Process()
pool = multiprocessing.Pool(multiprocessing.cpu_count())
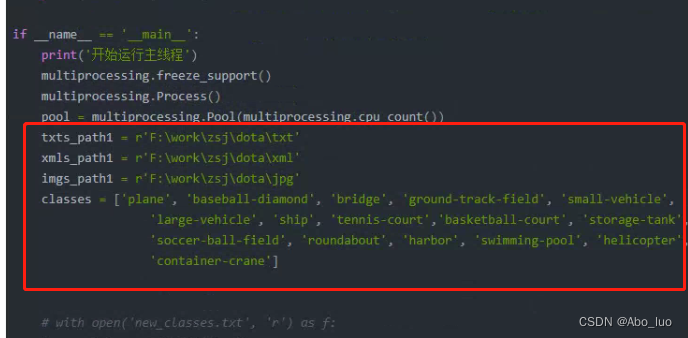
txts_path1 = r'F:\work\zsj\dota\txt'
xmls_path1 = r'F:\work\zsj\dota\xml'
imgs_path1 = r'F:\work\zsj\dota\jpg'
classes = ['plane', 'baseball-diamond', 'bridge', 'ground-track-field', 'small-vehicle',
'large-vehicle', 'ship', 'tennis-court','basketball-court', 'storage-tank',
'soccer-ball-field', 'roundabout', 'harbor', 'swimming-pool', 'helicopter',
'container-crane']
# with open('new_classes.txt', 'r') as f:
# classes = f.readlines()
# classes = [i.split('\n')[0] for i in classes]
#
if not os.path.exists(xmls_path1):
os.mkdir(xmls_path1)
# 把上面的两个循环改写成为一个循环:
imgs = os.listdir(imgs_path1)
txts = os.listdir(txts_path1)
txts = [txt for txt in txts if not txt.split('.')[0] == "classes"] # 过滤掉classes.txt文件
print(txts)
# 注意,这里保持图片的数量和标签txt文件数量相等,且要保证名字是一一对应的 (后面改进,通过判断txt文件名是否在imgs中即可)
if len(imgs) == len(txts): # 注意:./Annotation_txt 不要把classes.txt文件放进去
map_imgs_txts = [(img, txt) for img, txt in zip(imgs, txts)]
txts = [txt for txt in txts if txt.split('.')[-1] == 'txt']
print(len(txts), txts)
num_q = 0
with tqdm(total=len(map_imgs_txts),desc='',postfix=dict,mininterval=0.3)as pbar:
for img_name, txt_name in map_imgs_txts:
num_q += 1
pool.apply_async(func=yolo2voc, args=[img_name, txt_name, xmls_path1, imgs_path1, txts_path1, classes],
callback=print_error)
# pbar.set_postfix(**{'sample:',num_q})
# pbar.set_postfix(**{'sample:',num_q})
pbar.update(1)
pool.close()
pool.join()
print('主线程运行结束')
验证VOC格式 的正确性
需要修改的位置
import matplotlib.pyplot as plt
import cv2
from lxml import etree
import os
import numpy as np
xml = r'F:\work\zsj\yolox-pytorch-main\VOCdevkit\VOC2007\Annotations\3_.xml'
img = r'F:\work\zsj\yolox-pytorch-main\VOCdevkit\VOC2007\JPEGImages\3_.jpg'
for xml,img in zip(os.listdir(r'F:\work\zsj\dota\xml'),os.listdir(r'F:\work\zsj\dota\jpg')):
xml = r'F:\work\zsj\dota\xml' + '\\' + xml
img = r'F:\work\zsj\dota\jpg' + '\\' + img
a = open(xml, 'r')
tree = etree.parse(a)
objects = tree.xpath('.//object')
a = []
for obj in objects:
i = []
i.append(obj.xpath('./bndbox/xmin/text()')[0])
i.append(obj.xpath('./bndbox/ymin/text()')[0])
i.append(obj.xpath('./bndbox/xmax/text()')[0])
i.append(obj.xpath('./bndbox/ymax/text()')[0])
a.append(i)
a = np.array(a, dtype='int')
print(a)
img = cv2.imread(img)
for i in a:
cv2.rectangle(img, i[:2], i[2:4], (0, 255, 0), 2)
plt.imshow(img)
plt.show()
可视化结果展示


总结
对dota数据切割是为了验证小目标检测模型的性能,因此主要是对像素较大的图像进行切割并保存为1920尺寸,但是存在原本较小的图像,那么这些图像的尺寸将不变化。















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









