









文章目录
文章内容:AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE.实现
前提知识:
ViT架构如下:

输入图片分割为
16
×
16
16 \times 16
16×16的patches,并做flatten操作。然后在patches前面添加cls token,并和position embedding做和,之和作为全连接层的输入。生成的张量首先传递到标准Transformer,然后传递到classification head,ViT流程就此结束了。
我们从上至下逐块实现ViT。
1. 导入库
import torch
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torch import nn
from torch import Tensor
from PIL import Image
from torchvision.transforms import Compose, Resize, ToTensor
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange, Reduce
from torchsummary import summary
首先,我们需要一张图片:

然后,对图片进行处理:
# 调整image size
transform = Compose([
Resize((224, 224)),
ToTensor()
])
x = transform(img)
x = x.unsqueeze(0) # add batch dim
print(x.shape) # torch.Size([1, 3, 224, 224])
第一步执行如下图的操作:把image分割为pathces,然后将其flatten。

这一部分对应论文中如下内容:

通过einops完成:
patch_size=16 # pixels
patches=rearrange(x,'b c (h s1) (w s2) -> b (h w) (s1 s2 c)',s1=patch_size,s2=patch_size)
接着,使用标准线性层进行映射:

这里通过创建PatchEmbedding类,保证代码质量和可读性。
2. Patches Embeddings
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# break-down the image in s1 x s2 patches and flat them
Rearrange('b c (h s1) (w s2) -> b (h w) (s1 s2 c)', s1=patch_size, s2=patch_size),
nn.Linear(patch_size * patch_size * in_channels, emb_size)
)
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
#print(PatchEmbedding()(x).shape) # torch.Size([1, 196, 768])
这里需要注意的是,原始作者使用的是Conv2d layer而不是Linear layer来提高性能。者通过使用kernel_size和stride等价于patch_size。直观上,卷积操作分别应用于每个patch。因此,这里首先应用conv layer,然后把图像flatten。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
def forward(self, x: Tensor) -> Tensor:
x = self.projection(x)
return x
#print(PatchEmbedding()(x).shape) # torch.Size([1, 196, 768])
2.1 CLS Token
然后就是添加cls token和position embedding。cls token只是放在每个序列中的数字。
class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768):
self.patch_size = patch_size
super().__init__()
self.proj = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
self.cls_token = nn.Parameter(torch.randn(1, 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.proj(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1)
return x
#print(PatchEmbedding()(x).shape) #torch.Size([1, 197, 768])
cls_token是随机初始化的torch参数,在forward方法中,它被复制b(batch)次,并使用torch.cat添加到要投影的patches前面。
2.2 Position Embedding
到现在为止,模型仍不知道patches的原始位置。我们需要传递这些空间信息。这可以使用不同的方式完成,在ViT中,让模型去学习它。position embeddings只是一个形状为N_PATCHES+ 1(token),并添加EMBED_SIZE到要投影的patches。

class PatchEmbedding(nn.Module):
def __init__(self, in_channels: int = 3, patch_size: int = 16, emb_size: int = 768, img_size: int = 224):
self.patch_size = patch_size
super().__init__()
self.projection = nn.Sequential(
# using a conv layer instead of a linear one -> performance gains
nn.Conv2d(in_channels, emb_size, kernel_size=patch_size, stride=patch_size),
Rearrange('b e (h) (w) -> b (h w) e'),
)
self.cls_token = nn.Parameter(torch.randn(1,1, emb_size))
self.positions = nn.Parameter(torch.randn((img_size // patch_size) **2 + 1, emb_size))
def forward(self, x: Tensor) -> Tensor:
b, _, _, _ = x.shape
x = self.projection(x)
cls_tokens = repeat(self.cls_token, '() n e -> b n e', b=b)
# prepend the cls token to the input
x = torch.cat([cls_tokens, x], dim=1)
# add position embedding
x += self.positions
return x
#print(PatchEmbedding()(x).shape) #torch.Size([1, 197, 768])
以上添加position embedding到position变量中,并将其与forward函数中的patches求和。
至此,我们需要去实现Transformer。
3. Transformer
在ViT中,只使用了Encoder,其架构如下:
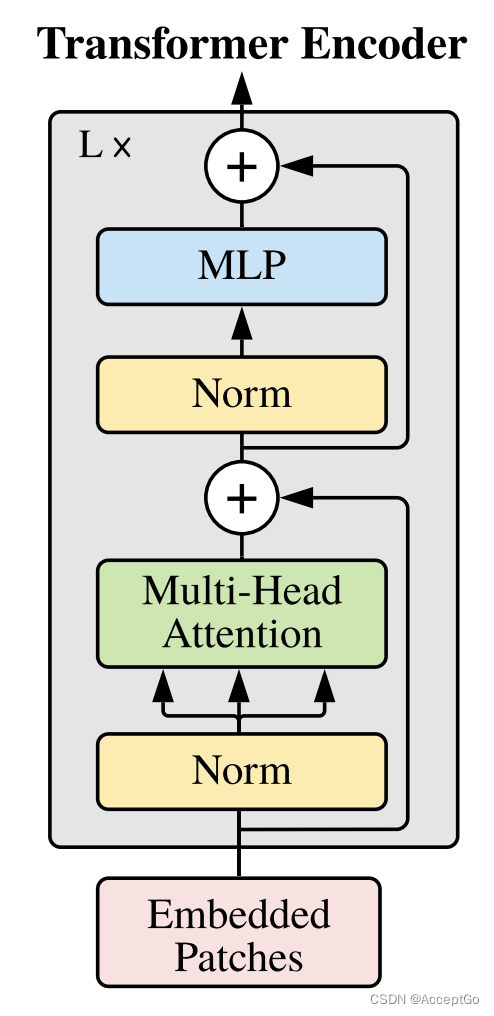
3.1 Attention
attention输入有三项,分别为queries、keys,and values。并且使用queries和values计算attention矩阵,然后使用其去attend(关注)values。在这里,我们使用multi-head attention(多头注意力),这意味着计算被分为n个较小输入的head。

我们可以使用PyTorch中的nn.MultiHeadAttention或自己实现,这里为完整起见,做一个展示:
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 512, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
self.keys = nn.Linear(emb_size, emb_size)
self.queries = nn.Linear(emb_size, emb_size)
self.values = nn.Linear(emb_size, emb_size)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x : Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.num_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.num_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.num_heads)
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1/2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
我们逐一分析。这里有四个全连接层,分别用于queries、keys、values和dropout。
这个想法是使用queries和keys之间的乘积来计算每个元素是序列中其余元素的重要程度,然后使用这些信息对values进行放缩。
forward函数将前一层的queries、keys、values作为输入,并使用三个linear layers进行投影。由于实现了多头注意力,必须重新排列multiple heads的结果。
Queries、Keys、Values始终是一致的,为简单起见,这里只设置一个input(x)。
queries = rearrange(self.queries(x), "b n (h d) -> b h n d", h=self.n_heads)
keys = rearrange(self.keys(x), "b n (h d) -> b h n d", h=self.n_heads)
values = rearrange(self.values(x), "b n (h d) -> b h n d", h=self.n_heads)
生成的keys、queries和values形状为BATCH、HEADS、SEQUENCE_LEN、EMBEDDING_SIZE。
为计算attention矩阵,首先必须执行queries和keys之间的矩阵乘法,这里通过torch.einsum计算。
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys
生成的向量形状为BATCH、HEADS、QUERY_LEN、KEY_LEN。最终注意力是结果向量执行Softmax函数之后除以embedding大小的缩放因子。
最后,使用attention去缩放values。
torch.einsum('bhal, bhlv -> bhav ', att, values)
得到形状为BATCH HEADS VALUES_LEN EMBEDDING_SIZE的向量,然后将其同heads连接在一起,并返回最终结果。
要注意,这里使用单个矩阵一次性计算queries、keys、values。
class MultiHeadAttention(nn.Module):
def __init__(self, emb_size: int = 768, num_heads: int = 8, dropout: float = 0):
super().__init__()
self.emb_size = emb_size
self.num_heads = num_heads
# fuse the queries, keys and values in one matrix
self.qkv = nn.Linear(emb_size, emb_size * 3)
self.att_drop = nn.Dropout(dropout)
self.projection = nn.Linear(emb_size, emb_size)
def forward(self, x: Tensor, mask: Tensor = None) -> Tensor:
# split keys, queries and values in num_heads
qkv = rearrange(self.qkv(x), "b n (h d qkv) -> (qkv) b h n d", h=self.num_heads, qkv=3)
queries, keys, values = qkv[0], qkv[1], qkv[2]
# sum up over the last axis
energy = torch.einsum('bhqd, bhkd -> bhqk', queries, keys) # batch, num_heads, query_len, key_len
if mask is not None:
fill_value = torch.finfo(torch.float32).min
energy.mask_fill(~mask, fill_value)
scaling = self.emb_size ** (1 / 2)
att = F.softmax(energy, dim=-1) / scaling
att = self.att_drop(att)
# sum up over the third axis
out = torch.einsum('bhal, bhlv -> bhav ', att, values)
out = rearrange(out, "b h n d -> b n (h d)")
out = self.projection(out)
return out
patches_embedded=PatchEmbedding()(x)
#print(MultiHeadAttention()(patches_embedded).shape) # torch.Size([1, 197, 768])
3.2 Residuals(残差)
Transformer block存在残差连接。

我们这里创建一个包装器执行残差连接。
class ResidualAdd(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, **kwargs):
res = x
x = self.fn(x, **kwargs)
x += res
return x
attention的输出被传递到全连接层,

3.3 MLP
class FeedForwardBlock(nn.Sequential):
def __init__(self, emb_size: int, expansion: int = 4, drop_p: float = 0.):
super().__init__(
nn.Linear(emb_size, expansion * emb_size),
nn.GELU(),
nn.Dropout(drop_p),
nn.Linear(expansion * emb_size, emb_size),
)
3.4 TransformerEncoder
最后,我们创建Transformer Encoder Block。

ResidualAdd允许我们以如下方式去定义这个block。
class TransformerEncoderBlock(nn.Sequential):
def __init__(self,
emb_size: int = 768,
drop_p: float = 0.,
forward_expansion: int = 4,
forward_drop_p: float = 0.,
** kwargs):
super().__init__(
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
MultiHeadAttention(emb_size, **kwargs),
nn.Dropout(drop_p)
)),
ResidualAdd(nn.Sequential(
nn.LayerNorm(emb_size),
FeedForwardBlock(
emb_size, expansion=forward_expansion, drop_p=forward_drop_p),
nn.Dropout(drop_p)
)
))
patches_embedded = PatchEmbedding()(x)
# print(TransformerEncoderBlock()(patches_embedded).shape) # torch.Size([1, 197, 768])
4. Transformer
在ViT中,只有原始Transformer中的Encoder被使用,TransformerBlock的encoder是L块。
class TransformerEncoder(nn.Sequential):
def __init__(self, depth: int = 12, **kwargs):
super().__init__(*[TransformerEncoderBlock(**kwargs) for _ in range(depth)])
最后一层是标准全连接层,给出类别概率

class ClassificationHead(nn.Sequential):
def __init__(self, emb_size: int = 768, n_classes: int = 1000):
super().__init__(
Reduce('b n e -> b e', reduction='mean'),
nn.LayerNorm(emb_size),
nn.Linear(emb_size, n_classes))
5. ViT
最后,组合PatchEmbedding、TransformerEncoder 和 ClassificationHead创建最终的ViT架构。
class ViT(nn.Sequential):
def __init__(self,
in_channels: int = 3,
patch_size: int = 16,
emb_size: int = 768,
img_size: int = 224,
depth: int = 12,
n_classes: int = 1000,
**kwargs):
super().__init__(
PatchEmbedding(in_channels, patch_size, emb_size, img_size),
TransformerEncoder(depth, emb_size=emb_size, **kwargs),
ClassificationHead(emb_size, n_classes)
)
然后,使用torchsummary来检查参数的数量。
print(summary(ViT(), (3, 224, 224), device='cpu'))



















 3038
3038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









