









Self-attention neural architecture search for semantic image segmentation
发表期刊:Knowledge-Based System
发表时间:2022年
Abstract
自注意力可以捕获长距离依赖关系,并广泛用于语义分割。现有方法主要使用两种self-attention,即spatial attention和channel attention,它们可以分别捕捉HW维度(图像平面、高度和宽度)和C维度(通道)的关系。很少有研究沿着其他维度研究自我注意,这可能会提高分割性能。在这项工作中,我们研究了所有可能维度 {H,W, C,HW, HC, CW, HWC} 的自注意力。然后我们探索所有可能的 self-attention 的聚合。我们应用神经架构搜索(NAS)技术来实现最佳聚合。具体来说,我们精心设计(1)搜索空间和(2)优化方法。对于(1),我们引入了一个构建块,一个基本的自注意力搜索单元(BSU),它可以对所有维度的自注意力进行建模。并且搜索空间包含in-BSU 和crossBSU 操作。此外,我们提出了一种注意力图分割方法,可以将计算量减少 1/3。对于(2),我们应用一种有效的可微优化方法来搜索最优聚合。我们对 Cityscapes 和 ADE20K 数据集进行了广泛的实验。结果表明了所提出方法的有效性,并且与最先进的方法相比,我们取得了非常有竞争力的性能。
Introduction
语义分割是计算机视觉中的一个基本且具有挑战性的问题,旨在对图像中的每个像素进行分类。语义分割广泛用于自动驾驶[1]、场景理解[2,3]和图像编辑[4]。在深度学习时代,基于FCN的方法[5,6]在语义分割领域取得了长足的进步。 FCN [6]首先提出了一种用于语义分割的端到端卷积神经网络。它使用转置卷积层进行上采样和跳过连接以提高性能。然而,FCN [6] 只能捕获短距离的上下文信息,这极大地限制了其在语义分割中的准确性。
大多数方法[7-10]通过上下文融合解决了这个问题。 PSPNet [7] 使用扩张卷积来改善感受野,并提出金字塔池化模块来融合多尺度信息。具体来说,该模块将骨干网络的特征图馈送到金字塔全局平均池化层,以获得多层上采样输出。然后将不同尺度的特征图拼接起来进行上下文信息融合。 DeeplabV3 [8] 提出了空洞空间金字塔池化 (ASPP) 方法,该方法将不同扩张卷积层的特征图连接起来以捕获多尺度上下文信息。一些编码器-解码器架构[6,11-13]被提出来融合中级和高级语义特征。例如,RefineNet [12] 使用 Multi-Path Refinement 将高级语义信息与低级语义信息相结合。
不幸的是,上下文融合方法无法从全局视图中捕获依赖关系,这对于语义分割至关重要。自注意力是捕获长距离依赖关系的有效方法。自注意力首先应用于自然语言处理(NLP)领域[14,15]。可以通过引入Query、Key、Value来聚合一个特征。朱[16]首先在计算机视觉中使用了自注意力方法(非本地网络)。基于图像处理领域的非局部均值滤波的思想,Zhu [16]提出了一种可以直接嵌入到现有网络中的非局部操作,可以捕获远程时空依赖关系。这种非本地网络在动作识别方面取得了巨大成功。毫不奇怪,然后将自我注意应用于分割任务。 CCNet [17]、DANet [18]、OCNet [19]等网络在适应分割任务的非本地网络的基础上提出了一些改进的自注意力模块。分割中主要有两种自我注意模块,即空间注意[16,19]和通道注意[18]。空间注意力集中在特征图的 HW 维度(图像平面、高度和宽度)中的上下文关系。通道注意力捕获与 C 维度的相关性(以及特征图的通道)。尽管沿 {HW, C} 的注意力取得了成功,但尚未研究沿其他维度的注意力。其他维度的注意力也可以潜在地提高分割性能,例如,[20] 表明在某些场景中水平部分之间的像素级分布是不同的。所以沿着 HC 维度的注意力可以有效地提高城市场景的分割。
对于具有 H、W、C 三个维度的特征图,我们考虑其三个维度 {H、W、C、HW、HC、CW、HWC} 的所有组合。给定一个特定的数据集和分割任务,我们永远不会知道哪种自注意力是最有效的。此外,不同self-attention的聚合可以捕捉不同attention的动态,有可能带来有希望的表现。
在这项工作中,我们提出了一种数据驱动的方法来学习自我注意的最佳聚合。该方法包含(1)搜索空间的构建和(2)优化方法。对于(1),我们首先介绍搜索的构建块,即基本的自注意力搜索单元(BSU)。一个 BSU 由 9 个候选自注意力操作组成,这些操作以并行方式组织。我们的搜索空间包含两部分,即在 BSU 内和跨 BSU。 BSU 内搜索空间包含连接到不同 self-attention 的路径;跨 BSU 包括不同 BSU 之间的连接。因此,我们的目标是搜索 BSU 内和跨 BSU 自我注意的最佳聚合。请注意,所有自注意力的计算都是昂贵的。为了减少计算量,在这项工作中,我们提出了一种注意力图分割方法。具体来说,当我们计算二维自注意力时,例如 HW,我们可以通过探索二维和一维注意力之间的数学关系来获得两个一维映射的注意力映射,例如 H 和 W。在第 3.B.2 节中,通过这种方式,我们显着减少了 BSU 中自注意力的计算。对于 (2),受可微神经架构搜索 (NAS) [21] 的启发,我们开发了离散操作的连续松弛(例如,自注意力模块)并使用梯度下降来优化网络架构。
我们的贡献可以总结如下:
- 我们是第一个在所有可能的维度上研究自注意力的人。它可以潜在地捕获特征图中所有可能的长距离依赖关系。
- 为了搜索自注意力模块的聚合,我们创建了 BSU 内和跨 BSU 搜索空间。此外,我们引入了注意力图分割技术以显着减少计算量。然后我们应用可微优化方法来搜索最佳聚合策略。
本文组织如下。第 2 节介绍了相关工作,包括语义分割、自注意力模块和神经架构搜索。在第 3 节中,我们详细介绍了我们的方法。第 4 节进行实验并分析结果。最后,我们在第 5 节中得出结论。
Related work
Semantic segmentation
语义分割是计算机视觉的基本任务之一。语义分割对于许多下游应用都很重要,例如场景理解 [2]、自动驾驶 [1]、计算摄影 [22]、显着性检测 [23,24]、图像搜索引擎 [25]。在深度学习时代之前,传统方法取得了有趣的表现。然而,深度学习方法在分割的准确性甚至效率上超越了传统方法。自从作为开创性解决方案的 FCN [6] 首次采用全卷积网络进行语义分割以来,语义分割在过去几年中取得了长足的进步。
上下文信息对于语义分割至关重要。许多作品提出了强大的方法来融合上下文信息。 DeepLab [5] 使用 CRF(条件随机场)来捕获远程依赖关系和上下文信息。 CRF 能够将低级图像信息与产生每个像素类别分数的多类别推理系统的输出相结合。 U-Net [6]、Deeplab v3+ [11] 和 RefineNet [12] 等网络使用编码器-解码器架构来融合高级和低级特征。 PSPNet [7] 提出了金字塔池化模块来获取多尺度信息。该模块利用金字塔全局平均池化层来融合不同尺度的上下文信息。 Deeplab v2 [5] 和 Deeplab v3 [8] 利用 ASPP(Atrous Spatial Pyramid Pooling)架构嵌入上下文信息,该信息聚合具有不同扩张率的并行扩张卷积。
上下文信息融合的另一种方式是多尺度推理。 CNN 中的许多参数会影响生成的特征图的比例。因此,要解决实际应用中可能遇到的不同尺度之间的问题。一个普通的操作是使用神经网络提取多个尺度的信息,然后将它们整合到一个输出中。 Bian [26]利用多个FCN来处理不同尺度的信息,形成一个广泛的网络。这些网络提取的特征被送入一个额外的卷积层以生成最终的分割结果。
自注意力也用于捕获上下文信息,例如 OCNet [19]、DANet [18] 和 CCNet [17]。我们的工作属于自我关注的范畴。现有的工作只探索了 HW 和 C 维度的自注意力。但是,我们研究了所有可能维度的自注意力。
self-attention module
注意机制最初是在计算机视觉领域提出的。 Mnih [27] 采用 RNN 模型和注意力机制进行图像分类,具有良好的性能。 Bahdanau [28] 是第一个将注意力机制应用于自然语言处理(NLP)领域的人。并且它使用 Seq2Seq 结合注意力模型进行机器翻译并提高其性能。自注意力是一种注意力操作,可以捕获单词的长距离依赖关系。 Vaswani [15] 提出了一种机器翻译任务的自注意力机制,并完全取代了 RNN 和 CNN 或其他流行的网络架构,产生了非常有希望的结果。
非局部神经网络 [29] 首先在计算机视觉中应用自我注意。具体来说,Wang [29] 使用自注意力来捕捉视频中帧之间的相关性,以实现动作识别的良好性能。传统的深度卷积神经网络主要通过叠加多个卷积层来捕获长距离依赖,而self-attention可以直接捕获全局相关信息。 DANet [18] 将两个不同的并行自注意力聚合应用于语义分割。 OCNet [19] 采用带有 ASPP 的自注意力机制来利用上下文依赖关系。 CCNet [17] 依次应用 Criss-Cross attention 来捕获全局相关信息。我们的方法构建了一个由所有可能的自注意力维度组成的搜索空间。然后我们使用数据驱动的方法来搜索不同自注意力的最佳聚合。
Neural Architecture Search(NAS)
最近使用 NAS 搜索高效的网络架构引起了极大的关注。搜索空间和搜索策略(优化)是 NAS 的两个关键组成部分。搜索空间定义了 NAS 算法可以搜索的神经网络架构。 NAS 的搜索空间通常可以表示为没有孤立节点的有向无环图(DAG)。遵循 DAG 表示,大多数 NAS 方法的搜索空间类似于 NASNet [30] 提出的基于单元的搜索空间。一些作品 [31,32] 使用基于 MobileNetV2 [33] 的更节省计算的搜索空间。与基本 CNN 操作的搜索空间不同,我们的目标是搜索不同 self-attention 的聚合。
现有的搜索方法主要包括随机搜索[34]、贝叶斯优化[35]、进化算法[36]、强化学习[37,38]和基于梯度的算法[21]。早期的 NAS 方法 [37] 使用强化学习,需要数千个 GPU 天才能完成搜索。 ENAS [38] 建议共享权重以降低搜索成本。此外,许多方法使用进化算法,例如 [36,39],它们的计算成本也很高。为了解决这个问题,DARTS [21] 提出了一种可微搜索方法,它将搜索时间显着减少到几个 GPU 天。
毫不奇怪,人们将 NAS 应用于语义分割。陈等人[34] 首先将 NAS 应用于语义分割,利用随机搜索来搜索较小的 ASPP 模块。 Auto-DeepLab [40] 使用差分搜索方法来探索编码器架构。在 [41] 中,作者使用强化学习来搜索轻量级网络。 CAS [42]使用多尺度单元设计搜索空间,并使用可微分方法搜索轻量级网络。
与现有方法不同,我们的工作利用有效的可微搜索方法来搜索最优的自注意力聚合。
Methods
在本节中,我们首先展示所有维度的自注意力操作。然后我们描述了最优self-attention聚合的搜索方法。我们设计了一个自注意力搜索空间,并从中构建了一个搜索网络。我们提出了一种Attention-map Splitting方法来降低搜索网络的消耗成本。我们利用可微分方法来优化网络搜索以获得最佳的自注意力聚合。
Self-attention along all dimensions
自注意力是一种注意力操作,它通过计算相关矩阵来捕获长距离依赖性。自注意力最初是在自然语言处理领域(NLP)[14,15]中提出的。然后将其应用于计算机视觉[29],并已广泛用于语义分割[17-19,43]。
自注意力操作可以表示为:
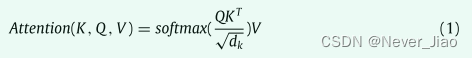
其中 K(键)、Q(查询)、V(值)来自同一输入的不同变换。我们计算 Q 和 K 的相关矩阵并将其与 V 相乘以捕获长距离依赖关系,dk 是一个比例因子。自注意力的计算如图 1 所示。
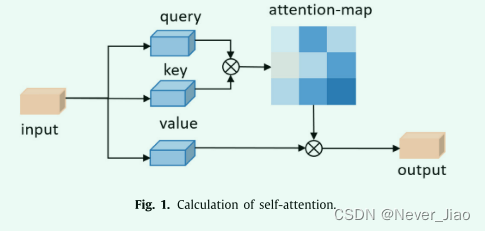
在语义分割领域,应用了两种形式的自注意操作:空间注意[16,19]和通道注意[18]。空间注意力关注特征图的 HW 维度(图像平面、高度和宽度)中的上下文关系,通道注意力捕获与特征图的 C 维度(以及通道)的相关性。尽管沿着 {HW, C} [18,29] 的注意力取得了成功,但其他维度的注意力还没有被研究过。其他维度的注意力可以潜在地提高分割性能,例如,HC维度的注意力可以捕捉图像高度和特征图不同通道的相关性,这可能有助于城市景观的分割。因此,沿着所有可能的维度探索自注意力是很有价值的。
根据上面的讨论,给定一个具有 H、W 和 C 三个维度的特征图,我们将其三个维度的所有组合汇总形成一个集合 {H、W、C、HW、HC、CW、HWC}。因为self-attention沿HWC维度的计算成本太高,所以我们去掉它,即设置S = {H, W, C, HW, HC, CW}。然后我们将self-attentions与集合S中的不同维度一起制定。给定一个特征图A∈RLC×LH×LW,L表示一个特定维度的长度。
我们首先用可学习的 1 × 1 内核将其分别输入两个卷积层以生成特征图 B 和 C。然后我们将它们重塑为 R^LSi ×N^,其中 Si ∈ S 和 N = LHWC /LSi。我们在 C 和 B 的转置之间执行矩阵乘法,并应用 softmax 层来获得沿 Si 维度的自注意力图

其中 mij 表示注意力值,实际上是 Si 维度中第 i 个和第 j 个位置之间的相关性。同时,我们将 A 输入卷积层得到 D 并将 D 重塑为 RN×LSi 的形式。然后我们在 D 和 M(包含元素 mij)之间进行矩阵乘法,得到最终输出 E ∈ RLC×LH×LW,如下所示:

Search the optimal self-attention aggregation
多个self-attention的聚合可以提高表示学习能力。例如,DANet [18] 沿 HW 和 C 维度聚合自注意力,CCNet [17] 以顺序方式聚合多个交叉注意力。然而,给定一个特定的任务和数据集,我们永远不知道最佳聚合:顺序还是并行?哪些维度最适合自注意力?在这项工作中,我们提出了一种数据驱动的方法来搜索沿 3.1 节介绍的不同维度的自我注意的最佳聚合。
Search space of aggregation
在搜索空间中,我们首先构建了构建块 Basic Self-attention search Unit (BSU)。如图 3 所示,一个 BSU 包含 9 个可搜索的 self-attention 操作和一个以并行方式固定(不可搜索)的跳过连接。我们将从一个 BSU 中选择两个最优操作。我们的 BSU 两次包含三个单维 self-attention 操作以获得更多的操作组合,例如组合两个 H 维 self-attention。并且由于我们在 3.2.2 中提出的方法,这些额外的一维 self-attention 操作不会增加计算成本。在许多自注意力模块 [17,18,29] 之后,我们在自注意力操作之前和之后关联 1x1 卷积,以分别减少和增加那里的维度。然后对这十个分支的输出进行逐元素加法运算。然后多个 BSU 块相互密集连接(跨 BSU 连接)。
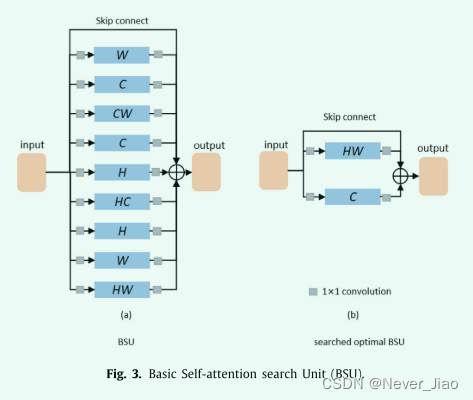
在图 2 中,我们展示了与分割网络相关的可搜索聚合的示例。主干是 4 个阶段的 ResNet50。在每个阶段结束时,我们关联一个 BSU,这些 BSU 是密集连接的。最后一个 BSU 的输出连接到分割头。我们将从所有跨 BSU 路径中选择四个跨 BSU 路径。那么搜索空间总共有 (364) × 15 种可能的网络架构。
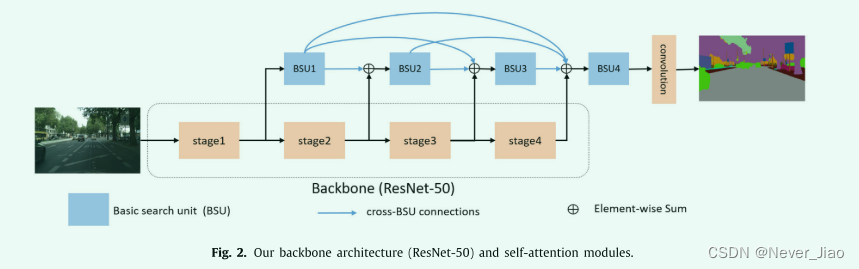
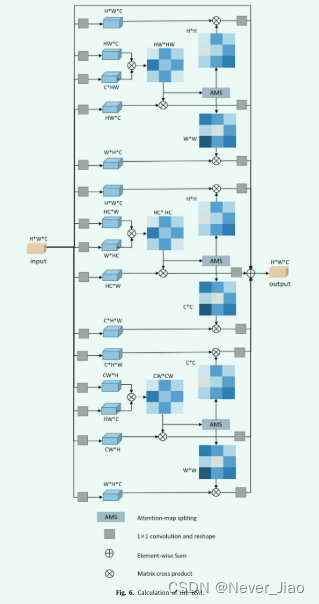
Attention map splitting
在一个 BSU 中,计算九个自注意力操作的计算成本非常高。因此,为了降低计算成本,我们提出了一种注意力图分割方法。具体来说,可以观察到二维自注意力的计算可以与两个单独的一维自注意力共享。例如,当我们沿 HW 计算 self-attention 时,我们可以获得沿 H 和 W 维度的两个单独的注意力图。
下面我们详细介绍一下这个过程。我们假设一个二维(例如 HW)注意力图,MIJ ∈ RLIJ×LIJ,其中 LIJ 表示特征图沿第 i 维和第 j 维的大小(例如 LHW = LH·LW)。注意,注意力图 MIJ 表示 IJ 维度的相关矩阵。如果我们只关注关联维度 I,维度 I 中的关联信息是 MIJ 的子集。如图 4 所示,我们只执行一些简单的切片和加法操作来获得相关矩阵 MI ,即沿维度 I 的自注意图。这个子集 MI 的提取可以用类似 Python 的风格表示:
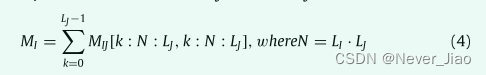
同样,如方程式(5)和图(5)所示。J 维的注意力图也可以从 MIJ 计算出来。
因此,我们只需要计算 3 个二维注意力图 {CW, HC,HW} 即可获得所有 9 个注意力图。
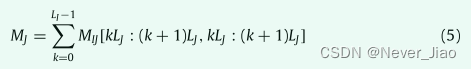
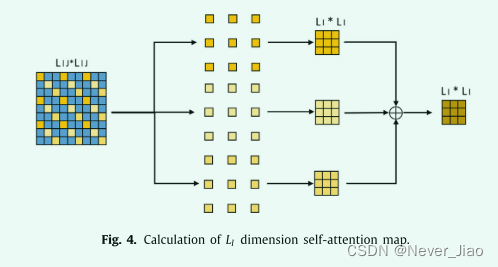
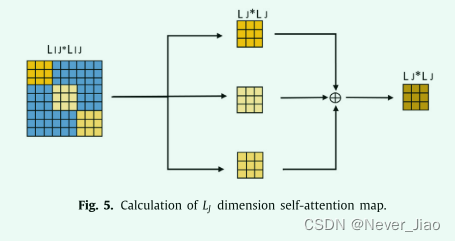
图 6 显示了包含所有注意力图分割操作的详细 BSU。
Differentiable optimization
聚合的优化实际上是神经架构搜索(NAS)[37]的一个特例。 NAS 的主流优化包括强化学习 [37,38,44]、进化算法 [36,45] 和可微优化 [21,46,47]。在这项工作中,我们致力于可微优化,因为它比另外两个流快得多。
首先,我们讨论一个 BSU 内的搜索。遵循流行的可微分方法 DARTS [21],我们在一个 BSU 中引入 α 来加权不同的 self-attention,以通过 softmax 实现连续松弛:
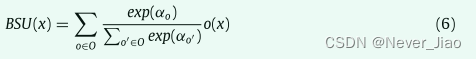
其中 x 是特征图,O 是候选操作的集合,在这项工作中,O 包含沿不同维度的自注意力; α 是与每个算子 o ∈ O 相关的归一化概率标量。
其次,我们制定了跨 BSU 的搜索。我们引入 β,即连接 BSU 之间不同路径的权重。那么跨 BSU 搜索可以表述为:
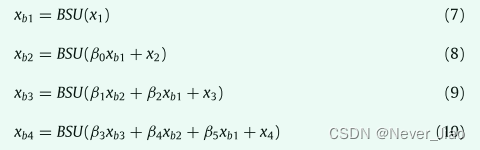
其中xbi是BSU的第i个输出特征图,xi是骨干网络第i阶段的输出特征图。放松后,我们的目标是联合优化架构参数α和β以及网络权重w。它们可以使用梯度下降进行优化。按照 DARTS [21],我们采用交替优化。
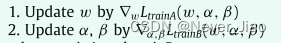
Deriving the optimal aggregation
优化后,我们选择两个具有最大 α 的 BSU 内操作(selfattentions),并选择四个具有最显着 β 值的跨 BSU 路径。然后,我们使用完整的训练集通过 BSU 内和跨 BSU 操作重新训练派生网络。
Experiments
在本节中,我们对 Cityscapes [48] 和 ADE20K [49] 进行了广泛的实验。我们首先介绍实验设置,然后报告结果。最后,我们进行了消融研究,以分析我们算法中每个重要组成部分的有效性。
Datasets and evaluation metrics
Cityscapes 有来自 50 个不同城市的 19 个类别的 5000 张经过良好注释的图像。数据集分为训练集 (2985)、验证集 (500) 和测试集 (1525)。
ADE20K 有 150 个语义类,20000 个用于训练的高质量注释图像,2000 个用于验证的图像,以及 3000 个用于测试的图像。按照现有方法 [7,16,43],我们评估验证集的性能。
我们使用平均 IoU 来评估性能。
Implementation details
在搜索阶段,我们使用包含 4 个阶段的 ResNet-50 作为主干。在每个阶段结束时,我们与一个 BSU 关联。因此,我们有 4 个 BSU,这 4 个 BSU 是密集连接的。输入 4 个 BSU 的特征图的通道数分别设计为 32、64、128 和 256。但是,4 个阶段的输出特征图分别有 256、512、1024、2048 个通道。然后,我们使用 3 × 3 卷积来弥补差距。
Search 我们在 Cityscapes 上进行聚合搜索,并评估搜索到的最佳聚合在 Cityscapes 和 ADE20K 上的性能。对于 Cityscapes 上的搜索,我们在搜索过程中使用 8 台 TESLA P40 训练 10000 次迭代,batch size 为 8,大约需要 1 天时间。搜索过程完成后,我们可以使用 α 和 β 的最终值来推导最优聚合(搜索搜的是维度,α和β的最终值怎么定的?)。
Re-training 一旦得出最佳聚合,我们就会应用 ResNet-101(分割中使用最广泛的骨干网)来重新训练网络。对于重新训练,我们使用与搜索过程相同的学习率。
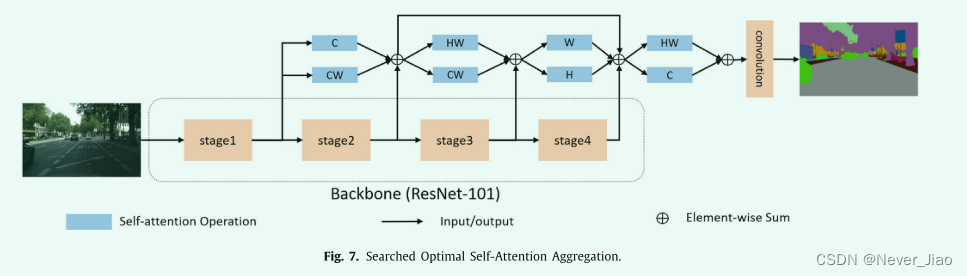
The searched optimal aggregation
搜索到的 self-attention 的最优聚合如图 7 所示。我们可以看到 4 个 BSU 具有最优组合 {C, CW}, {HW, CW}, {W, H}, {HW, C}。现有方法仅提出 {HW} [17-19] 和 {C} [18] 并将它们添加到阶段 4 的末尾,这种手工设计与我们的搜索结果相匹配:最佳搜索 BSU 是 {HW, C},即同样在第 4 阶段结束时。除了 {HW} 和 {C},我们确实发现了许多新的有效聚合。特别是,{CW} self-attention 在最优 BSU 中出现了两次,这意味着沿 {CW} 的 self-attention 是有效的,但现有研究没有讨论过。
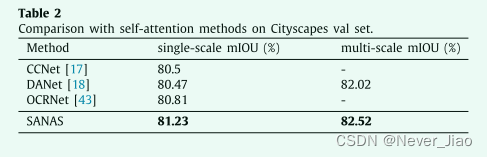
Comparison with existing self-attention methods
由于这项工作主要关注自注意力,我们将我们的方法与现有的自注意力方法进行比较,包括:Cityscapes val 集上的 CCNet [17]、DANet [18] 和 OCRNet [19]。这些方法都使用 ResNet-101 作为骨干网络。通过单尺度测试,我们在 Cityscapes 验证集上达到了 81.2% 的平均 IoU。多尺度测试结果达到 82.52% MIoU。表 2 中的结果表明,我们的方法大大优于竞争对手,显示了我们方法的有效性。
Comparison with state-of-the-art
我们在表 1 中将我们的方法与 Cityscapes 和 ADE20K 上的最新方法进行了比较。如前所述,我们使用最常用的骨干网络 ResNet-101。
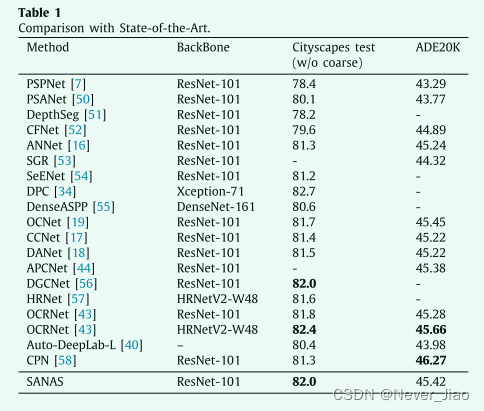
Cityscapes 在不使用 Citysapces 测试数据集上的粗略数据的情况下,我们的方法实现了 82.0% MIoU,这是使用 ResNet-101 的所有方法中最好的结果。我们的方法比使用 ResNet-101 的 OCRNet [19] 效果更好,但比使用更强骨干 HRNetV2-W48 的 OCRNet 稍差。
ADE20K 我们在 Cityscapes 上搜索我们的最佳聚合,然后在 ADE20K 上使用这些聚合,旨在测试我们方法的可迁移性。结果表明,我们的方法比具有相同 ResNet-101 主干的 OCRNet [43] 效果更好。它比在 ADE20K 数据集上使用相同主干的最新方法 CPN [58] 差,但我们在 Cityscapes 数据集上的性能更好。
Ablation Study
在本节中,我们进行消融研究以评估我们方法组件的有效性。消融研究的所有实验均使用 ResNet-50 进行。
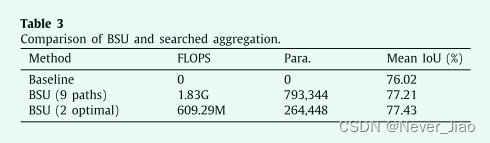
Effectiveness of within-BSU search
在我们的工作中,一个 BSU,它有 9 个 self-attention。然而,我们在最终架构中只选择了 2 个最优的 self-attention。如表 3 所示,我们进行了 3 个实验:没有自我注意的基线,没有搜索的所有 9 个自我注意的 BSU(9 个路径),以及搜索 2 个最佳自我注意的 BSU(2 个最佳)。为了简化实验,我们只在第 4 阶段结束时使用了一个 BSU。与 BSU(9 个路径)相比,结果表明 BSU(2 个最佳)仅使用 1/3 FLOPS 和参数,但实现了更高的平均 IoU。这意味着 BSU 内搜索的有效性。毫不奇怪,BSU(9 条路径)和 BSU(2 条最佳路径)显着优于基线,这表明 self-attention 对分割非常有效。
Effectiveness of cross-BSU search
然后我们讨论BSU之间连接的有效性。手工制作的网络最初提出了跨不同块/单元的连接,DenseNet [59],显示出强大的表示学习能力。然后这些跨块连接也通过 NAS 方法搜索,例如 SpineNet [60]。这些手工设计的 [59] 和基于学习的 [60] 架构已经展示了这种跨块设计的有效性。在本节中,我们验证了跨 BSU 搜索的有用性。具体来说,在搜索阶段,我们选择具有最大 β 值的最优 n (n = 3, 4, 5, 6) 路径。然后我们在 Cityscapes 训练集上重新训练搜索到的网络,并在 Cityscapes 验证集上验证获得的网络架构。我们重复上述步骤五次以获得表 4 所示的平均结果。我们的基线网络是基于 ResNet 的 FCN。当n = 6时,所有BSU都密集连接,其结果最差,当n = 4时,结果最好。这意味着保持所有连接不是最佳的。原因可能是太多的连接会导致局部最小值。在 SpineNet [60] 中也可以找到类似的跨块搜索的结论和观察结果。

Effectiveness of attention-map splitting
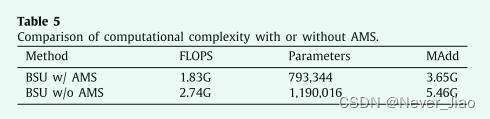
引入注意力图拆分 (AMS) 以减少 BSU 中自注意力的计算。然后我们展示了注意力图分割(AMS)的效果。我们比较了有和没有 AMS 的搜索网络的最后一个 BSU 中的参数、FLOPS 和 MAdd。从表 5 中可以看出,在参数、FLOPS 和 MAdd 方面,带 AMS 的 BSU 比不带 AMS 的 BSU 具有极好的优势。具体来说,AMS 可以将计算成本降低约 1/3。
Effectiveness of our differentiable optimization
最后,我们讨论了可微优化方法的有效性。我们将我们的优化与随机搜索进行比较。具体来说,我们在搜索空间中随机采样网络架构 5 次,以获得 5 个自注意力聚合。然后我们使用我们的可微搜索方法搜索 5 次以获得另外 5 个 self-attention 聚合。然后我们在 Cityscapes 训练集上训练这些网络架构,并在验证集上获得平均结果。
从表 6 可以看出,我们的可微优化方法明显优于随机搜索,分别为 77.83% 和 76.53%,显示了我们优化的有用性。

Conclusions
在这项工作中,我们是第一个研究所有可能维度 {H,W,C,HW,HC,CW,HWC} 的注意力,旨在探索特征图中所有有趣的长距离依赖关系。基于这种完整的自注意力,我们从不同注意力的各种聚合中探索最佳能力。我们仔细构建了一个由内部 BSU 和跨 BSU 操作组成的搜索空间,以实现最佳聚合。 BSU 内的操作包含所有可能的自注意力维度。跨 BSU 操作包含不同 BSU 之间的连接。此外,我们提出了一种注意力图分割方法,以显着降低 BSU 的计算成本。我们进一步提出了一种可微优化策略,以基于该搜索空间搜索该最优聚合。 Cityscapes 和 ADE20K 的结果验证了我们的方法在提高语义分割性能方面非常有效。
未来,我们希望探索相关领域的自注意力聚合策略,例如图像分类和对象检测。此外,我们将探索网络剪枝和知识蒸馏,以提高我们方法的速度。















 1639
1639











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









