







这篇文章是首篇将局部(Local)注意力和全局(Non-Local)注意力进行结合来做图像重建的论文。文章作者设计了一个将局部注意力机制和全局注意力机制一起协同合作来重建图像的网络模型——Collaborative Attention Network(COLA-Net);文章的核心是提出了一个patch-wise的产生自注意力的新结构,和ViT不同,它除了拥有捕捉图像上长距离相关性之外,还能更好地捕捉局部相关性,当然也只是增加了一些局部相关,但并没有做到CNN那样捕捉局部相关性的能力。
Note:
- 局部注意力和全局注意力 \colorbox{violet}{局部注意力和全局注意力} 局部注意力和全局注意力:局部注意力是诸如RCAN中的通道注意力、EDVR中TSA的时间和空间注意力,它利用一些局部性算子来产生注意力,比如卷积、池化等手段;全局注意力,即Non-Local注意力是指自注意力机制,即Transformer的核心结构。
- 局部相关性和全局相关性 \colorbox{tomato}{局部相关性和全局相关性} 局部相关性和全局相关性:局部相关性指的是基于CNN的神经网络在图像识别等任务上的应用就是利用局部区域的相关性,从而让卷积窗口可以提取小范围区域内的特征;全局相关性是在图像上长距离上的相关性,这个卷积是做不了的,一般都是用自注意力机制来产生图像上不同位置的patch之间的相关性。
- 注意力机制的核心就是相关性,而相关性是由相似度指标来衡量的,在Transformer里的自相关系数是通过点乘实现的。
参考文档:
①Transformer-基础知识
②源码
③关于 Transformer 那些的你不知道的事
COLA-Net: Collaborative Attention Network for Image Restoration
Abstract
为什么需要结合局部注意力机制和全局注意力机制?
因为只有局部注意力机制的话,感受野就比较小,无法捕捉较长或较大范围内的特征;同理,只有全局注意力的话,就只能捕捉长距离范围内的相关性,而无法捕捉细小范围内的特征。因此,如果将两种注意力以一定方式相互协同配合,那么就可以发挥二者的优势,为图像重建带来表现力的提升。
Note:
- 图像重建包括:超分、去模糊、去噪、去块等等。
本文的主要内容:
- 局部注意力(Local-Attention)和全局注意力(Non-Local-Attention)在图像重建任务上可以产生出色的表现力,但目前的图像重建方法一般都包含2种注意力中的一种;因此作者提出了一种结合局部注意力和全局注意力的新结构——
Collaborative Attention Network(COLA-Net),这也是首次将两种注意力一起结合在图像重建任务上。 - 此外,作者提出了一个将自注意力机制用在图像上的新结构,不同于ViT将图像分块、Embeddding、3次conv求QKV的过程,这个新结构是先3次conv求QKV、基于滑动窗口的unfold分块、reshape成QKV的过程,这样的自注意力模块的设计有2大好处:①Unfold过程基于sliding-window,因此不同patch之间是可以有重叠的,这样的话不同patch之间更加紧密,相当于间接增加了一些局部相关性;②开头的3次求KQV的过程如果设置成卷积size大于1的CNN层的话,后面的patch就是基于feature map,即patch是带着局部特征去生成QKV的,这就在本身捕捉全局相关性的基础上增加了局部相关性,这对于一些往一些需要局部特征信息的图像重建任务引入Transformer带来了思路,比如超分等。
- COLA-Net在三大重建任务:图像去噪、真实图像去噪、去压缩artifacts上都取得了在PSNR和视觉感知上的SOTA水平!
1 Introduction
- 局部注意力和全局注意力可以互相补充来提升表现力。具体而言,当图像中存在较多重复类似的细节,那么全局相关性就有利于这些细节的特征的学习;如果图像中存在一些复杂的纹理细节,那么只用全局注意力会产生平滑的artifacts,此时局部的注意力就可以帮助学习这些纹理。
- 因此COLA-Net就需要去学习这两种注意力。对于局部注意力,作者推出了channel-wise注意力,此外作者将其基于不同尺度的特征上来增大局部操作的感受野;对于全局注意力(Non-Local),作者推出了一种新的patch-wise自注意力网络来构建不同patch在长距离上的依赖关系。
小结一下:
- 本文推出了一种结合局部注意力机制和全局注意力机制的网络模型——
COLA-Net。 - 本文推出了一种patch-wise自注意力模型结构,它是Transformer中自注意力模块在计算机视觉上的延展,这种结构可以捕获图像在长距离上的相关性。
- 作者使用三种图像重建任务:图像去噪、真实场景去噪、去压缩artifacts来验证COLA-Net的有效性,结果其实现了SOTA的表现力,证明了模型的可行性。
2 Related Work
Non-Local Attention
\colorbox{orange}{Non-Local Attention}
Non-Local Attention
设
Q
\mathbb{Q}
Q为搜索范围,查询项(Query items)为
y
i
y_i
yi,关键项(Key items)为
y
j
y_j
yj,且
ϕ
(
y
i
,
y
j
)
\phi(y_i,y_j)
ϕ(yi,yj)表示二者的相似度,
G
(
⋅
)
G(\cdot)
G(⋅)表示embedding function,则自注意力机制可表示为:
x
i
^
=
1
z
i
∑
j
∈
Q
ϕ
(
y
i
,
y
j
)
G
(
y
j
)
,
∀
i
.
(1)
\hat{x_i} = \frac{1}{z_i}\sum_{j\in \mathbb{Q}} \phi(y_i,y_j) G(y_j), \forall i.\tag{1}
xi^=zi1j∈Q∑ϕ(yi,yj)G(yj),∀i.(1)其中
i
∈
I
i\in\mathbb{I}
i∈I表示图像中所有的pixel/patch序号,且
Q
⊂
I
\mathbb{Q}\subset \mathbb{I}
Q⊂I;
y
i
,
y
j
y_i,y_j
yi,yj都是向量,每个向量都代表着1个patch;
z
i
=
∑
j
∈
Q
ϕ
(
y
i
,
y
j
)
z_i=\sum_{j\in\mathbb{Q}}\phi(y_i,y_j)
zi=∑j∈Qϕ(yi,yj)表示归一化值;
G
(
y
j
)
G(y_j)
G(yj)是
y
j
y_j
yj的另一种表达;
x
i
^
\hat{x_i}
xi^是结合注意力之后关于
y
j
y_j
yj的新的表达,这个表达结合了
y
i
y_i
yi和
y
j
y_j
yj的相关性。
在神经网络中,也就是将它用在Transformer中, y i , y j y_i,y_j yi,yj分别表示 Q 、 K Q、K Q、K,而 G ( y j ) G(y_j) G(yj)往往是一个卷积层的输出结果(也就是 V V V,因此 K 、 V K、V K、V是同一个token的不同表达), ϕ ( y i , y j ) = y i T y j \phi(y_i,y_j)=y_i^T y_j ϕ(yi,yj)=yiTyj。所以式(1)表达的就是第 i i i个patch在搜索范围内找出所有的 y i y_i yi并通过彼此之间的相似度来查询相应的 G ( y i ) G(y_i) G(yi)值,最后进行加权平均之后的值就是第 i i i个patch结合所有patch相关性的输出值。
Note:
- Softmax计算的是每一个patch对其他patch的相似度:
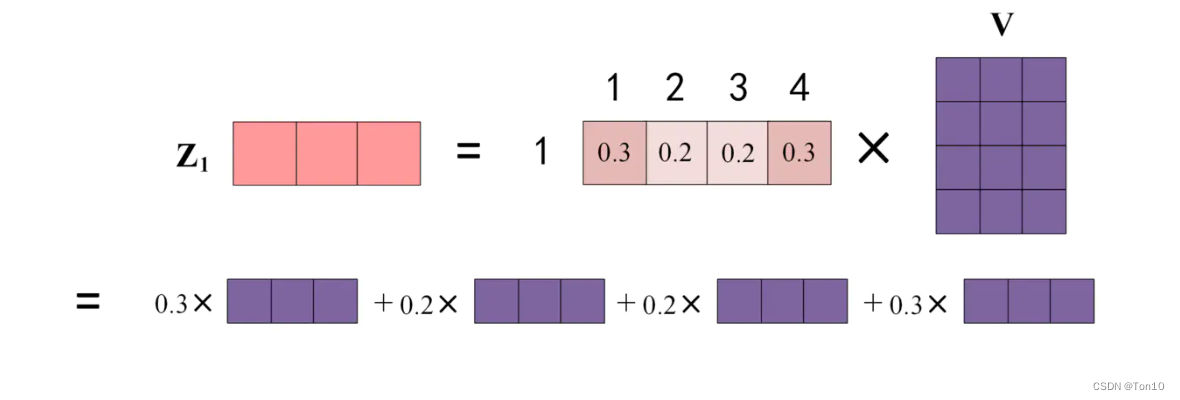 上图表达的就是式(1),
x
i
^
\hat{x_i}
xi^表示更新之后的值,其是token的带注意力的表达。
上图表达的就是式(1),
x
i
^
\hat{x_i}
xi^表示更新之后的值,其是token的带注意力的表达。 - 在Transformer中, K 、 V K、V K、V是同一个token的不同表达,相当于key-value的关系, Q Q Q往往是另一个token的表达。
Local Attention
\colorbox{yellow}{Local Attention}
Local Attention
用局部算子产生的注意力机制称为Local Attention,比如RCAN中的通道注意力,EDVR中的时空注意力机制,它们都是用卷积、池化这种局部手段产生的。优点在于可以捕捉局部相关性,缺点在于感受野相对较小,无法捕捉长距离的相关性。
为什么用
Q
K
T
QK^T
QKT来衡量相似度?
我们知道学习到的
Q
、
K
Q、K
Q、K矩阵的每一行向量代表1个patch,因此
Q
K
T
QK^T
QKT就可以看成是向量之间的内积,如果每个向量都是单位向量,那么
Q
K
T
QK^T
QKT就相当于衡量余弦相似度。但Transformer中并没有对
Q
、
K
Q、K
Q、K做归一化,因此严格来说
Q
、
K
Q、K
Q、K并不能衡量相似度,合理的做法应该是:
s
o
f
t
m
a
x
(
Q
K
T
d
k
⋅
(
∏
i
=
0
N
−
1
∏
j
=
0
N
−
1
∣
∣
Q
i
∣
∣
⋅
∣
∣
K
j
T
∣
∣
)
)
softmax(\frac{QK^T}{\sqrt{d_k}\cdot (\prod_{i=0}^{N-1}\prod_{j=0}^{N-1}||Q_i||\cdot ||K^T_j||)})
softmax(dk⋅(∏i=0N−1∏j=0N−1∣∣Qi∣∣⋅∣∣KjT∣∣)QKT)
,但个人认为可能不进行归一化仍然取得了不错的性能,同时为了节省一定的计算量所以干脆就不加了。
为什么Transformer需要大数据量才能进行学习?
简单一句话:因为更弱的归纳偏置(归纳偏好)就需要更多的训练数据来训练。
~~~~~~~
具体而言:AI 研究人员在构建新的机器学习模型和训练范式时,通常会使用一组被称为归纳偏置(inductive biases)的特定假设,来帮助模型从更少的数据中学到更通用的解决方案。近十年来,深度学习的巨大成功在一定程度上归功于强大的归纳偏置,基于其卷积架构已被证实在视觉任务上非常成功,它们的hard归纳偏置使得样本高效学习成为可能,但代价是可能会降低性能上限。而视觉 Transformer(如 ViT)依赖于更加灵活的自注意力层,最近在一些图像分类任务上性能已经超过了CNN,但ViT对样本的需求量更大。Vision Transformer往往需要大量的额外数据以及更长的训练时间,为transformer在视觉任务的实际应用造成困难。这种现象的一个重要的原因是现有工作将图像作为一维序列,忽略了对视觉任务特有的归纳偏置的建模,即对图像局部相关性、物体的尺度不变性的建模,导致模型无法高效地利用数据,影响收敛速度和模型性能。在视觉任务上非常成功的CNN依赖于架构本身内置的两个归纳偏置:①局部相关性:邻近的像素是相关的;②权重共享:图像的不同部分应该以相同的方式处理,无论它们的绝对位置如何。相比之下,基于自注意力机制的视觉模型(如DeiT和DETR)最小化了归纳偏置。当在大数据集上进行训练时,这些模型的性能已经可以媲美甚至超过CNN,但在小数据集上训练时,它们往往很难学习有意义的表征。这就存在一种取舍权衡:CNN强大的归纳偏置使得即使使用非常少的数据也能实现高性能,但当存在大量数据时,这些归纳偏置就可能会限制模型。相比之下,Transformer 具有最小的归纳偏置,这说明在小数据设置下是存在限制的,但同时这种灵活性让 Transformer 在大数据上性能优于 CNN。
~~~~~~~
为了缓解Transformer在图像任务中消耗数据量大的问题,一般有2种解决方案:①在ViT模型中使用了纯Transformer结构,它发现使用大规模的数据集可以战胜归纳偏置对其限制,其利用在大型数据集上预训练,而在中或小型数据集上微调来取得较好的表现力;②另一种办法是将Transformer和CNN结合使用,无论是用Transformer取代CNN网络中2的部分CNN或者是两者组成pipeline,还是往CNN中加入自注意力机制来同时利用局部相关性和全局相关性的方法都可以降低Transformer的训练量需求。
Note:
- 关于归纳偏好,详细参看西瓜书第1.4节。
- 归纳偏好粗略解释:在数据拟合场景下,其实拟合的解有很多,但比如我们假设平滑的曲线才是我们认为更好的解,因此比如说增加一些正则化项来使得曲线趋于平滑,那么最后使得损失函数最小的解就是我们想要的解,可以知道的是这个解一定是相当平滑的,具体如下所示:
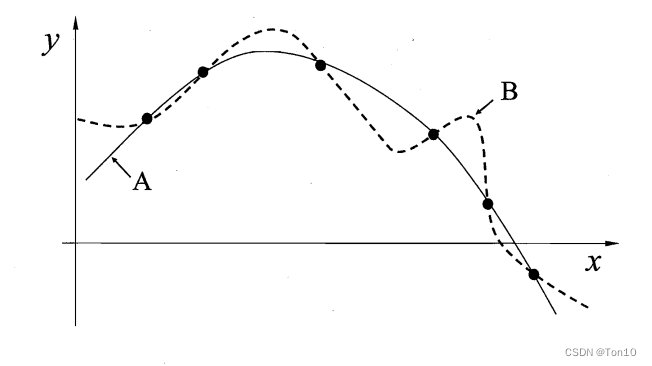
。在神经网络中的归纳偏好可解释为:AI工作者假设神经网络在计算机视觉上的归纳偏置是其在局部相关性、2D的近邻结构、空间不变性上的学习能有更好的收敛表现力和收敛速度,它们基于这个假设设计了CNN这种滑窗结构来利用图像局部相关性来学习分类等任务,这样最后产生的效果我们认为是最优的解,并且实践证明CNN确实能做到比较不错的表现力与收敛速度,这证明了这个归纳偏置假设是正确的,CNN确实是收敛性能和速度上最佳的选择,它能高效地使用数据集。而Transformer呢,根据没有午餐定理,他也是可以解决图像分类等任务的,和CNN一样也是解空间的一种,但是它没有CNN具有的那些归纳偏置,就像上图曲线B一样,他在该问题上不是最优解,它利用的是图像全局相关性,由于其无法利用归纳偏置中图像天然的局部相关性,而是基于patch来学习全局相关性,因为其无法对归纳偏置进行建模,那就必须从头开始学习,这就意味要使用更多的数据才能学会! - 从另一个角度来理解Transformer需要更大数据量的原因:因为Transformer学习的是全局相关性,具有更大的感受野,而如果对CNN来说想要达到这么大的感受野就必须要把网络堆叠地很深,复杂度模型就必然需要较大地数据量才能学习,因此Transformer才需要大量数据集才能学习。
3 COLA-Net
3.1 Framework
COLA-Net的pipeline如下所示:
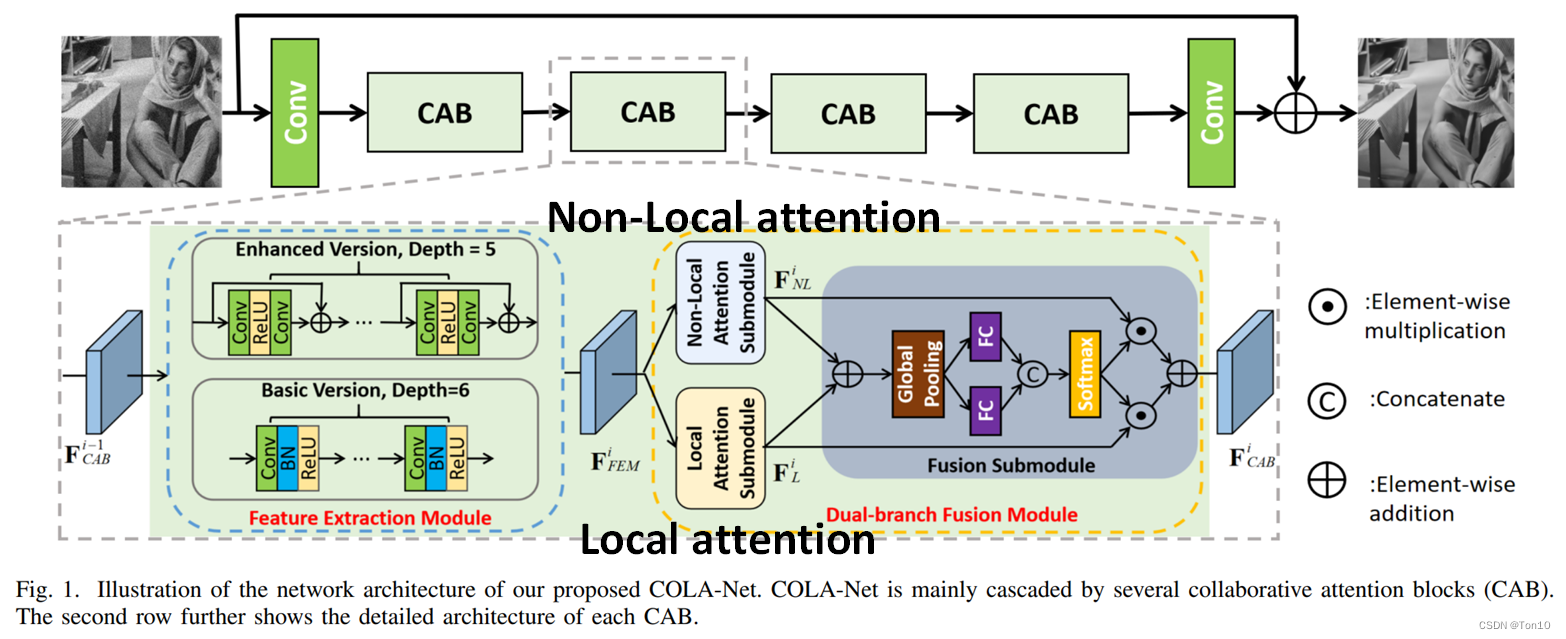
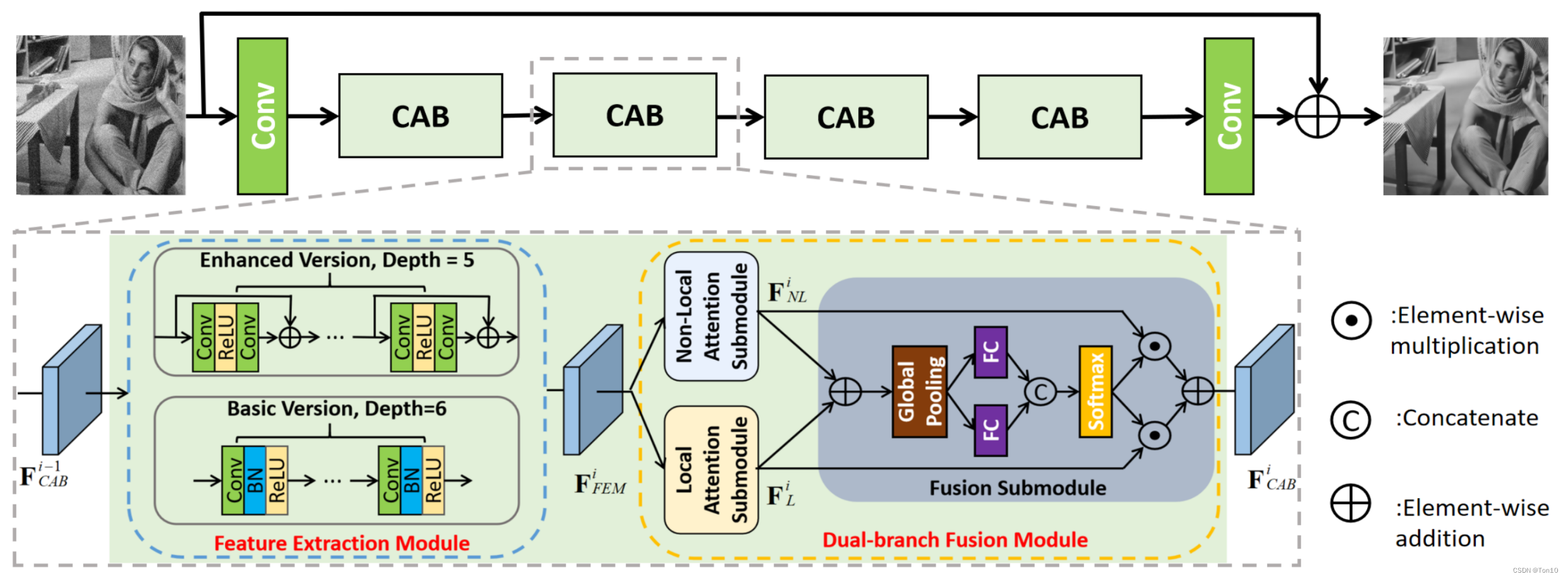
整个网络可以分为3部分:①浅层特征提取;②Collaborative Attention Block(CAB)级联模块;③重建模块。
浅层特征提取
\colorbox{hotpink}{浅层特征提取}
浅层特征提取
从原图中提取出浅层特征
F
s
F_s
Fs,具体表达式如下:
F
s
=
H
S
F
(
I
L
Q
)
.
(2)
F_s = \mathcal{H}_{SF}(I_{LQ}).\tag{2}
Fs=HSF(ILQ).(2)其中
H
S
F
(
⋅
)
\mathcal{H}_{SF}(\cdot)
HSF(⋅)表示浅层特征提取算子。
CAB级联模块
\colorbox{yellow}{CAB级联模块}
CAB级联模块
如上图所示,作者级联了4个CAB,其输入是浅层特征
F
s
F_s
Fs,输出是
F
C
A
B
4
F_{CAB}^4
FCAB4,其作为重建模块的输入。
数学表达式为:
F
C
A
B
i
=
H
C
A
B
i
(
⋯
H
C
A
B
1
(
F
s
)
⋯
)
.
(3)
F^i_{CAB} = \mathcal{H}_{CAB}^i(\cdots \mathcal{H}_{CAB}^1(F_s)\cdots).\tag{3}
FCABi=HCABi(⋯HCAB1(Fs)⋯).(3)其中
F
C
A
B
i
、
H
C
A
B
i
F^i_{CAB}、 \mathcal{H}_{CAB}^i
FCABi、HCABi分别表示第
i
i
i个CAB块的输出feature map以及第
i
i
i个CAB块算子。
CAB块是COLA-Net的核心,其内部分为2部分:①特征提取模块(FEM);②双分支融合模块(DFM)。
FEM模块:
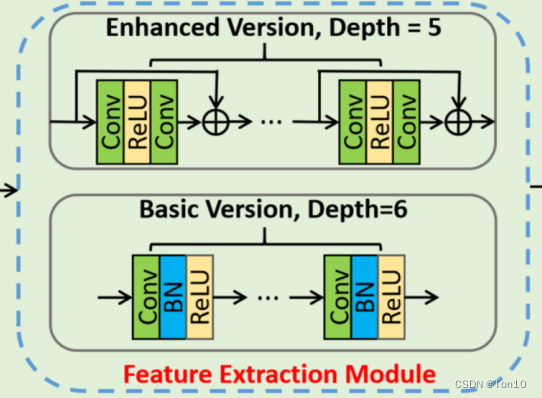
作者设计2种深层特征提取子网络,一种较为轻量型(Basic)的:它由6个包含
c
o
n
v
→
B
N
→
R
e
L
U
conv\to BN\to ReLU
conv→BN→ReLU级联组成,每个卷积层的size为
3
×
3
×
64
3\times 3\times 64
3×3×64;另一种是增强型(Enhanced)的残差网络结构,由5个残差块级联组成,每个卷积层都是
3
×
3
×
64
3\times 3\times 64
3×3×64。
此外,如果是第一种版本的FEM,则COLA-Net记为COLA-B;第二个版本的FEM,则COLA-Net就记为COLA-E。
DFM模块:
DFM模块是CAB的核心,它将局部注意里和通道注意力分别并行处理,最后进行融合产生具备注意力机制的feature map,即
F
C
A
B
i
F^i_{CAB}
FCABi;其中融合部分也是一个注意力机制的过程。
重建模块
\colorbox{tomato}{重建模块}
重建模块
这个重建模块可以理解为3层意思:①深层特征提取;②从feature-wise重建成image-wise;③特征校正、调整。
除了进一步提取CAB输出的特征以外,还要和来自低层的特征进行融合,这部分结构也是被常用于图像重建任务,其有4个好处:①将不同层级的特征进行融合,从而让特征之间互为补充来重建出更好的图像;②构成残差结构,让网络更好的去学习残差信息,一定程度上减轻残差部分的学习压力,增加稳定性;③skip-connection可以作为正则化项;④正如DRCN所述:将原图像直接输送到网络尾端,可以弥补卷积过程造成的特征损失。
具体数学表达式如下:
I
R
E
C
=
I
L
Q
+
H
D
F
(
F
C
A
B
4
)
=
H
C
O
L
A
(
I
L
Q
)
.
(4)
I_{REC} = I_{LQ} + \mathcal{H}_{DF}(F_{CAB}^4) = \mathcal{H}_{COLA}(I_{LQ}).\tag{4}
IREC=ILQ+HDF(FCAB4)=HCOLA(ILQ).(4)其中
H
D
F
(
⋅
)
、
H
C
O
L
A
(
⋅
)
\mathcal{H}_{DF}(\cdot)、\mathcal{H}_{COLA}(\cdot)
HDF(⋅)、HCOLA(⋅)分别为最后一层卷积层以及整个COLA网络。
损失函数
\colorbox{dodgerblue}{损失函数}
损失函数
L2损失函数:
L
(
Θ
)
=
1
B
∑
b
=
1
B
∣
∣
I
H
Q
b
−
H
C
O
L
A
(
I
L
Q
b
)
∣
∣
2
2
.
(5)
L(\Theta) = \frac{1}{B}\sum^B_{b=1}||I^b_{HQ} - \mathcal{H}_{COLA}(I^b_{LQ})||_2^2.\tag{5}
L(Θ)=B1b=1∑B∣∣IHQb−HCOLA(ILQb)∣∣22.(5)
3.2 Dual-branch Fusion Module
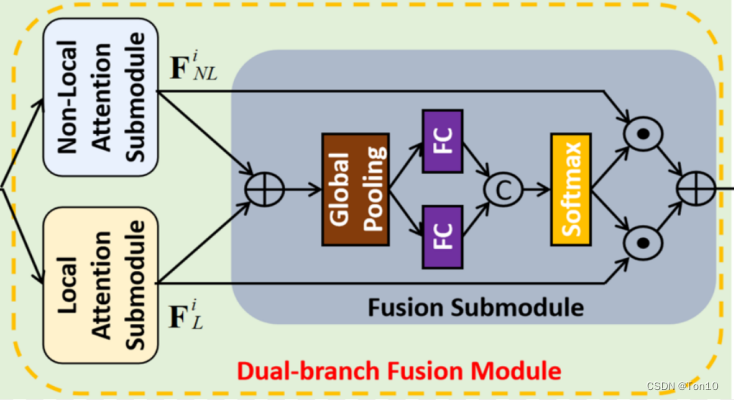
整个DFM由3部分组成:①Local注意力模块;②Non-Local注意力模块;③融合模块。
DFM利用局部注意力模块去捕捉局部相关性来重建复杂纹理特征;利用全局注意力去捕捉全局相关性去重建长距离上相关的细节特征,比如一些重复性很高的特征;融合模块本质也是一种Local Attention,将两个分支的注意力结果进一步施加注意力来提取更有用的特征。
Note:
- 局部注意力的核心是局部操作(local operation),如卷积池化;全局注意力的核心是自相关性(self-similarity)计算,如公式(1)所示。
具体而言,FEM输出的feature map作为输入,即
F
F
E
M
i
F^i_{FEM}
FFEMi,然后局部注意里和全局注意力两个并行分支分别进行注意力提取,分别输出
F
L
i
、
F
N
L
i
F^i_L、F_{NL}^i
FLi、FNLi,数学表达式如下:
{
F
L
i
=
H
L
(
F
F
E
M
i
)
,
F
N
L
i
=
H
N
L
(
F
F
E
M
i
)
.
(6)
\begin{cases} F^i_L = \mathcal{H}_L(F^i_{FEM}),\\ F_{NL}^i = \mathcal{H}_{NL}(F^i_{FEM}).\tag{6} \end{cases}
{FLi=HL(FFEMi),FNLi=HNL(FFEMi).(6)其中
H
L
(
⋅
)
、
H
N
L
(
⋅
)
\mathcal{H}_L(\cdot)、\mathcal{H}_{NL}(\cdot)
HL(⋅)、HNL(⋅)分别表示Local注意力子模块和Non-Local注意力子模块的函数。并且两者的输出通道是一样的,记为
C
C
C。
Fusion Submodule \colorbox{yellow}{Fusion Submodule} Fusion Submodule
接下来就要进入融合子网络,它本质也是个通道注意力网络(channel-wise):首先将
F
N
L
i
、
F
L
i
F_{NL}^i、F^i_L
FNLi、FLi进行相加;然后通过全局平均池化输出
v
∈
R
C
v\in \mathbb{R}^C
v∈RC;接着分别用2个全连接层
H
F
C
1
(
v
)
、
H
F
C
2
(
v
)
\mathcal{H}_{FC}^1(v)、\mathcal{H}^2_{FC}(v)
HFC1(v)、HFC2(v)输出2个各自
C
C
C通道的张量,并通过通道合并成
2
C
2C
2C的张量;最后使用softmax获取
[
0
,
1
]
[0,1]
[0,1]的值,然后将结果分为2份,各自为
C
C
C个通道,即
w
N
,
w
N
L
∈
R
C
w_N,w_{NL}\in\mathbb{R}^C
wN,wNL∈RC,并分别与对应的
F
N
L
i
、
F
L
i
F_{NL}^i、F^i_L
FNLi、FLi进行元素相乘得到最终的结果
F
C
A
B
i
F^i_{CAB}
FCABi。
整个融合过程的数学表达式如下:
{
v
=
G
l
o
b
a
l
P
o
o
l
i
n
g
(
F
N
L
i
+
F
L
i
)
,
w
N
L
,
w
L
=
s
o
f
t
m
a
x
(
[
H
F
C
1
(
v
)
,
H
F
C
2
(
v
)
]
)
,
F
C
A
B
i
=
F
N
L
i
⋅
w
N
L
+
F
L
i
⋅
w
L
.
(7)
\begin{cases} v = {\color{mediumorchid}GlobalPooling}(F_{NL}^i + F^i_L),\\ w_{NL},w_L = softmax([\mathcal{H}_{FC}^1(v),\mathcal{H}^2_{FC}(v)]),\\ F^i_{CAB} = F^i_{NL}\cdot w_{NL} + F^i_L\cdot w_L.\tag{7} \end{cases}
⎩⎪⎨⎪⎧v=GlobalPooling(FNLi+FLi),wNL,wL=softmax([HFC1(v),HFC2(v)]),FCABi=FNLi⋅wNL+FLi⋅wL.(7)Note:
- 这里 w N , w N L w_N,w_{NL} wN,wNL就起着选择合适的局部注意力和全局注意力的分配方案的作用。
- 两个输出的通道注意力并不独立,因为softmax把2个过程放一起运算的,而后面要讲的Local-Attention中2个输出的通道注意力是相互独立的。
- [ ⋅ , ⋅ ] [\cdot, \cdot] [⋅,⋅]表示concat。
- 全局平均池化其实就是平均池化,只不过它是在在整张feature map上进行平均计算的,我们只需要输入最终输出的size,他就会自动计算所需要的卷积核大小以及stride等信息来最终输出通道数不变且最终大小为size的张量,具体参考Pytorch nn.AdaptiveAvgPool2d。
- 融合过程是可学习的!
为了验证融合的效果,作者使用热度图来反映,具体热值
h
h
h定义如下:
h
=
1
M
∑
m
=
1
M
a
m
,
a
m
=
{
1
,
w
L
m
≥
w
N
L
m
,
0
,
o
t
h
e
r
w
i
s
e
.
(8)
h = \frac{1}{M}\sum^M_{m=1} a_m,\\ a_m = \begin{cases} 1, w^m_L\ge w_{NL}^m,\\ 0, otherwise \end{cases}.\tag{8}
h=M1m=1∑Mam,am={1,wLm≥wNLm,0,otherwise.(8)其中
M
M
M为
w
L
w_L
wL的长度;
h
h
h反映了对两种注意力的偏好,就像投票一样。
最终热度图结果如下:

热度图反应的是对于最终结果的贡献大小,我们的目标就是想要知道最终融合的feature map中某一块区域到底是局部注意力贡献的多还是全局注意力贡献的多。
- 在上图中,颜色越鲜明表示此处局部注意力的贡献越大(或者说局部注意力的需求越大),反之则全局注意力的贡献越大。
- 此外,我们发现较大的局部注意力的贡献范围主要是集中在一些细节纹理区域,比如树叶、山峰;而全局注意力的贡献范围都是一些较大范围的重复性很高的区域,比如大海的海面。
3.3 Local Attention submodule
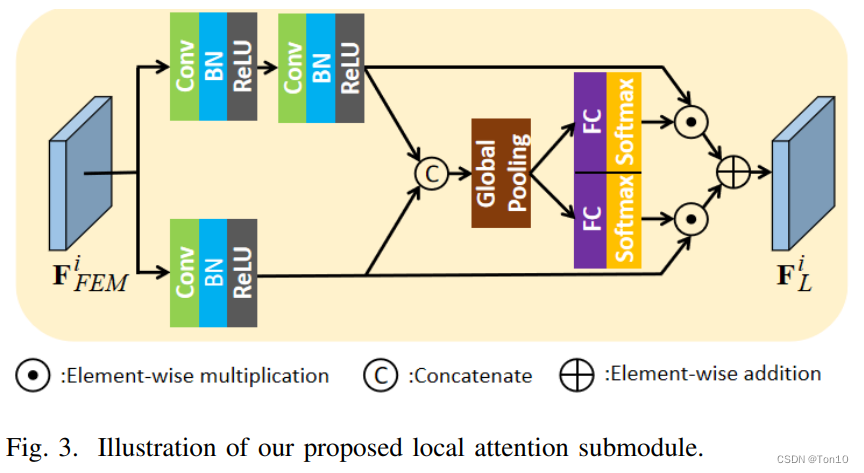
上图就是局部注意力子网络,作者设计了输出了2种不同感受野的分支,仍然是基于channel-wise的注意力机制来选择不同的感受野方案。和融合子网络的channel-wise注意力机制不同的是,两个输出的注意力通道是独立的,各自使用softmax来获取各自的注意力,最后结果进行元素级相加。
该子网络的注意力是通过局部操作产生的,其数学表达式为:
F
L
i
=
H
L
(
F
F
E
M
i
)
.
F^i_L = \mathcal{H}_L(F^i_{FEM}).
FLi=HL(FFEMi).
3.4 Non-local Attention submodule
Comparison and Analysis
\colorbox{violet}{Comparison and Analysis}
Comparison and Analysis
接下来我们先对目前的一些全局注意力机制进行比较,具体如下图所示:
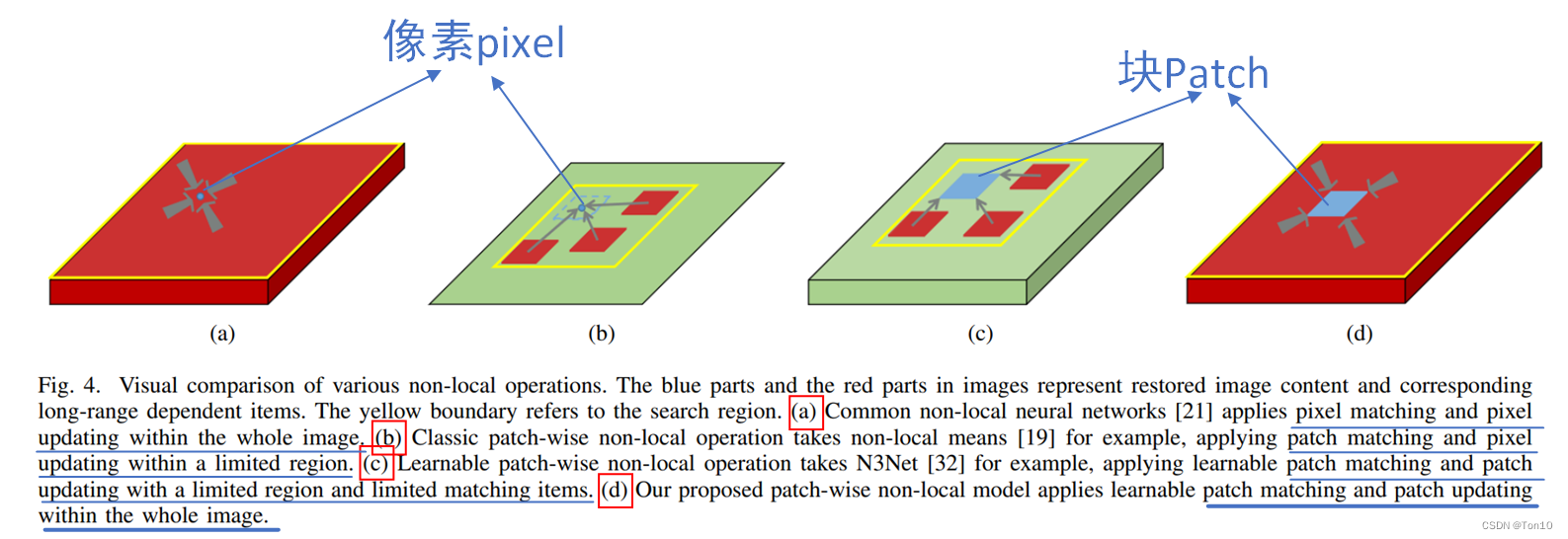
蓝色区域表示为待重建区域;红色区域表示为相关长距离依赖区域;黄色区域表示搜索区域。
我们分3个指标来进行对比:①全局注意力是基于像素还是patch;②注意力机制的更新是基于像素还是patch,即公式(1)中的
x
i
^
\hat{x_i}
xi^;③搜索范围是窗口还是全部图像。
- (a):注意力基于像素pixel;每次更新像素pixel;搜索区域为整张图像。
- (b):注意力基于块patch;但是每次更新只更新patch中间那个像素值;搜索区域为窗口。
- (c):注意力基于块patch;每次更新块patch;搜索区域为窗口。
- (d):这是本文提出的全局注意力模块,其基于块patch;每次更新块patch;搜索区域为整张图像。
Patch-wise Non-local Attention Model \colorbox{lightseagreen}{Patch-wise Non-local Attention Model} Patch-wise Non-local Attention Model
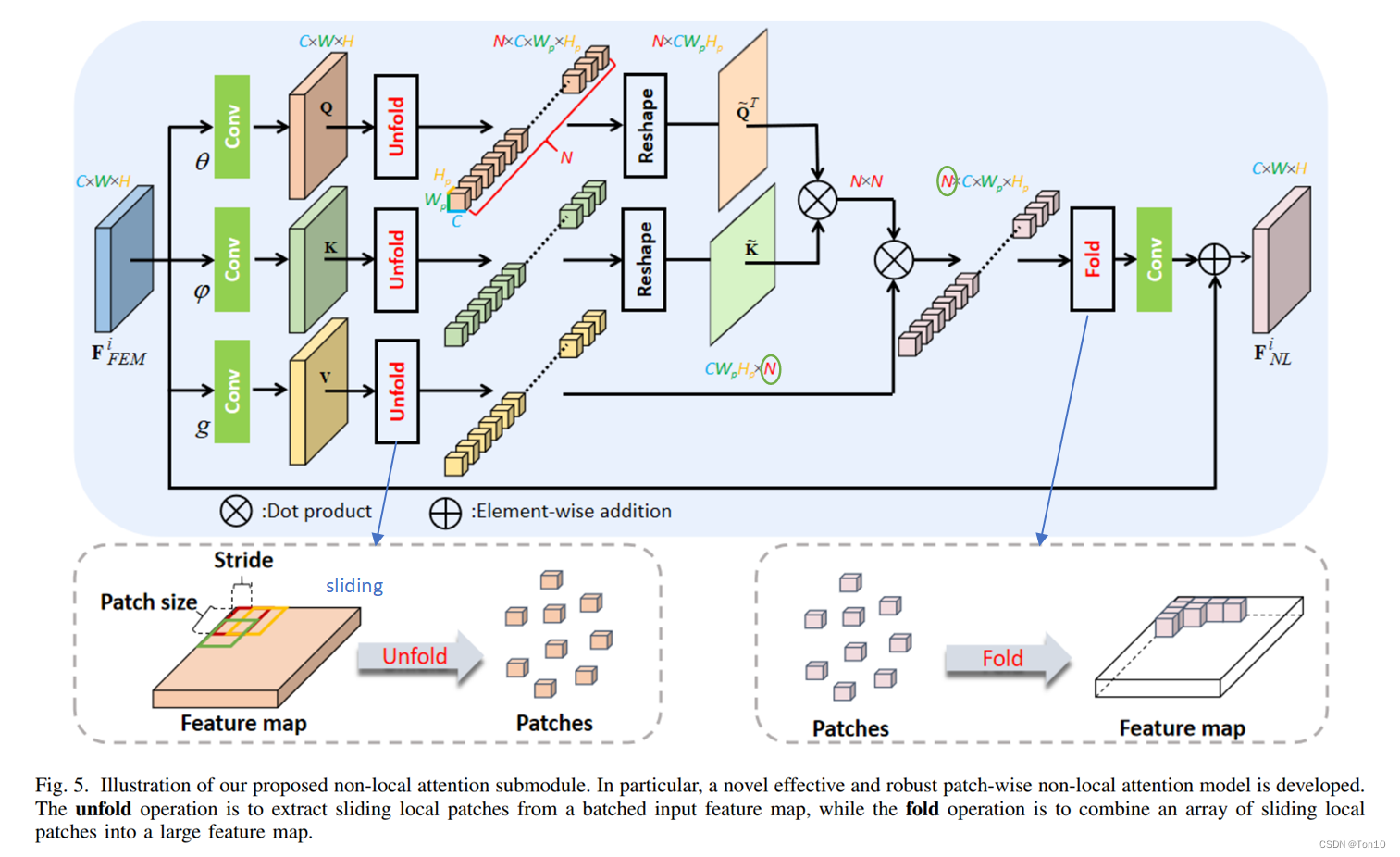
上图就是本文提出的一种用于Vision的新型自注意力模块,这种结构和ViT是不同的。
①:设输入
F
F
E
M
i
∈
R
C
×
W
×
H
F^i_{FEM}\in\mathbb{R}^{C\times W\times H}
FFEMi∈RC×W×H,它先是使用3个独立的embedding function——
θ
(
⋅
)
、
φ
(
⋅
)
、
g
(
⋅
)
\theta(\cdot)、\varphi(\cdot)、g(\cdot)
θ(⋅)、φ(⋅)、g(⋅),各自的参数记为
W
θ
、
W
φ
、
W
g
W_\theta、W_\varphi、W_g
Wθ、Wφ、Wg,它们是
1
×
1
1\times 1
1×1的卷积层,用于输出
Q
、
K
、
V
Q、K、V
Q、K、V,具体表达式如下:
{
Q
=
θ
(
F
F
E
M
i
)
,
K
=
φ
(
F
F
E
M
i
)
,
V
=
g
(
F
F
E
M
i
)
.
(9)
\begin{cases} Q = \theta(F^i_{FEM}),\\ K = \varphi(F^i_{FEM}),\\ V = g(F^i_{FEM}).\tag{9} \end{cases}
⎩⎪⎨⎪⎧Q=θ(FFEMi),K=φ(FFEMi),V=g(FFEMi).(9)
②:接下来就是核心操作——unfold,其产生patch,和ViT那种直接讲图像分块的方式不同,本文的结构是利用滑动窗口的形式,以
s
s
s为步长来抽取patch,每个patch的size为
C
×
W
p
×
H
p
C\times W_p\times H_p
C×Wp×Hp;对于每一组都进行unfold,每一组包含
N
N
N个3D-patch(
N
≥
W
/
W
p
N\ge W/W_p
N≥W/Wp),具体如上图坐标小框所示。这种设计的好处在于它可以在全局注意力的基础上增加一定的局部相关性,因此其比ViT这种块与块之间不重叠的方式更加灵活,但是缺陷在于这样会增加计算量。
③接下来我们将
Q
、
K
Q、K
Q、K的3D-patch分别进行reshape,每一个patch都flatten为1D的向量,这样就可以获取
N
×
(
C
⋅
W
p
⋅
H
p
)
N\times (C\cdot W_p\cdot H_p)
N×(C⋅Wp⋅Hp)的2D矩阵
Q
~
、
K
~
\tilde{Q}、\tilde{K}
Q~、K~;
M
=
Q
^
K
^
T
M = \hat{Q} \hat{K}^T
M=Q^K^T就是注意力矩阵,其衡量不同3D-patch之间的相关性,其中
M
∈
R
N
×
N
M\in\mathbb{R}^{N\times N}
M∈RN×N。
接下来使用softmax对
M
M
M的每一行进行运算:
ϕ
(
Q
^
,
K
^
)
=
s
o
f
t
m
a
x
(
Q
^
K
^
T
)
.
(10)
\phi(\hat{Q},\hat{K}) = softmax(\hat{Q} \hat{K}^T).\tag{10}
ϕ(Q^,K^)=softmax(Q^K^T).(10)
④:最后我们将
ϕ
\phi
ϕ看成
V
V
V的权重进行加权求和。具体而言,根据公式(1),
ϕ
\phi
ϕ的每一行都分别和
V
V
V进行元素加权求和得到结果
x
^
i
∈
R
C
×
W
p
×
H
p
\hat{x}_i\in\mathbb{R}^{C\times W_p\times H_p}
x^i∈RC×Wp×Hp。因此最后将多行结果进行fold,即上图右下小框所示,为了获取同样size的输出
C
×
H
×
W
C\times H\times W
C×H×W,直接硬拼会造成溢出,因此重叠部分去平均处理;Fold操作可以看成是unfold的相反操作。
⑤:最后接一个卷积层以及和输入端相加来减轻残差训练的压力以及避免卷积层造成的信息损失。
小结一下:
- 本文提出的自注意力子网络和ViT提出的自注意力网络是两种类型。
- 本文提出的自注意力子网络由于unfold的时候采用了 s ≤ W p s\leq W_p s≤Wp的滑动窗口来提取patch,因此其一定程度上增加了局部相关性。
- ViT提出的自注意力网络是可学习的,是因为有3个卷积层对输入做运算;而本文的网络也是可学习的,是因为初始阶段采用3个 1 × 1 1\times 1 1×1的卷积层,因此本文提出的自注意力模型可以产生可学习的patch!
- 如果把 1 × 1 1\times 1 1×1卷积层 θ 、 φ 、 g \theta、\varphi、g θ、φ、g替换成更大size的卷积核,则3D-patch们将拥有更多的从卷积这种局部操作中获取的局部相关性,它们会带着局部相关性去做全局相关性,这样会有利于一些非常需要局部相关性的重建任务,比如说超分。Video Super-Resolution Transformer这篇文章就采用 3 × 3 3\times 3 3×3的 θ 、 φ 、 g \theta、\varphi、g θ、φ、g来利用局部相关性和全局相关性,这样既能利用细节区域来提升重建表现力,又可以拥有较大的感受野来克服大运动问题。
- ViT的出现延申了Transformer在计算机视觉任务上的应用,但是其直接在
image-wise上的不重叠分块势必会破坏原图上的一些空间结构,而本文提出的COLA-Net结构其自注意力模块在feature-wise上按步长为 s s s进行重叠分块,这不仅保留了一些空间结构,而且增加了一定的局部相关性。两者的对比如下图所示: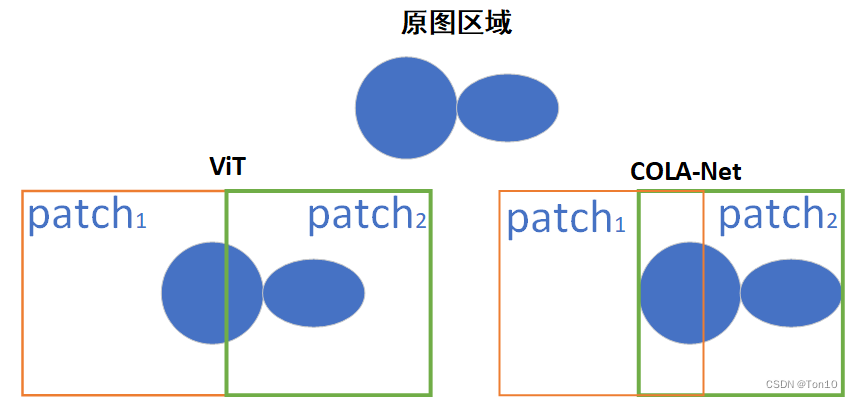
作者为了证明上述自注意力网络可以比Figure 4(a)的方法捕获更多有用的长距离依赖信息,将2者进行比较,热度图如下:

可以看出,像素级的注意力机制会造成很多没有用的依赖。
4 Experiments
略
5 Conclusion
- 本文是首篇将局部注意力和全局注意力一起融合来解决图像重建任务,并且融合过程是可学习的。
- 作者使用channel-wise的局部注意力子网络和patch-wise的自注意力子网络使用channel-wise注意力融合网络进行结合,以这样的框架结构为核心,推出了
Collaborative Attention Network(COLA-Net)。 - 作者推出了一种产生自注意力的新结构,和ViT不同,该网络可以产生可学习的patch。

















 1412
1412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









