










Hello,大家好~
今天咱们拿出来比较重要的一块和大家分享,那就是机器学习中的优化算法。
优化算法在机器学习中至关重要,它们决定了模型参数的更新方式,直接影响着模型的收敛速度和性能表现。选择合适的优化算法可以加快模型的训练速度、提高模型的准确性,并且对于处理大规模数据集和复杂模型具有重要意义。
今天涉及到内容包括以下:
-
梯度下降算法
-
动量梯度下降
-
Nesterov加速梯度
-
AdaGrad
-
RMSProp
-
Adam
-
AdaDelta
-
Nadam
-
L-BFGS
-
CMA-ES
梯度下降算法(Gradient Descent)
原理:梯度下降算法通过迭代地调整模型参数,以使损失函数逐步减小。每一步调整的方向是当前点的梯度负方向,调整的步长由学习率决定。
公式:

核心代码:
def gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
for i in range(num_iters):
gradient = X.T @ (X @ theta - y) / m
theta = theta - alpha * gradient
return theta动量梯度下降(Gradient Descent with Momentum)
原理:在梯度下降的基础上加入动量项,使得优化路径上的振荡减小,加速收敛。
公式:

核心代码:
def momentum_gradient_descent(X, y, theta, alpha, beta, num_iters):
m = len(y)
v = np.zeros_like(theta)
for i in range(num_iters):
gradient = X.T @ (X @ theta - y) / m
v = beta * v + (1 - beta) * gradient
theta = theta - alpha * v
return thetaNesterov加速梯度(Nesterov Accelerated Gradient, NAG)
原理:在动量梯度下降的基础上,提前计算未来位置的梯度,提高收敛速度。
公式:
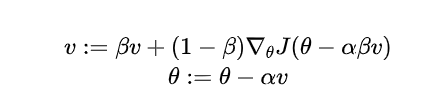
核心代码:
def nesterov_accelerated_gradient(X, y, theta, alpha, beta, num_iters):
m = len(y)
v = np.zeros_like(theta)
for i in range(num_iters):
temp_theta = theta - alpha * beta * v
gradient = X.T @ (X @ temp_theta - y) / m
v = beta * v + (1 - beta) * gradient
theta = theta - alpha * v
return thetaAdaGrad(Adaptive Gradient Algorithm)
原理:根据每个参数的历史梯度自适应地调整学习率,适合处理稀疏数据。
公式:

核心代码:
def adagrad(X, y, theta, alpha, num_iters, epsilon=1e-8):
m = len(y)
G = np.zeros_like(theta)
for i in range(num_iters):
gradient = X.T @ (X @ theta - y) / m
G += gradient ** 2
theta = theta - alpha / (np.sqrt(G + epsilon)) * gradient
return thetaRMSProp(Root Mean Square Propagation)
原理:改进了AdaGrad,通过使用梯度的指数加权移动平均值来调整学习率。
公式:
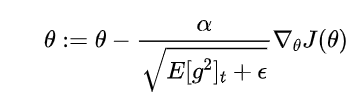
核心代码:
def rmsprop(X, y, theta, alpha, beta, num_iters, epsilon=1e-8):
m = len(y)
E_g2 = np.zeros_like(theta)
for i in range(num_iters):
gradient = X.T @ (X @ theta - y) / m
E_g2 = beta * E_g2 + (1 - beta) * gradient ** 2
theta = theta - alpha / (np.sqrt(E_g2 + epsilon)) * gradient
return thetaAdam(Adaptive Moment Estimation)
原理:结合了动量和RMSProp的优点,使用梯度的动量估计和平方梯度的加权平均来调整学习率。
公式:
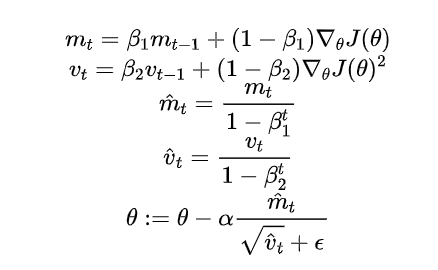
核心代码:
def adam(X, y, theta, alpha, beta1, beta2, num_iters, epsilon=1e-8):
m = len(y)
m_t = np.zeros_like(theta)
v_t = np.zeros_like(theta)
for t in range(1, num_iters + 1):
gradient = X.T @ (X @ theta - y) / m
m_t = beta1 * m_t + (1 - beta1) * gradient
v_t = beta2 * v_t + (1 - beta2) * gradient ** 2
m_t_hat = m_t / (1 - beta1 ** t)
v_t_hat = v_t / (1 - beta2 ** t)
theta = theta - alpha * m_t_hat / (np.sqrt(v_t_hat) + epsilon)
return thetaAdaDelta
原理:对AdaGrad进行改进,克服了其学习率不断下降的问题,通过引入一个基于梯度的指数加权移动平均值来调整步长。
公式:
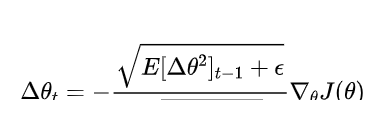
核心代码:
def adadelta(X, y, theta, rho, num_iters, epsilon=1e-8):
m = len(y)
E_g2 = np.zeros_like(theta)
E_delta_theta2 = np.zeros_like(theta)
for i in range(num_iters):
gradient = X.T @ (X @ theta - y) / m
E_g2 = rho * E_g2 + (1 - rho) * gradient ** 2
delta_theta = - (np.sqrt(E_delta_theta2 + epsilon) / np.sqrt(E_g2 + epsilon)) * gradient
theta = theta + delta_theta
E_delta_theta2 = rho * E_delta_theta2 + (1 - rho) * delta_theta ** 2
return thetaNadam(Nesterov-accelerated Adaptive Moment Estimation)
原理:结合了Nesterov加速和Adam算法的优点,通过提前计算未来位置的梯度和动量估计来加速收敛。
公式:
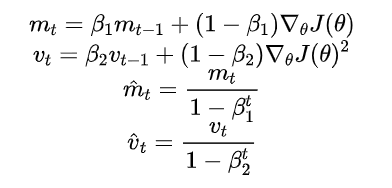
核心代码:
def nadam(X, y, theta, alpha, beta1, beta2, num_iters, epsilon=1e-8):
m = len(y)
m_t = np.zeros_like(theta)
v_t = np.zeros_like(theta)
for t in range(1, num_iters + 1):
gradient = X.T @ (X @ theta - y) / m
m_t = beta1 * m_t + (1 - beta1) * gradient
v_t = beta2 * v_t + (1 - beta2) * gradient ** 2
m_t_hat = m_t / (1 - beta1 ** t)
v_t_hat = v_t / (1 - beta2 ** t)
theta = theta - alpha * ((beta1 * m_t_hat + (1 - beta1) * gradient / (1 - beta1 ** t)) / (np.sqrt(v_t_hat) + epsilon))
return thetaL-BFGS(Limited-memory Broyden-Fletcher-Goldfarb-Shanno)
原理:一种拟牛顿法,适用于中小型数据集上的高维优化问题,使用历史梯度和参数更新信息来构建近似Hessian矩阵。涉及复杂的矩阵操作,使用历史梯度和参数更新信息来更新参数。
核心代码:
from scipy.optimize import fmin_l_bfgs_b
def lbfgs(X, y, theta):
def loss_and_grad(theta):
loss = np.sum((X @ theta - y) ** 2) / (2 * len(y))
gradient = X.T @ (X @ theta - y) / len(y)
return loss, gradient
theta, _, _ = fmin_l_bfgs_b(loss_and_grad, theta)
return thetaCMA-ES(Covariance Matrix Adaptation Evolution Strategy)
原理:一种进化策略优化算法,适用于全局优化和非凸优化问题,通过更新协方差矩阵来调整搜索策略。基于进化策略的迭代更新,涉及种群生成、选择、变异和协方差矩阵更新等。
核心代码:
import cma
def cma_es(X, y, theta):
def loss(theta):
return np.sum((X @ theta - y) ** 2) / (2 * len(y))
es = cma.CMAEvolutionStrategy(theta, 0.5)
es.optimize(loss)
return es.result.xbest这些代码示例为核心实现,实际应用中可能需要进一步调整和优化。
我这里有一份200G的人工智能资料合集:内含:990+可复现论文、写作发刊攻略,1v1论文辅导、AI学习路线图、视频教程等,看我简介处即可获取到!

















 4476
4476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









