






航识无涯学术致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。
2025深度学习发论文&模型涨点之——CNN+LSTM+Attention
近年来,卷积神经网络(CNN)与长短期记忆网络(LSTM)的融合架构在时序数据处理领域展现出显著优势,尤其在视频分析、气象预测、医疗诊断等复杂序列建模任务中取得了突破性进展。然而,传统CNN-LSTM模型对时空特征的动态交互建模能力仍受限于其静态权重分配机制。为此,注意力机制的引入通过动态特征加权策略,实现了关键时间步与空间区域的自主聚焦,显著提升了模型的可解释性与泛化性能。
论文精我整理了一些时间序列可解释性【论文+代码】合集,需要的同学公人人人号【航识无涯学术】发123自取。
论文精选
论文1:
Translating Math Formula Images to LaTeX Sequences Using Deep Neural Networks with Sequence-level Training
使用深度神经网络和序列级训练将数学公式图像翻译为LaTeX序列
方法
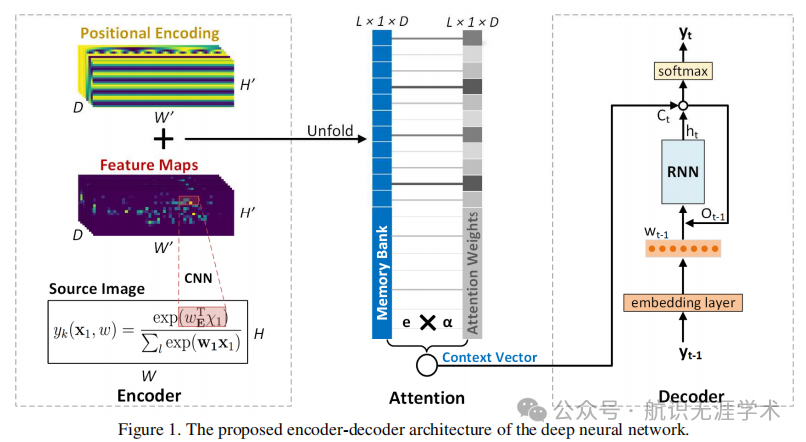
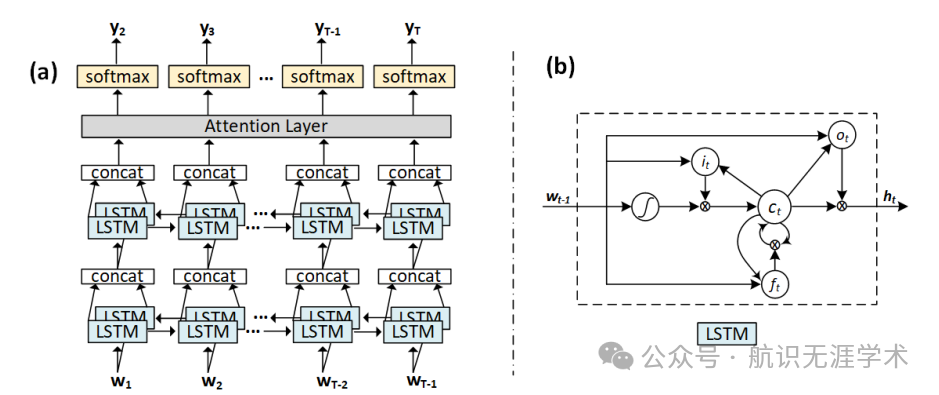
编码器-解码器架构:采用CNN作为编码器,将图像特征映射到特征图;使用堆叠双向LSTM作为解码器,结合软注意力机制将编码器输出翻译为LaTeX标记序列。
二维位置编码:在特征图上添加正弦位置编码,增强模型对数学符号二维空间关系的感知能力。
序列级训练:在完成基于最大似然估计(MLE)的逐标记训练后,使用基于策略梯度算法的序列级训练目标函数优化整体模型。
消除曝光偏差:在序列级训练中,通过关闭解码器的反馈环路(即使用预测的标记而不是真实标记作为下一步输入)来消除曝光偏差。
创新点
二维位置编码:通过增加正弦位置编码,模型能够更好地捕捉数学符号的二维空间关系,从而提高翻译准确性。
序列级训练:使用BLEU分数作为序列级训练目标函数,优化整个LaTeX序列的生成,相比逐标记训练,显著提高了模型在序列级别上的性能。
消除曝光偏差:通过在序列级训练中使用预测标记而不是真实标记,解决了训练和测试阶段输入不一致的问题,进一步提升了模型的泛化能力。
性能提升:在IM2LATEX-100K数据集上,使用序列级训练的模型在BLEU分数上达到了90.28%,图像编辑距离为92.28%,与未使用序列级训练的模型相比,BLEU分数提升了1.2%,图像编辑距离提升了1.19%。
论文2:
Stacked Attention Networks for Image Question Answering
用于图像问答的堆叠注意力网络
方法
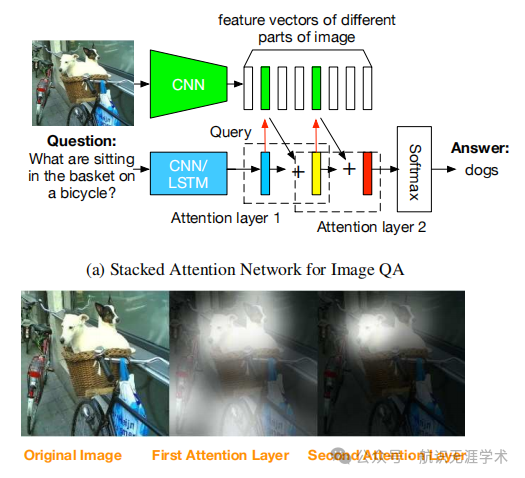
图像模型:使用CNN(如VGGNet)提取图像的高级特征表示,保留空间信息。
问题模型:使用LSTM或CNN提取问题的语义向量。
堆叠注意力模型:通过多层注意力机制逐步聚焦于图像中与问题相关的区域,最终结合图像特征和问题向量预测答案。
多步推理:通过多次查询图像,逐步缩小关注范围,最终定位到与答案最相关的区域。
创新点
堆叠注意力机制:通过多层注意力网络逐步聚焦于图像中的相关区域,相比单层注意力模型,能够更精确地定位答案相关的视觉线索。
多步推理:支持多步推理过程,能够处理复杂的图像问答任务,显著提高了模型的准确性和鲁棒性。
性能提升:在DAQUAR-ALL、DAQUAR-REDUCED、COCO-QA和VQA四个数据集上,两层堆叠注意力网络(SAN(2, CNN))的准确率分别达到了29.3%、46.2%、61.6%和57.6%,相比单层注意力网络(SAN(1, CNN)),在DAQUAR-ALL上准确率提升了0.4%,在DAQUAR-REDUCED上提升了1.0%,在COCO-QA上提升了1.4%,在VQA上提升了0.7%。

论文3:
Transformer in Transformer as Backbone for Deep Reinforcement Learning
作为深度强化学习骨干网络的Transformer in Transformer
方法
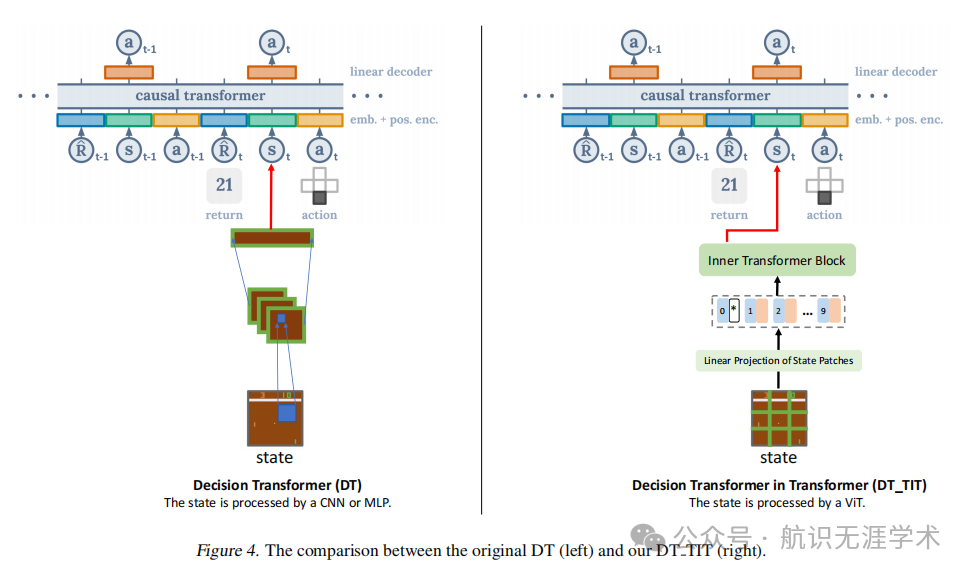
内Transformer:处理单个观测,学习观测的表示,捕捉重要的空间信息。
外Transformer:处理观测历史,捕捉多个连续观测之间的时间信息。
堆叠Transformer:将内Transformer和外Transformer级联,形成Transformer in Transformer(TIT)结构,提取时空表示用于决策。
增强TIT:通过在每个TIT块中融合空间和时间信息,并采用密集连接设计,进一步提升性能。
创新点
纯Transformer骨干网络:首次证明纯Transformer网络可以作为深度强化学习的骨干网络,无需混合其他网络模块。
时空表示提取:通过内Transformer和外Transformer的级联,有效提取观测的空间和时间信息,提升决策质量。
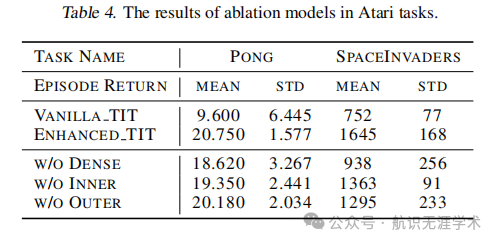
性能提升:在在线和离线强化学习设置中,增强TIT(Enhanced TIT)在多个任务上实现了与现有强基线相当或更好的性能。例如,在Atari任务中,增强TIT在Pong上的平均回报为20.75,比Vanilla TIT的9.60有显著提升;在COCO-QA数据集上,增强TIT的准确率达到了61.6%,比Vanilla TIT的59.6%有明显提升。
优化技能简化:TIT需要较少的优化技能,可以作为即插即用的骨干网络,与流行的强化学习库(如Stable-baseline3和d3rlpy)结合使用,无需复杂的优化技巧即可实现良好的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









