






2024深度学习发论文&模型涨点之——交叉注意力+特征融合
交叉注意力(Cross-Attention)和特征融合(Feature Fusion)是深度学习领域中两个重要的概念,它们在多模态学习、图像处理和目标检测等任务中发挥着重要作用。
-
端到端的ATFuse网络:提出了一种端到端的ATFuse网络,用于融合IV图像。该方法在多个数据集上表现出良好的效果和泛化能力。
-
差异信息注入模块(DIIM):基于交叉注意机制提出了一种差异信息注入模块(DIIM),可以分别探索源图像的独特特征。
-
交替公共信息注入模块(ACIIM):将交替公共信息注入模块(ACIIM)应用于所提出的框架中,其中公共信息在最终结果中得到充分保留。
小编整理了一些交叉注意力+特征融合【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“交叉注意力+特征融合”即可全部领取
论文精选
论文1:
DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object Detection
DynStatF:一种高效的激光雷达3D目标检测特征融合策略
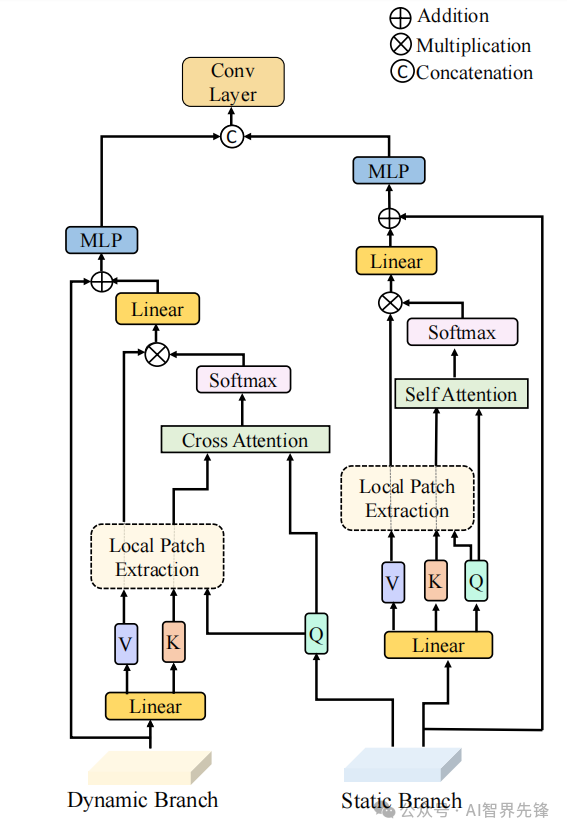
方法
-
双路径架构:提出了一种双路径架构,同时处理多帧(动态分支)和单帧(静态分支)激光雷达输入的特征。
-
邻域交叉注意力(NCA)模块:将静态分支的特征作为查询,动态分支的特征作为键(值)进行注意力计算,仅考虑邻域位置。
-
动态-静态交互(DSI)模块:在特征图变得密集的阶段,提供两个分支之间的全面交互。
创新点
-
双路径架构:DynStaF是首次尝试部署双流架构,用于从多帧和单帧激光雷达输入中提取和融合特征,提高了3D目标检测的性能。
-
邻域交叉注意力(NCA)模块:针对稀疏特征图设计,通过限制在邻域区域内的交叉注意力计算,减少了计算开销,提高了特征融合的质量。
-
动态-静态交互(DSI)模块:针对密集特征图设计,通过CNN-based DSI模块在每个像素位置进行综合交互,增强了特征的语义信息和位置准确性。
-
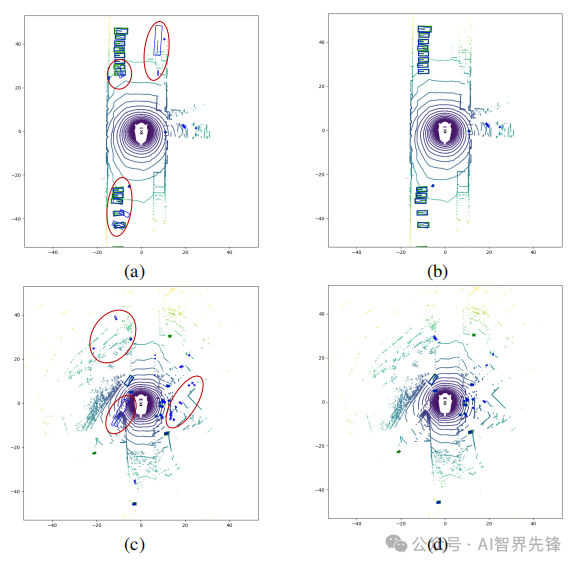
性能提升:在nuScenes数据集上,DynStaF将PointPillars的性能从57.7%提高到61.6%(NDS),与CenterPoint结合时,达到了61.0% mAP和67.7% NDS的领先性能。
论文2:
You Only Look One-level Feature
你只看一眼级别的特征
方法
-
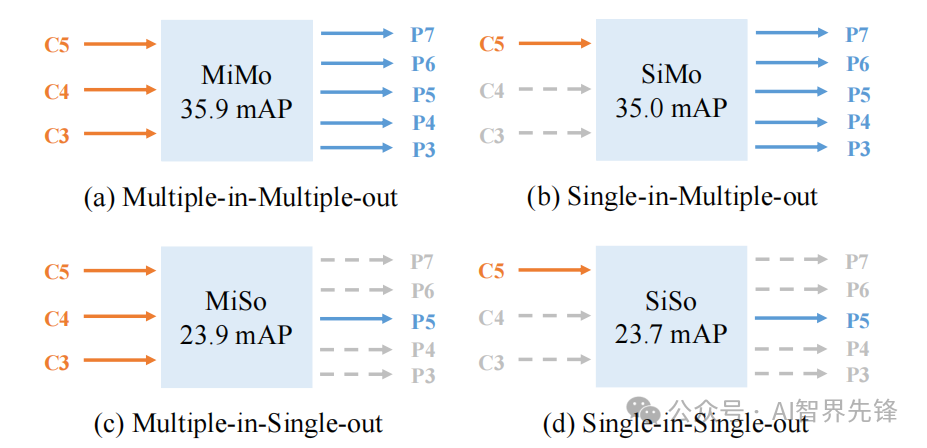
单级别特征检测:提出了一种不使用复杂特征金字塔的替代方法,仅利用一个级别的特征进行检测。
-
扩张编码器(Dilated Encoder):通过堆叠标准和扩张卷积来扩大C5特征的感受野,以覆盖所有对象的尺度。
-
统一匹配(Uniform Matching):提出了一种统一匹配策略,确保所有真实框能够均匀地与相同数量的正锚匹配,无论它们的大小如何。
创新点
-
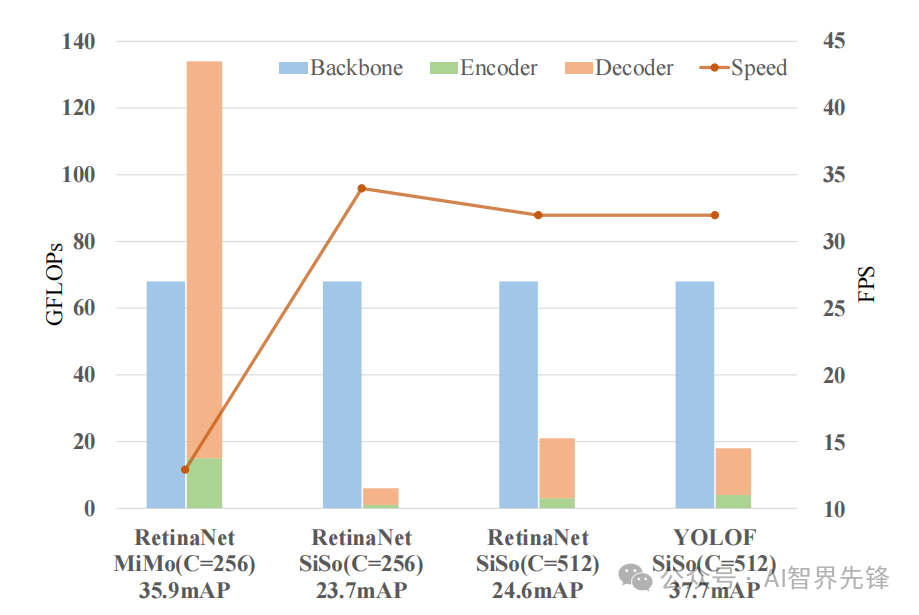
单级别特征检测:YOLOF证明了即使不使用特征金字塔,也能与具有特征金字塔的RetinaNet取得相当的结果,同时速度提高了2.5倍。
-
扩张编码器(Dilated Encoder):通过扩张卷积扩大了C5特征的感受野,使得单一级别的特征能够检测各种尺度的物体。
-
统一匹配(Uniform Matching):解决了由于单级别特征导致的正锚不平衡问题,确保了训练过程中所有真实框的平等参与。
-
性能提升:YOLOF在没有Transformer层的情况下,与DETR的性能相当,但训练周期缩短了7倍。
论文3:
ICAFusion: Iterative Cross-Attention Guided Feature Fusion for Multispectral Object Detection
ICAFusion:迭代交叉注意力引导的多光谱目标检测特征融合
方法
-
双交叉注意力变换器框架:提出了一种新的特征融合框架,用于同时建模全局特征交互和捕获模态间的互补信息。
-
迭代交互机制:受人类复习知识的过程启发,提出了一种迭代交互机制,以共享参数减少模型复杂性和计算成本。
-
跨模态特征增强(CFE)模块:使单模态能够从辅助模态中学习更多的互补信息。
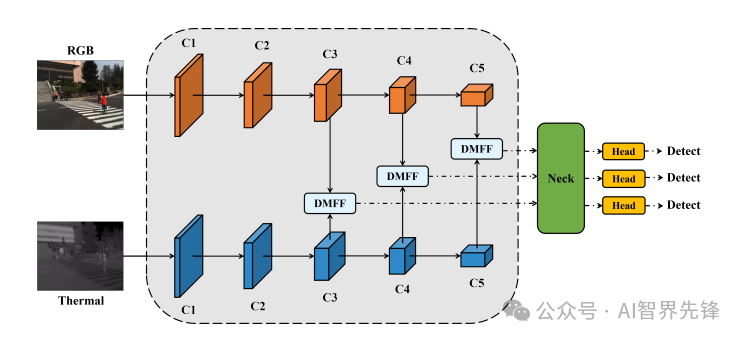
创新点
-
双交叉注意力变换器框架:通过查询引导的交叉注意力机制增强了对象特征的可区分性,提高了性能。
-
迭代交互机制:通过迭代学习策略,提高了模型性能,同时保持了参数数量不变,平衡了模型性能和复杂性。
-
跨模态特征增强(CFE)模块:与单变换器融合方法相比,提出的CFE模块仅使用辅助模态的查询来计算跨模态的相关性,降低了计算复杂度和参数数量。
-
性能提升:在KAIST、FLIR和VEDAI数据集上,提出的方法实现了优越的性能和更快的推理速度,适用于各种实际场景。
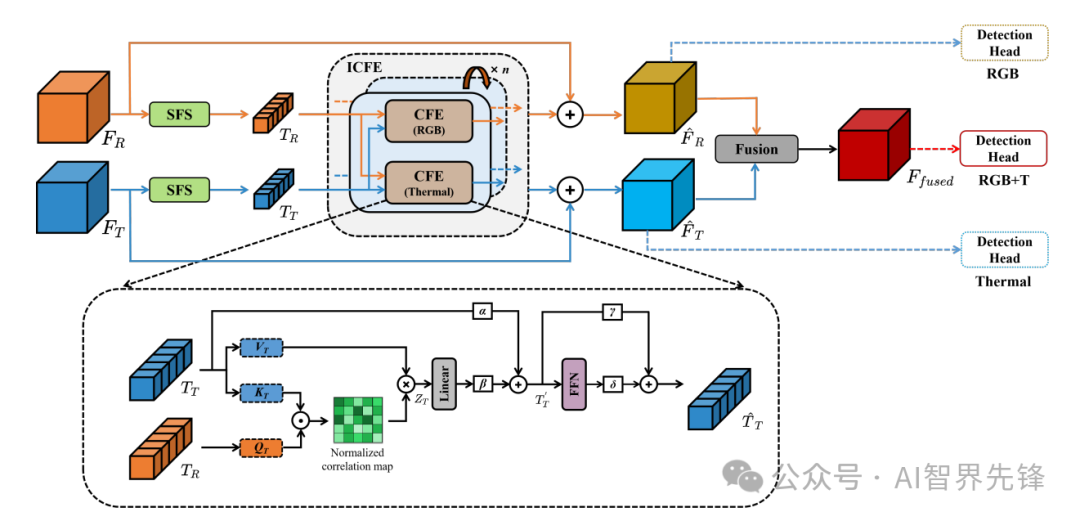
论文4:
Predicting Pedestrian Crossing Intention with Feature Fusion and Spatio-Temporal Attention
通过特征融合和时空注意力预测行人过街意图
方法
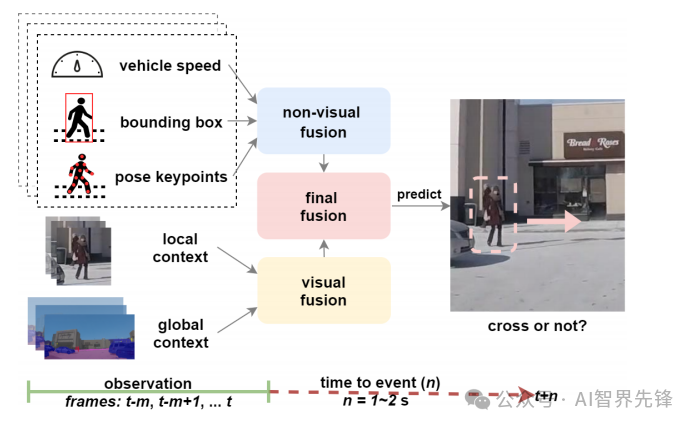
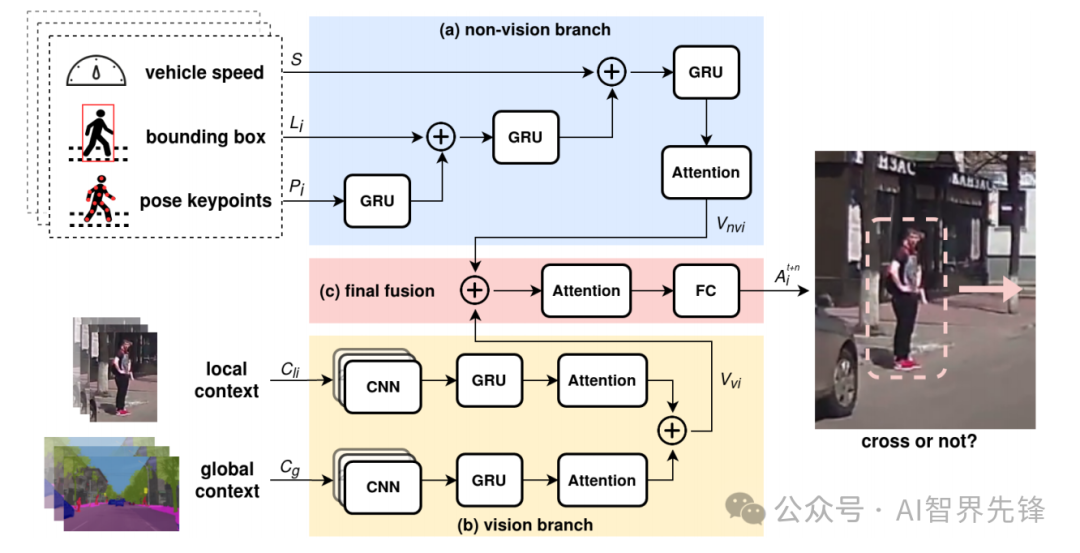
-
混合特征融合策略:提出了一种新的神经网络架构,用于融合不同的时空特征,包括RGB图像序列、语义分割掩码和自车速度。
-
时空注意力机制:使用注意力机制和递归神经网络堆栈来最优地融合不同的特征现象。
创新点
-
混合特征融合策略:通过比较不同的特征融合策略(早期、后期、层次或混合),确定了最佳模型布局。
-
时空注意力机制:通过注意力模块,模型能够更好地记忆序列源,提高了行人过街意图预测的准确性。
-
性能提升:在JAAD行人行为预测基准测试中,提出的方法实现了最先进的性能,与现有方法相比,在准确性、AUC、F1分数、精确度和召回率方面都有显著提高。
小编整理了交叉注意力+特征融合论文代码合集
需要的同学
回复“交叉注意力+特征融合”即可全部领取

















 2367
2367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









