






2024深度学习发论文&模型涨点之——多模态+注意力机制
多模态(multimodal)结合了来自不同模态(如视觉、文本、音频等)的信息,以提高机器学习任务的性能。注意力机制(attention)在多模态融合中扮演着重要角色,它可以帮助模型识别和聚焦于不同模态中最相关的信息。
-
多模态融合网络(Multimodal Fusion Network):有研究提出了一个多模态融合网络,该网络使用多头自注意力机制来最小化不同模态之间的噪声干扰,并利用局部区域特征表示之间的相关性来提取互补信息。
-
多模态注意力合并(Multimodal Attention Merging, MAM):另一项研究介绍了MAM,这是一种促进从资源丰富模态(文本和图像)到资源受限领域(语音和音频)的知识转移的方法。
-
MAM零样本(zero-shot)范式:显著降低了自动语音识别(ASR)模型的字错误率(WER)和音频事件分类(AEC)模型的分类错误率。
-
多模态注意力瓶颈(Attention Bottlenecks for Multimodal Fusion):Google Research的研究提出了Multimodal Bottleneck Transformer(MBT),利用自注意力在中间层对多模态数据进行信息交换,并将最需要分享的信息编码在一个4维隐向量中,以实现信息交换。它可以帮助模型更好地理解和融合来自不同模态的信息,从而提高各种任务的性能。
小编整理了一些多模态+注意力机制【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“多模态+注意力机制”即可全部领取
论文精选
论文1:
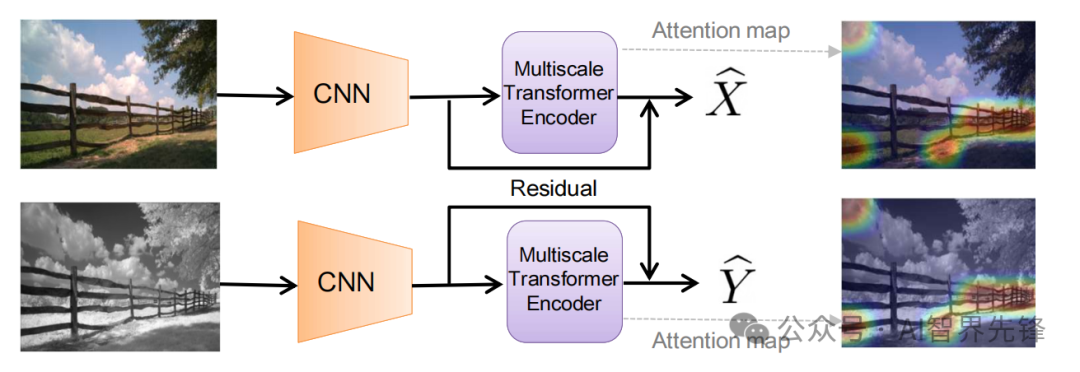
Attention Bottlenecks for Multimodal Fusion
多模态融合的注意力瓶颈
方法
-
变换器架构:提出了一种基于变换器的新型架构,使用“融合瓶颈”在多层之间进行模态融合。
-
融合瓶颈:与传统的成对自注意力相比,模型强制不同模态之间的信息通过少量的瓶颈潜在单元传递,要求模型收集并压缩每个模态中的相关信息,并只共享必要的信息。
-
多头自注意力(MSA)和多层感知机(MLP):在变换器层中使用,通过残差连接应用。
-
跨模态注意力限制:提出了两种方法限制模型中的注意力流动,一种是在网络的后层限制跨模态流动,另一种是通过瓶颈单元在层内限制跨模态注意力流动。
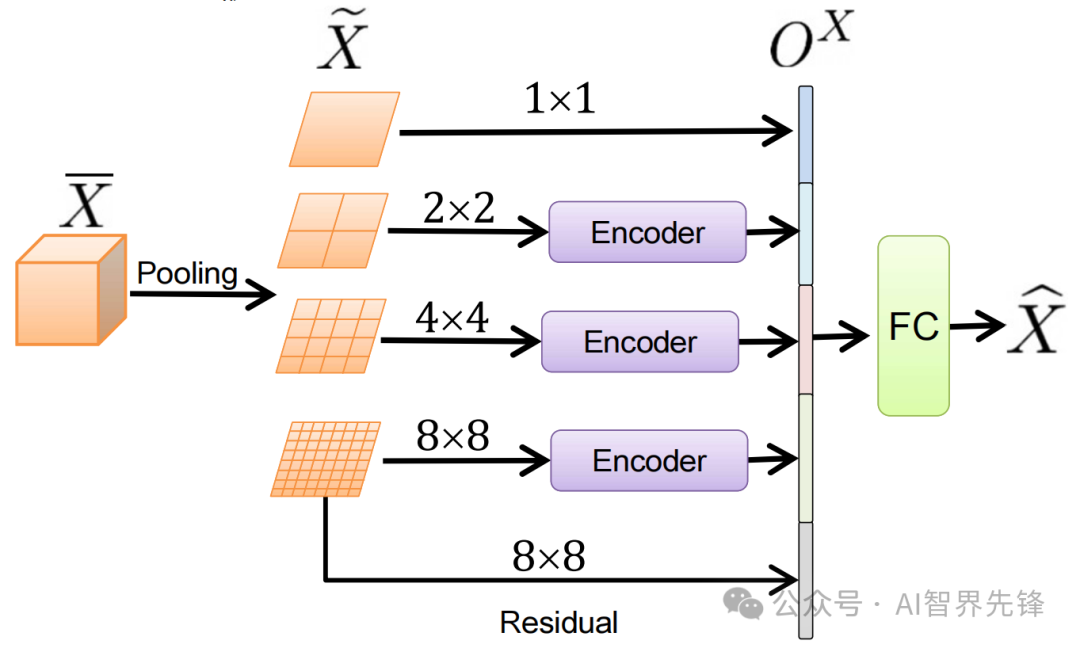
创新点
-
融合瓶颈策略:通过引入融合瓶颈,模型能够以更低的计算成本提高融合性能,与无限制的对应模型相比,在多个视听分类基准测试中取得了更好的结果,例如在AudioSet数据集上提升了5.9 mAP(12.7%的相对改进)。
-
减少计算复杂度:提出的瓶颈版本(MBT)在保持或提高性能的同时,减少了计算量,尤其是在早期融合模型中,比传统的跨模态注意力减少了超过2 mAP,且计算成本不到一半。
-
跨模态注意力限制:通过限制跨模态注意力流动,模型在层内必须通过瓶颈单元传递信息,这迫使模型从每个模态中提取和共享最相关的信息,从而提高了多模态融合的性能。
-
多模态融合的通用性:提出的模型和方法适用于不同类型和数量的模态,具有很好的通用性和适应性。
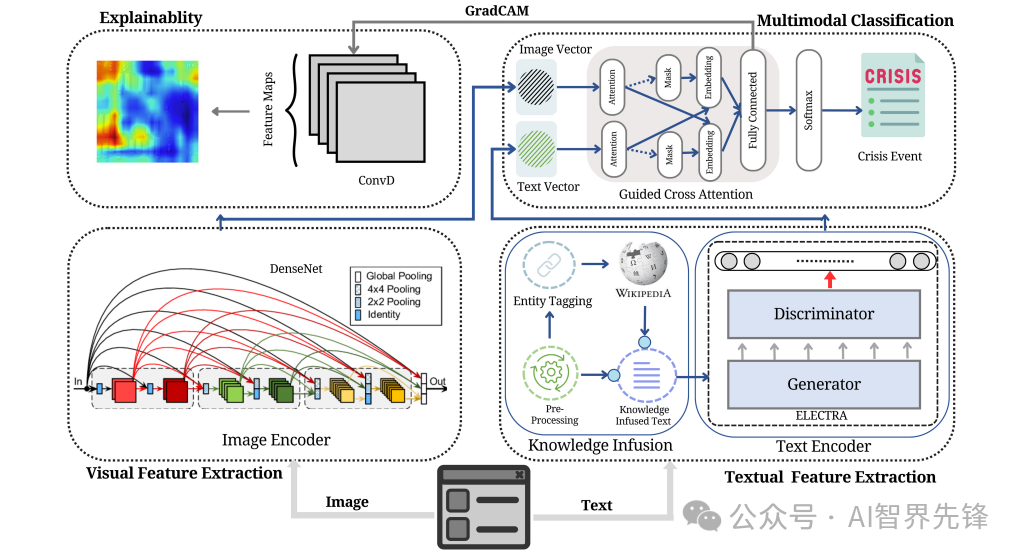
论文2:
FusionPainting: Multimodal Fusion with Adaptive Attention for 3D Object Detection
FusionPainting:用于3D目标检测的自适应注意力多模态融合
方法
-
多模态语义分割模块:基于2D和3D分割方法分别获取2D图像和3D LiDAR点云的语义信息。
-
自适应注意力模块:提出了一种基于注意力的语义融合模块,用于在体素级别自适应地融合来自不同传感器的语义信息。
-
3D目标检测器:将融合了语义标签的点云发送到3D检测器,以获得3D目标检测结果。
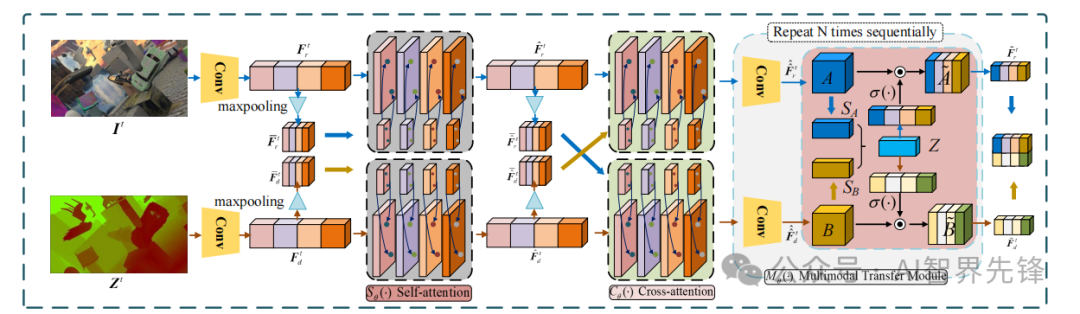
创新点
-
多模态融合框架“FusionPainting”:首次提出在语义层面融合不同类型的信息以提高3D目标检测性能。
-
自适应注意力模块:通过学习上下文特征,提出了在体素级别融合不同种类的语义信息的方法。
-
性能提升:在nuScenes测试基准上,提出的方法超过了其他最先进的方法,与仅使用点云的方法相比,检测性能显著提高。
-
检测器独立性:提出的“FusionPainting”与检测器无关,可以自由地用于其他3D目标检测器。
论文3:
MTAG: Modal-Temporal Attention Graph for Unaligned Human Multimodal Language Sequences
MTAG:用于未对齐人类多模态语言序列的模态-时间注意力图
方法
-
异构图构建:将未对齐的多模态序列数据转换为具有异构节点和边的图,捕获跨模态和时间的丰富交互。
-
MTAG融合操作:设计了一种新颖的图融合操作,以及动态修剪和读出技术,高效处理模态-时间图并捕获各种交互。
-
动态修剪技术:通过学习图中的重要交互,动态修剪不重要的边,以提高模型的参数效率和可解释性。
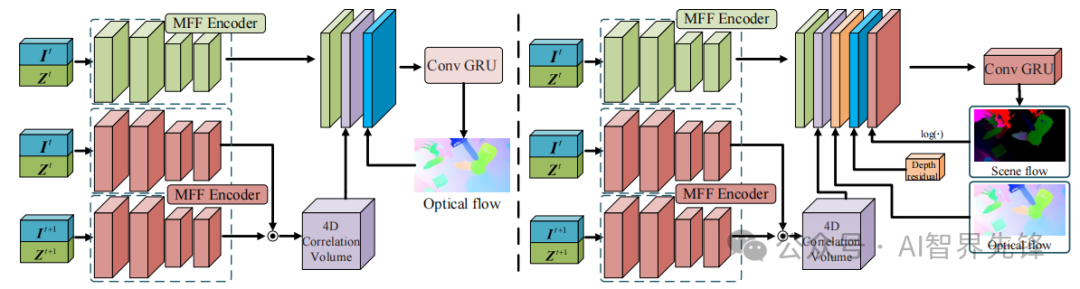
创新点
-
无需预对齐:MTAG能够处理无需预对齐的异步分布的多模态序列数据,打破了以往方法一次只建模两个模态交互的限制。
-
参数效率:与基于变换器的模型MulT相比,MTAG使用的参数数量大幅减少(仅6.25%),但在两个公共数据集上实现了相似甚至更优的性能。
-
动态修剪技术:通过动态修剪技术,MTAG在保持性能的同时减少了计算资源的使用,提高了模型的运行效率。
-
多模态交互学习:MTAG通过学习关注图中的重要交互,实现了对多模态语言数据的更深层次理解,特别是在情感分析和情绪识别任务中表现突出。
论文4:
SyCoCa: Symmetrizing Contrastive Captioners with Attentive Masking for Multimodal Alignment
SyCoCa:通过注意力掩蔽对称化对比性描述者以实现多模态对齐
方法
-
对比性描述者(CoCa):将对比性语言-图像预训练(CLIP)和图像描述(IC)整合到一个统一框架中。
-
文本引导的掩蔽图像建模(TG-MIM):在ITC和IC头的基础上扩展,增加了基于文本的图像重建能力。
-
注意力掩蔽策略:在进行局部交互时,选择有效的图像块进行交互,以处理图像局部内容可能与文本描述不相关的问题。
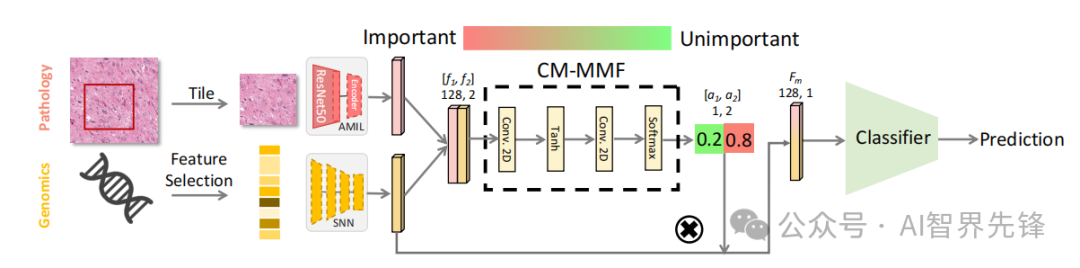
创新点
-
双向局部交互:通过引入TG-MIM头,实现了图像到文本和文本到图像的双向局部交互,提升了细粒度的多模态对齐能力。
-
注意力掩蔽策略:在图像和文本的局部交互中,通过计算图像标记和文本标记之间的相似性来选择相关的图像块,提高了模型对相关信息的聚焦能力。
-
多模态任务性能提升:在五个视觉-语言任务上进行了广泛的实验,包括图像-文本检索、图像描述、视觉问答以及零样本/微调图像分类任务,验证了所提方法的有效性。例如,在Flickr-30k数据集的图像-文本检索任务上,与CoCa相比,mTR/mIR分别提升了5.1%/3.7%资料
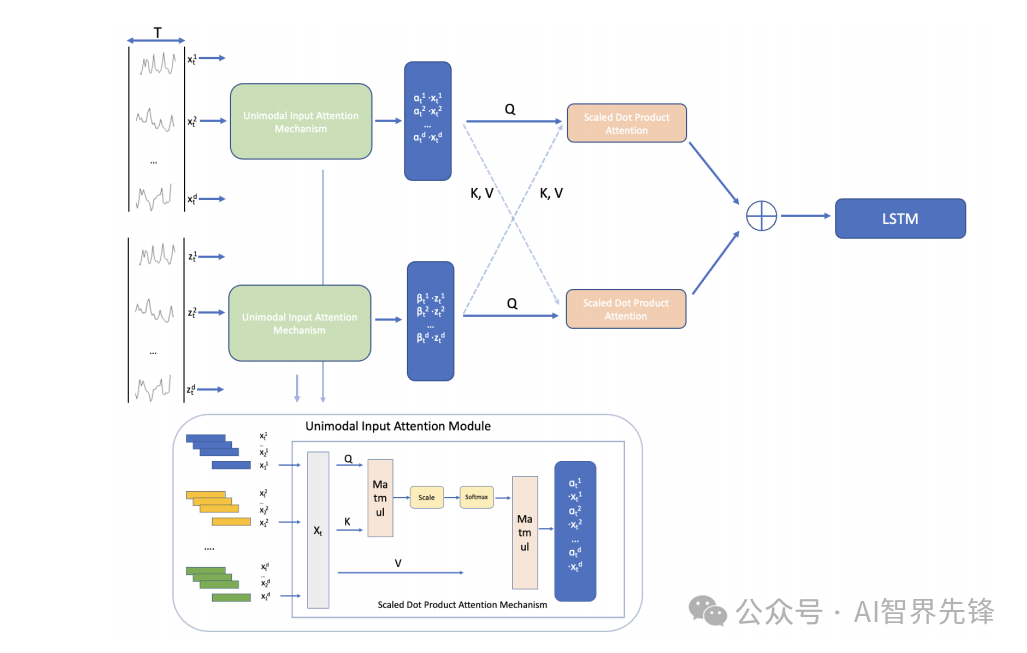
小编整理了多模态+注意力机制论文代码合集
需要的同学
回复“多模态+注意力机制”即可全部领取

AI智界先锋
AI智界先锋致力于成为您在人工智能领域的领航者,定期更新人工智能领域的重大新闻与最新动态,和您一起探索AI的无限可能。立即关注我们,开启您的AI学习之旅!
107篇原创内容

















 315
315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









