






大模型训练面临的核心矛盾是:模型参数量指数级增长与GPU显存容量线性提升之间的鸿沟。本文系统解析参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)技术路线,揭示从LoRA到QLoRA的显存压缩逻辑演进,为实验室资源受限环境下的模型训练提供解决方案。
一、显存瓶颈的本质与PEFT技术兴起
大模型全参数微调(Full Fine-Tuning)的显存消耗主要来自三部分:
- 参数存储:175B参数模型需700GB显存(FP32)
- 梯度缓存:反向传播需存储梯度张量,显存占用与参数规模成正比
- 优化器状态:Adam优化器需维护动量和方差,显存开销为参数量的2倍
传统方案采用混合精度训练(FP16/FP32)仅能降低约50%显存占用,而PEFT技术通过冻结主干+微调子结构,将显存需求压缩至10%以下。
二、技术演进路线与核心突破
2.1 LoRA:低秩适配的奠基性工作
核心思想:
-
冻结预训练模型权重矩阵:

-
注入低秩矩阵:
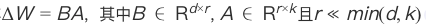
显存优化效果:
- 可训练参数量减少98%(r=8时)
- 175B模型微调显存需求从1.2TB降至35GB
局限性:
- 固定秩选择缺乏理论指导(过小导致欠拟合,过大弱化压缩效果)
- 无法自适应不同层对秩的敏感性差异
2.2 AdaLoRA:动态秩分配机制
创新点:
- 奇异值阈值剪枝:定期裁剪ΔW中贡献度低的奇异值
- 敏感度感知分配:根据梯度幅值动态调整各层秩分配预算
性能提升:
- 在同等显存占用下,GLUE基准准确率提升2.1%
- 秩利用率(有效奇异值比例)从LoRA的63%提升至89%
2.3 QLoRA:量化技术的革命性突破
三级压缩策略:
- 4-bit量化:将预训练权重量化为NF4(Normalized Float4)格式,存储占用减少75%
- 分页优化器:将优化器状态分块加载至显存,避免OOM(内存溢出)
- 双阶段量化:
- 阶段一:32→8bit量化用于前向传播
- 阶段二:8→4bit量化用于权重存储
实测效果:
- 65B模型微调仅需48GB显存(RTX 4090可运行)
- 量化误差导致性能损失<1%(VS FP16训练)
三、关键技术对比与适用场景
| 技术指标 | LoRA | AdaLoRA | QLoRA |
|---|---|---|---|
| 压缩率 | 10%~15% | 8%~12% | 4%~6% |
| 可训练参数量 | 0.1%~0.5% | 0.05%~0.3% | 0.01%~0.1% |
| 量化支持 | ✗ | ✗ | ✔️ (4/8bit) |
| 硬件兼容性 | 全系列GPU | 全系列GPU | Ampere+ |
| 适用场景 | 中小模型 | 领域适配 | 千亿模型 |
四、挑战与未来方向
4.1 现存技术瓶颈
- 量化粒度矛盾:粗粒度量化降低显存但引入误差,细粒度量化丧失压缩优势
- 动态秩分配开销:AdaLoRA的敏感度分析增加15%计算耗时
- 跨设备兼容性:QLoRA依赖Ampere架构的Tensor Core加速4bit运算
4.2 前沿探索方向
- 混合量化策略:关键层FP16+非关键层4bit的异构量化架构
- 梯度稀疏化:结合Top-k梯度压缩(稀疏率>95%),进一步降低反向传播显存
- 硬件协同设计:专用AI芯片内置PEFT计算单元,实现算法-硬件联合优化
五、实践建议与工具推荐
- LoRA实战技巧:
- 优先微调Attention层(效果贡献占比70%+)
- 设置秩r=8作为基准,按层类型动态调整
- QLoRA部署要点:
# 4bit量化加载示例
model = AutoModelForCausalLM.from_pretrained(
"meta-llama/Llama-2-7b",
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
device_map="auto"
)
- 使用
bitsandbytes库实现量化 - 启用
pad_token_id避免分页错误
- 监控工具推荐:
- nvidia-smi显存实时监控
- PyTorch Memory Snapshot分析碎片分布
- DeepSpeed Memory Profiler定位显存瓶颈
总结
从LoRA到QLoRA的技术演进,本质是通过算法创新突破硬件边界。未来研究需在三个方面深化:
- 理论层面:建立低秩近似的误差上界模型
- 工程层面:开发跨框架的量化推理引擎
- 生态层面:构建开源PEFT模型库加速技术落地



















 2230
2230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









