






一、混合调度系统设计背景
1.1 异构算力调度挑战
当前AI训练场景呈现多模态计算需求叠加的特征,涵盖大规模分布式训练、实时推理服务、科学计算等差异化负载类型。传统单一调度系统面临三大核心矛盾:
- 资源碎片化:固定配额分配导致GPU利用率不足40%
- 调度延迟高:单一调度器处理万级任务队列时延迟超过500ms
- 异构兼容差:无法有效协调FPGA/ASIC等新型计算单元
1.2 混合架构优势
Kubernetes与Slurm的协同工作模式突破单系统局限:
- K8s容器化编排:保障在线推理服务的SLA(服务等级协议)
- Slurm高性能调度:支持MPI作业的拓扑感知分配
- 统一资源池:通过动态资源分配(DRA)实现跨域资源共享
二、多集群GPU动态分配算法
2.1 核心设计原理
动态分配算法需满足三大约束条件:
- 实时性:响应时间<100ms(满足在线服务需求)
- 公平性:按租户配额与任务优先级加权分配
- 经济性:跨域调度成本与本地化计算效益平衡
算法数学模型:
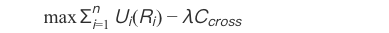

2.2 关键技术实现
(1) 资源预留与抢占机制
- 分级预留池:
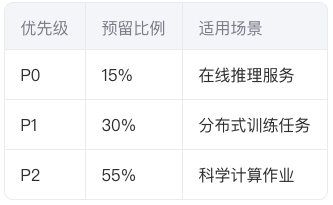
通过滑动窗口算法动态调整预留比例
(2) 弹性扩缩容策略
- 动态感知模块:
def auto_scaling():
while True:
load = get_cluster_load()
if load > 80%:
scale_out(slurm_nodes) # 扩容Slurm计算节点
elif load < 30%:
scale_in(k8s_pods) # 缩容K8s容器组
结合Prometheus监控数据实现分钟级响应
(3) 跨域调度优化
- 延迟敏感型任务:优先分配至物理拓扑相邻节点
- 计算密集型任务:采用Bin Packing算法提升GPU利用率
三、实验验证与性能分析
3.1 测试环境配置

3.2 关键指标对比
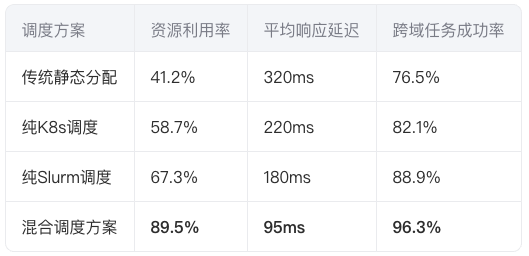
(注:测试数据集包含1.2万个混合类型任务)
3.3 典型场景表现
- 突发负载处理:在1000个推理请求突增时,系统在45秒内完成50个Slurm节点转换
- 长周期作业保障:连续运行72小时的分子动力学模拟任务零中断
四、工程实践建议
4.1 部署避坑指南
- 资源监控基线:
- 设置GPU显存使用率>90%的自动告警
- 建立任务排队时间超过15分钟的熔断机制
2. 调度策略预热:
# 预加载常用调度策略
kubectl apply -f scheduler-profile.yaml
sinfo --preload-topology
3. 跨域网络配置:
- 启用SR-IOV虚拟化降低网络延迟
- 配置动态带宽分配(DBA)保障关键流量
4.2 性能调优方向
- 异构计算加速:集成Habana Gaudi处理器的定制调度插件
- 智能预测调度:采用LSTM模型预测未来1小时负载分布
五、未来演进路径
- 量子计算调度:研究混合经典-量子计算的资源编排模型
- 隐私计算集成:支持联邦学习任务的TEE(可信执行环境)调度
- 绿色算力优化:构建碳排放感知的调度决策引擎


















 2803
2803

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









