







决策树:与邻近算法一样,决策树的作用也在于将数据分类,但不同的地方在于决策树可以将 数据中的分类信息和区别体现出来。
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特 征数据。 缺点:可能会产生过度匹配问题。 适用数据类型:数值型和标称型。
from math import log
import operator
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
#计算数据中的信息熵值H,定义如下
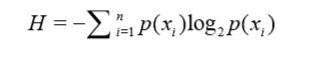
def createDataSet():
dataSet = [[1,1,‘yes’],
[1,1,‘yse’],
[1,0,‘no’],
[0,1,‘no’],
[0,1,‘no’]]
labels
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2428
2428











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









