







决策树(decision trees)
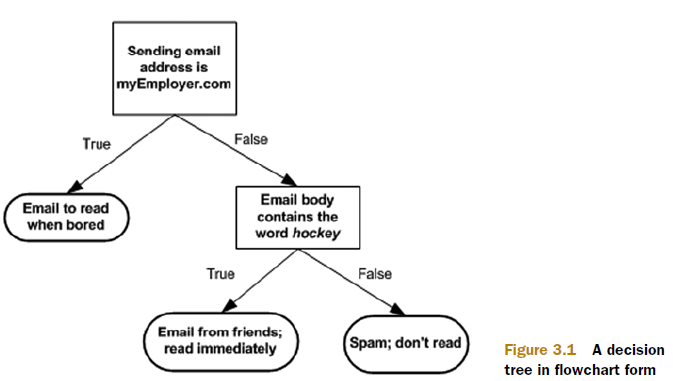
工作原理:
决策树属于监督类型的算法,同样,我们有数据集,知道每一条数据的分类。然后我们按照某种规则,选取数据集上的特征作为分割点,把数据集进行划分。循环重复以上动作,直至所有数据集各自的分类都是唯一的,或者所有特征已经被选择无法再进行划分。使用何种规则进行特征的选取下文将会叙述。
优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
缺点:可能会产生过度匹配问题。
适用数据类型:数值型和标称型。
伪代码:
CreateBranch():
IF 数据集里的数据都属于同一个分类 RETURN 分类
ELSE
根据规则寻找用于划分数据集的特征
划分数据集
创建分支节点
for 循环每个子数据集
递归调用CreateBranch()并把结果放在创建的分支节点中
RETURN 分支节点
python代码:
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):#类别完全相同
return classList[0]
if len(dataSet[0]) == 1:#特征抽取完,但类别还不完全相同
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}#创建节点
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:#划分,创建子树
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree
选取用于划分数据集特征的规则:
划分数据的大原则是使无序的数据变得相对有序。划分数据后的有序程度,与划分数据前的有序程度之间的差,称为信息增益(Information gain)。可以使用熵(entropy)来计算数据的无序程度。熵越高,则数据的无序程度越高。
要计算熵,首先要了解熵的定义。熵的定义为:信息的期望值。信息的定义为:如果待分类的事物可能划分在多个分类之中, 则)xi(分类为第i种的信息定义为
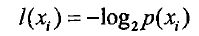
其中p(xi)是选择该分类的概率。
那么可以这样计算熵:
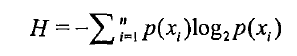
其中,n是分类的数目,i是第i个分类。
由此,可以创建用于计算给定数据集熵的python函数
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels在此操作之前,先来实现根据任意给定的特征切割数据集的函数。
def splitDataSet(dataSet,axis,value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:#把复合条件的数据除去axis列塞进retDataSet
reducedFeatvec = featVec[:axis]
reducedFeatvec.extend(featVec[axis+1:]);#axis列并不复制
retDataSet.append(reducedFeatvec)
return retDataSet接下来,对每一个特征都进行划分,然后计算划分后的熵,找出最适合进行划分的特征:
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1 #特征数,最后一个是分类所以要减1
baseEntropy = calcShannonEnt(dataSet)#划分前的熵
bestInfoGain = 0.0;bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]#提取低i列的所有值
uniqueVals = set(featList)#通过set函数,筛选值
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet,i,value)
prob = len(subDataSet)/float(len(dataSet))#概率
newEntropy += calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature递归构建决策树:
首先是递归结束条件:
1)子集全部属于同一种分类
2)如果特征已被提取完,选取子集分类数目最多的分类作为返回值
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True)
return sortedClassCount[0][0]def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):#类别完全相同
return classList[0]
if len(dataSet[0]) == 1:#特征抽取完,但类别还不完全相同
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}#创建节点
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:#划分,创建子树
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,bestFeat,value),subLabels)
return myTree至此,决策树构造完毕。
构造结果:
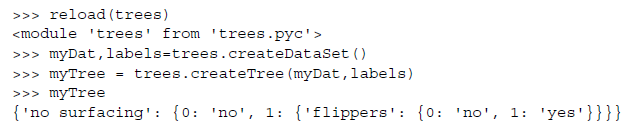
使用决策树:
def classify(inputTree,featLabels,testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
for key in secondDict.keys():
if testVec[featIndex] == key:#比较特征值,决策树是根据特征的值划分的
if type(secondDict[key]).__name__=='dict':#比较是否到达叶结点
classLabel = classify(secondDict[key],featLabels,testVec)#递归调用
else: classLabel = secondDict[key]
return classLabel决策树至此完毕,还有一些问题,如树的字典表示并不好阅读,可以使用Matplotlib绘制树形图,储存生成好的决策树在硬盘上,以免重复生成耗时等。这里暂时不述。决策树还有其他生成方法,如C4.5,CART等,将在后面章节探讨。















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









