







基于图LSTM的社交网络影响力最大化问题迁移学习
前言
又是Sanjay Kumar这位老哥的文章,2022年他还有一篇一区也是将影响力最大化问题转化成回归问题,这是很有创新的尝试,两篇的效果也都很好,可惜没有代码学习一下。

https://www.sciencedirect.com/science/article/pii/S0957417422017882?via%3Dihub
文章内容
摘要
Social networks have emerged as efficient platforms to connect people worldwide and facilitate the rapidspread of information. Identifying influential nodes in social networks to accelerate the spread of particularinformation across the network formulates the study of influence maximization (IM). In this paper, inspiredby deep learning techniques, we propose a novel approach to solve the influence maximization problem as aclassical regression task using transfer learning via graph-based long short-term memory (GLSTM). We start bycalculating three popular node centrality methods as feature vectors for the nodes in the network and everynode’s individual influence under susceptible–infected–recovered (SIR) information diffusion model, whichforms the labels of the nodes in the network. The generated feature vectors and their corresponding labels forall the nodes are then fed into a graph-based long short-term memory (GLSTM). The proposed architecture istrained on a vast and complex network to generalize the model parameters better. The trained model is thenused to predict the probable influence of every node in the target network. The proposed model is comparedwith some of the well-known and recently proposed algorithms of influence maximization on several real-lifenetworks using the popular SIR model of information diffusion. The intensive experiments suggest that theproposed model outperforms these well-known and recently proposed influence maximization algorithms.
社会网络已经成为连接全世界人民和促进信息快速传播的有效平台。识别社交网络中具有影响力的节点,以加速特定信息在网络中的传播,这就是影响力最大化(IM)的研究。在本文中,受深度学习技术的启发,我们提出了一种新的方法,通过基于图形的长短期记忆(GLSTM)的转移学习,将影响力最大化问题作为一个经典的回归任务来解决。我们首先计算了三种流行的节点中心度方法作为网络中节点的特征向量,以及每个节点在易感-感染-恢复(SIR)信息扩散模型下的个人影响力,这形成了网络中节点的标签。生成的特征向量及其对应的所有节点的标签随后被送入基于图的长短期记忆(GLSTM)。所提出的架构在一个庞大而复杂的网络上进行训练,以更好地泛化模型参数。然后,训练后的模型被用来预测目标网络中每个节点的可能影响。建议的模型与一些著名的和最近提出的影响最大化算法进行了比较,这些算法在几个真实的网络上使用流行的信息扩散的SIR模型。密集的实验表明,所提出的模型优于这些著名的和最近提出的影响力最大化算法。
特征提取
选用三种方法进行特征提取
DC: degree centrality: 捕获局部结构信息
HI: h-index: 捕获半局部(semi-local)信息
KS: K-shell(or coreness centrality): 捕获全局信息
用
p
,
q
,
r
p,q,r
p,q,r分别表示DC,HI,KS

不同的中心值大小差异可能会比较大,进行归一化
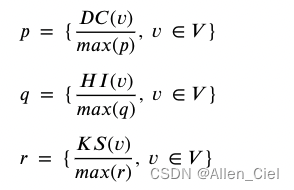
p
,
q
,
r
p,q,r
p,q,r构成二维特征矩阵
f
m
a
t
f_{mat}
fmat,每个矩阵就表示网络中节点的嵌入
e
m
b
e
d
d
i
n
g
u
embedding_u
embeddingu
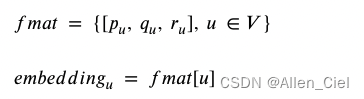
作者将
e
m
b
e
d
d
i
n
g
u
embedding_u
embeddingu描述成“键值对”(“key-value” pair),“键”表示考虑的节点
u
u
u,“值”表示通过公式生成的
f
m
a
t
f_{mat}
fmat。
标签生成
利用BA模型生成网络,作为训练网络
G
t
r
a
i
n
G^{train}
Gtrain。
用SIR信息扩散模型计算每个节点个体的影响,这里我的理解是对于网络中的每一个节点,将其作为唯一的种子节点,通过SIR扩散,得到的扩散范围作为label(INF)
SIR模型的取值:
β
=
0.1
,
γ
=
1
\beta=0.1, \gamma=1
β=0.1,γ=1,
β
\beta
β是感染概率,
γ
\gamma
γ是恢复概率
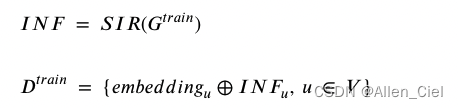
用基于图的LSTM训练模型
选LSTM的原因:
- LSTM的使用允许在不增加网络规模的情况下一起处理长序列的输入。
- 它能合理地处理梯度消失问题。
基于图的LSTM:
LSTM网络与生成节点嵌入配对,通过LSTM构架去处理整个图。
最后,我们为网络中的节点生成了伪嵌入,LSTM在与嵌入配对时表现良好。
 图1 基于图的LSTM模型的逐层结构
图1 基于图的LSTM模型的逐层结构
- 第一层,嵌入层:输入嵌入
- 第二层,LSTM层:有128个LSTM单元
- 第三层,稠密层(dense layer):32个神经元
- 第四层,回归层:具有一个神经元并且使用平均绝对误差(MAE)
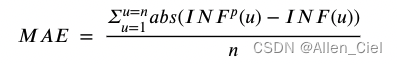
用Graph-based LSTM(GLSTM)在BA生成网络上通过优化损失函数MAE来训练模型参数。
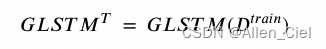
I N F ( u ) INF(u) INF(u)是用SIR计算得到的节点 u u u的影响label, I N F p ( u ) INF^p(u) INFp(u)是用训练得到的模型预测得到的节点 u u u影响label。
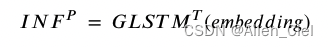 在训练GLSTM模型的同时,在前向传播期间,前一层的加权和被评估为前一层。对于后向传播,我们使用损失函数更新模型参数。
在训练GLSTM模型的同时,在前向传播期间,前一层的加权和被评估为前一层。对于后向传播,我们使用损失函数更新模型参数。
迁移学习
迁移学习:可以理解为一个概念,即转移以前学到的知识,从更广泛、更复杂的数据中学习到的知识,以便对从未见过的数据进行预测。
在
G
t
r
a
i
n
G^{train}
Gtrain上训练好模型,
G
t
g
t
G^{tgt}
Gtgt是需要进行影响力最大化的目标网络,
e
m
b
e
d
d
i
n
g
t
g
t
embedding^{tgt}
embeddingtgt是目标网络的节点嵌入
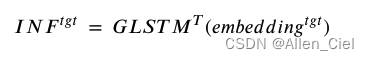
I
N
F
t
g
t
INF^{tgt}
INFtgt是目标网络节点的预测影响力。
提出的模型架构
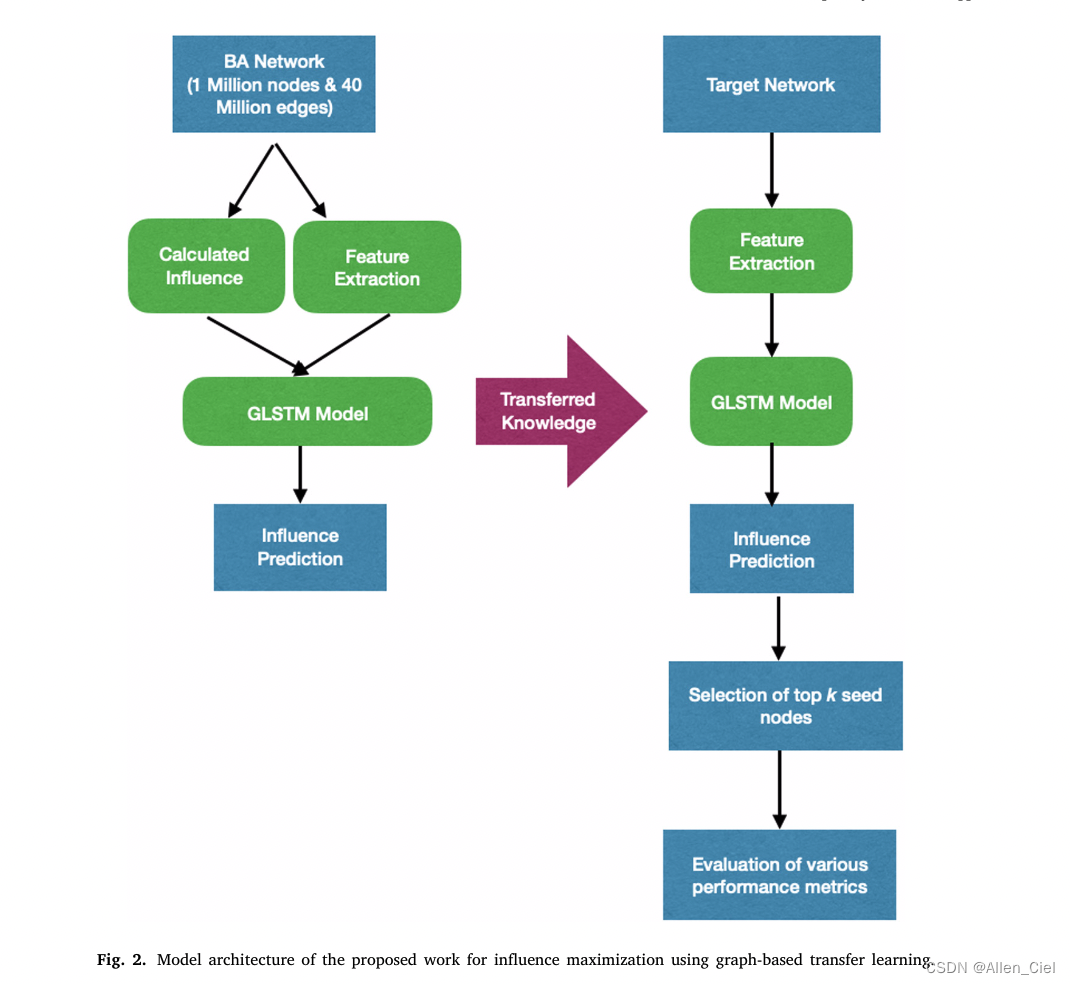
提出的算法
训练GLSTM模型的算法
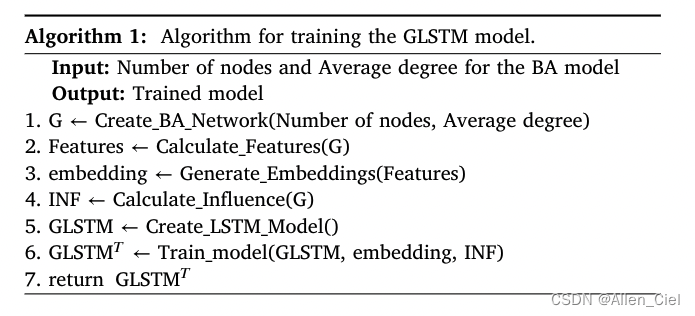
寻找种子节点的算法

数据集和评估性能
数据集
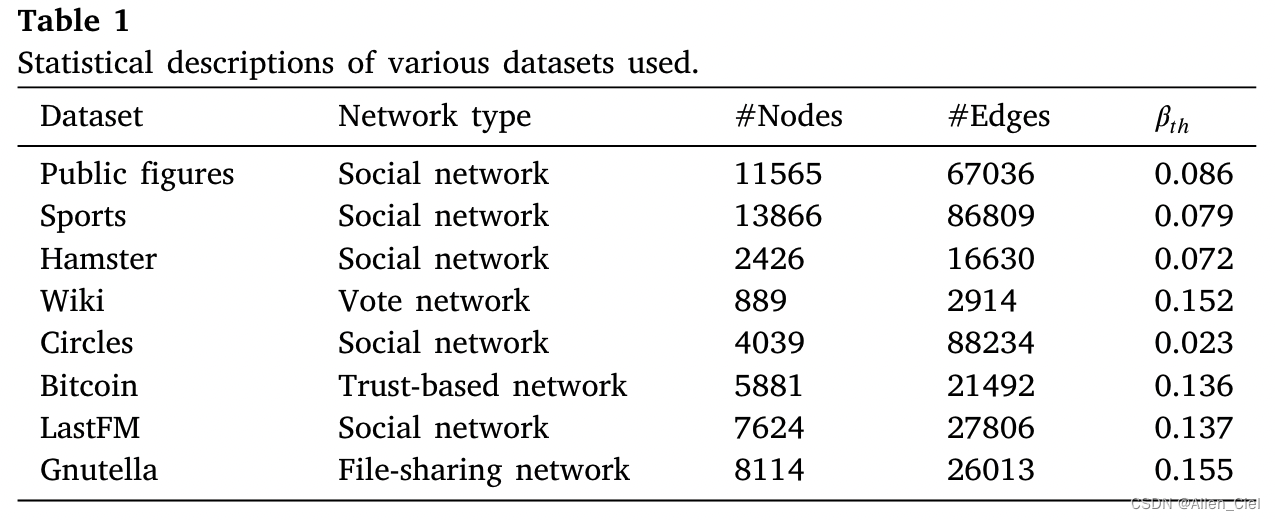
β
t
h
=
1
<
k
>
\beta_{th}=\frac{1}{<k>}
βth=<k>1是流行病阈值,
<
k
>
<k>
<k>是网络平均度。
评价指标
- 最终影响范围 vs. 种子节点数:
F
(
t
c
)
F(t_c)
F(tc)
v
s
.
vs.
vs.
k
k
k
SIR模型中, γ = 1 \gamma=1 γ=1,意味着每一个被感染的节点在下一步会恢复,所以最终影响范围是被激活过的节点的比例, n A n_A nA表示被激活过的节点数。
F ( t c ) = n A n F(t_c)=\frac{n_A}{n} F(tc)=nnA - 最终影响范围 vs. 感染概率: F ( t c ) F(t_c) F(tc) v s . vs. vs. β \beta β
- 传播者平均距离(
L
s
Ls
Ls):种子节点的平均距离越大,传播覆盖重叠率小,说明种子集的质量好
L s = ∑ D u v k ( k − 1 ) 2 Ls=\frac{\sum D_{uv}}{\frac{k(k-1)}{2}} Ls=2k(k−1)∑Duv - Kendall’s tau值
τ
\tau
τ:
评估任何影响最大化算法的经验实用性的一种方法是将该通用节点列表与所考虑的算法列表进行比较。如果这些列表相似,则所提出的算法被认为是可行的。
Kendall’s tau值用于测量两个影响者列表之间的相似性。如果节点𝑢出现在节点之前𝑣在一个列表中,它也在第二个列表中按顺序出现。每一对这样的配对都被称为协调配对( k c k_c kc), 而每一对以其他方式显示的都被称为不和谐对( k d k_d kd)。
τ = k c − k d k ( k − 1 ) 2 \tau=\frac{k_c-k_d}{\frac{k(k-1)}{2}} τ=2k(k−1)kc−kd
τ \tau τ值的范围从-1到1。1表示两个列表相似,-1表示两个列表完全不相似。 - Kendall’s tau值 τ \tau τ v s . vs. vs.感染概率: τ \tau τ v s . vs. vs. β \beta β
实验结果与分析
结论
本文的工作将影响力最大化问题转化为回归问题,并削弱了迁移学习的概念。
实验表明,我们提出的方法通过选择初始种子集,提供了最大化影响传播的示范性性能。作为这项工作未来增强的一部分,该算法可以扩展到加权网络和多层复杂社交网络。














 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









