






【摘要】本文是关于影响力最大化相关内容;内容的是关于论文An efficient path-based approach for influence maximization in social networks 的创新点总结以及自己的一些收获和启发;论文原文链接
一、论文的亮点
- 作者提出了一种有效的基于路径的算法(HIPA)来解决社交网络影响力最大化问题,从两个互补的角度来适应大规模网络中提出的算法。
- 使用节点的度数和独立影响路径这两个特征有效地近似影响传播。
- 使用实用的预处理启发式方法剪除无影响的节点以减少近似影响传播的计算量。
二、HIPA算法具体过程
1 预处理
- 使用顶点覆盖移除所有或部分无用节点可以有效地减少计算时间。找到一组节点覆盖,修剪原始图,然后将剩余节点作为选择集传输到下一步。顶点覆盖算法如下图所示。

- 顶点覆盖由算法开始时为空的 VC 表示(第1行)。
- 第2行中,集合 É 被视为图边集 (E) 的副本。 在一个迭代循环中(whileE^Á
∕= ∅),从É中选择一条边(u,v),并将端点u和v添加到VC中,并且从节点u和v中删除所有连接的边。 - 设置É。算法 2 返回集合 VC作为输出选择集。 该算法应用于“Zachary 的空手道俱乐部”数据集(Zachary,1977),图 3.a 其中,输出是 34个节点中的 18 个节点,用红色表示。
- “Zachary 的空手道俱乐部”网络的最佳顶点覆盖如图 3.b 所示。因此,在“Zachary
的空手道俱乐部数据集”上运行此预处理导致计算量减少了近 50%,因为主要算法仅在一半节点上运行计算。

2 估计节点的影响扩散
-
HIPA结合了图的两个结构属性(节点之间的度数和可用路径)用于计算网络中的影响扩散。
-
在这里,有必要评估每个节点的影响扩散。为此,HIPA形成了选择集节点的向量,称为影响传播向量,并应用“影响传播路径”和“度”的组合来设置其元素。
-
在 HIPA 中查找影响传播路径类似于 (Kim et al., 2013) 中描述的,其中需要搜索从任何源节点到图的其他节点的所有有效非循环路径,可以是采用深度优先搜索法(DFS)。查找两个节点之间的所有可能路径非常耗时,并且需要大量内存。
-
为了克服这个缺点,可以忽略影响传播太小的路径。因为,影响传播随着路径长度的增加而减小,HIPA 应用“路径长度”阈值来消除传播概率低于阈值的路径。
-
因此,只有不否认阈值的路径称为有效路径,才会被研究并存储在内存中。如果 v 和 u 节点之间的有效路径集合表示为 Pvalidu→v = {p1,p2,⋯,pl},则其影响传播将是有效路径影响传播的乘积并通过方程式定义。

-
其中 ipp§ 是通过等式获得的路径 p 的影响传播概率。
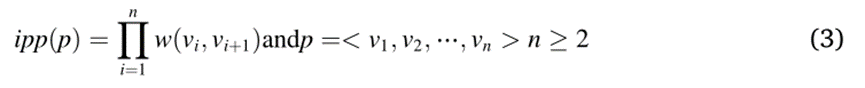
-
其中 w(vi, vi+1) 是 vi an dvi+1 之间的边的权重; Given0 ≤ ipp§ ≤ 1,为了减少十进制数乘法中的计算误差,Eq. (2)可以改写为等式。 这相当于 Pvalidv→u 中没有路径激活 u 的概率的互补。
-
估计节点通过路径的影响传播正在被许多算法应用(Chen et al., 2010; Kim et al., 2013, 2017),但是它们没有区分不同的路径。 HIPA假设到目的节点的不同路径的价值是相关的,即目的节点越有价值和影响力越大,其激活在最大化影响。
-
因此,通向该节点的任何路径都将更有价值,表明该 HIPA 中每个节点 v 到节点 u,̂σ u H({v}) 的影响传播估计是通过乘以“路径的影响传播概率在节点 v 和 u 之间”,̂σ u P({v}),由“网络中目标节点 u 的值”,̂σ I({v} ),等式。
补充知识:作者提出的观点:目的节点影响力越大,通向该节点的任何路径也将更有价值。这个观点逻辑上似乎说得通。


举例:评估a对c的影响。


3 选择节点和更新路径 -
第一次节点选择是在第 k 次迭代时逐渐进行的,每次迭代时,选择最有影响的节点并添加到有影响的节点集合(S)中,然后基于所选节点的直接和间接邻居(二阶)使用IC模型(使用最广泛的传播模型)进行更新。
-
正如在算法 1(HIPA 算法的总体框架)中所观察到的,k 个有影响的节点表示为 S,其中 S 的成员通过 k 次选择节点迭代以贪婪的方式找到。
-
在每一步,计算出每个节点的影响力后,选出影响力最大的节点加入集合S。选择节点v后,根据IC模型更新其影响范围内的节点,因为1)路径通过 S 集合在计算节点的影响扩散时必须是无效的,并且 2)必须忽略种子节点之间的路径。节点 v 路径的更新过程如图 5 所示。

-
路径保存策略
斜体样式其中种子集影响区域的路径消除是明显的。为了便于访问并避免在更新过程中重新加载路径,HIPA 对上一步收集的路径进行分类,并基于类似于影响传播向量 (I-Vec) 的源节点保存它们。此外,它根据目标节点对来自每个源节点 v 的有效路径进行分类,从而使访问变得容易。在 HIPA 中保存路径的一个示例的策略如图 6 所示,其中 t 有来自 vi to uj的三个路径,标记为 asp1、p2 和 p3 是显而易见的。保存轨迹表如图 6 所示。源节点为节点 vi 的路径,根据表 PT(vi) 分组保存,目的节点在第 i 行。 PT 表,图 6。该表的第 j 行显示了目标节点为 isuj 的路径。


-
方法流程图

三、论文的优缺点
-
(缺点)需要正确设定θp值,并且针对每个数据集需要重新计算。

-
(优点)证明执行时间短、质量高的预处理阶段适合寻找有影响的节点。
-
(优点)在验证的七个真实数据集中取得比所有启发式算法更好的传播效果。HIPA算法对平均度数较低的稀疏数据集更有效。
四、自己的收获点
- 是否有可能将机器学习中的一些优秀算法(例如T-test等)用于预处理阶段,减少节点数量;
- 基于传播路径的影响力最大化是第一次见,它的优势是平衡了影响力和时间性能,将其应用于IBM问题也会有不错的效果。
五、未来可能的突破点
- 在其他信息传播模型(例如基于情感的IC模型)上执行该方法并获得更完整的结果;
- 调整框架:路径长度阈值,以便以自动和动态的方式确定有效路径。














 960
960











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









