







本论文发表于IEEE COMPUTATIONAL INTELLIGENCE MAGAZINE | FEBRUARY 2023

Abstract
影响力最大化是挖掘社交网络深层信息的关键问题,其目的是从网络中选择种子集以最大化受影响节点的数量。为了有效评估种子集的影响力传播,现有研究提出了计算成本较低的变换来取代昂贵的蒙特卡罗模拟过程。这些基于网络先验知识的交替转换会引发不同视角的具有相似特征的不同搜索行为。具体来说,用户很难先验地确定合适的变换。本文提出了一种具有收敛保证的影响最大化的多变换进化框架(MTEFIM),以利用替代变换的潜在相似性和独特优势,并避免用户手动确定最合适的变换。在 MTEFIM 中,多个转换作为多个任务同时优化。
每个变换都分配有一个进化求解器。
MTEFIM 的三个主要组成部分是通过以下方式进行的:
1)根据不同群体个体之间的重叠程度估计不同转化之间的潜在关系,
2)根据相互转化关系自适应地在群体之间转移个体,
3)选择最终的包含所有转换知识的输出种子集。
MTEFIM 的有效性在基准测试和现实社交网络上得到了验证。实验结果表明,与几种流行的 IM 特定方法相比,MTEFIM 可以有效地利用跨多个转换的潜在可转移知识,以实现极具竞争力的性能。 MTEFIM的实现可以通过脚注中的外部链接访问。
I. Introduction
社交网络用于描述人们之间以口头方式进行的约定交流和联系[1]。随着用户数量的快速增加,Twitter、微博、TikTok、Instagram等新型在线社交网站或应用程序已成为人们分享和交流想法的主流社交平台,为营销人员锁定潜在客户提供了极大的便利。
近年来,这些网站或应用程序的兴起推动了社交媒体营销的完整产业链,包括影响者和营销机构[4]。 Charli D’Amelio 和 Addison Rae 等影响力人士在 TikTok 上拥有数千万粉丝。通常,这些影响者营销机构通过与最初的影响者(例如演员和名人)合作来推广他们的产品,这被市场证明是有效和成功的。寻找能够帮助成倍吸引新消费者的影响者对于影响者营销的成功至关重要[5]。无独有偶,这个问题也出现在政治运动[6]和流行病分析[7]中的一系列实际应用中,这是影响力最大化(IM)问题的核心。
上述IM问题旨在从社交网络中选择一组用户,称为种子集,以在信息扩散过程中最大化影响力的传播[8]。人们提出了一些流行的模型来研究扩散过程,例如独立级联(IC)[9]、加权级联(WC)[10]和线性阈值(LT)[11],它们模拟独立或集体行为的种子集。由于信息生产在不同的问题中受到各种社会或生物因素的干扰,现有的工作倾向于利用网络结构信息来寻找这些模型下的影响者[12]。多明戈斯等人。 [8]首先将 IM 形式化为 NP 难组合优化问题,这表明只有具有一定条件的最优集可以求出近似程度。多明戈斯等人。 [8]进一步提出了一系列基于贪婪的IM算法。理论结果表明,在IC模型下,贪心法可以产生精度不低于1 1/e的最优解。然后,开发了几种算法来解决贪婪方法的低效率和可扩展性不足的问题。莱斯科维奇等人。 [13]提出了一种改进的贪婪算法,采用“成本高效的惰性前向(CELF)”策略,据报道该算法比贪婪方法快 700 倍。戈亚尔等人。 [14]通过考虑 IM 的子模属性进一步扩展了 CELFþþ。此外,陈等人。 [10]提出了一种新的贪心算法,在剪枝后对网络进行扩散过程。然而,这些基于模拟的贪心方法需要数千次蒙特卡罗模拟来评估影响力扩散,这在实践中是无法实现的。
为了克服基于模拟的方法的局限性,已经提出了几种启发式方法来处理大规模网络。可以采用简单的排名思想来选择种子集,例如使用程度、PageRank [15] 和距离中心性 [16]。陈等人。 [10]设计了一种程度折扣启发式方法,该方法假设影响力传播随着用户程度的增加而增加。王等人。 [17]进一步扩展到广义程度折扣启发式。然而,这些近似方法可能与影响扩散过程有很大不同(参见[9]、[10]中的实验分析)。
近十年来,一系列元启发式算法因其在解决NP难问题上的优越性而被提出来解决IM问题,例如模拟退火(SA)和进化算法(EA)。这些方法在许多现实世界的网络上具有出色的性能。江等人。 [18]提出了一种廉价的近似模型,称为期望扩散值(EDV),以取代SA算法的扩散过程并优化目标。李等人。 [19]通过限制种子集的两跳用户的传播,引入了扩散过程的近似模型。龚等人。 [20]通过利用社交网络中的社区信息来减少 IM 问题的搜索空间,并提出了一种模因算法来优化两跳影响力传播,本文称为 TIS。此外,龚等人。 [21]提出了一种离散粒子群优化算法来优化近似2跳影响传播的局部影响估计(LIE)。王等人。 [22]通过考虑2跳邻域中用户的估计和方差,提出了一种新的影响力估计模型,本文称为IEEV。辛格等人。 [23] 引入了一种基于学习的 IM 粒子群优化,并将 EDV 扩展到近似两个所需区域。此外,还提出了蚁群算法[24]来优化局部影响力评估。李等人。 [25]提出了一种基于网络拓扑结构的离散乌鸦搜索算法。马等人。 [26]针对复杂网络中的 IM 问题提出了一种新颖的进化深度强化学习算法,其中 IM 问题转化为深度 Q 网络的连续权重优化问题。此外,许多结合强化学习和网络嵌入的方法已经提出优化预期影响来解决各种 IM 问题 [27]、[28]。这些方法从不同角度构建了各种廉价的影响力传播代理模型,并采用元启发式范式对其进行优化。然而,这些代理模型之间的相似性尚未被研究,这可能会提高 IM 算法的性能。此外,工作[29]指出,这些代理模型会引发具有相似特征的不同搜索行为。因此,在处理实际IM问题时,很难选择最合适的代理模型。

图 1 两个优化任务(即 EDV 优化和 TIS 优化)在四个现实网络上的相似性:Email URIV、Hamsterster、Ego-facebook 和 Fb-pagespublic-figure,其中 K 是种子集。
优化任务之间的相似性可以通过适应度景观之间的整体相关性来反映,这可以通过斯皮尔曼的等级相关性来量化[30]。在搜索空间中随机生成一百万个固定数量种子的种子集,其估值是根据两种流行的代理模型 EDV 和 TIS 计算的。然后,将其估值的斯皮尔曼等级相关性视为两个优化任务的相似性[31],即EDV的优化和TIS的优化。图 1 显示了四个代表性现实网络上两个优化任务的相似性。这两个优化任务的适应度景观确实高度相似,因为这些代理模型都考虑了种子集的邻居信息,导致不同代理模型的优化过程之间存在大量可用知识。
多变换优化(MTFO)[32]是指针对一个目标优化任务同时优化多个备选公式,可以通过多任务优化(MTO)方法来解决[33]。由于 EA 的隐式并行性,多任务优化在进化计算(EC)领域引起了广泛关注[33]、[34]、[35]、[36]、[37]。多任务 EA 解决的 MTFO 已应用于许多实际问题,例如高维优化 [38]、[39] 和昂贵的优化 [40]、[41]。与单独优化目标任务的某个公式的单变换 EA 相比,多变换 EA 可以利用不同公式的独特优势,通过进化过程中的知识迁移显着提高性能。受多变换 EA 的启发,本文提出了一种 IM 多变换进化框架(MTEFIM),利用多种代理模型的相似性和独特优势来提高基于进化的 IM 算法的性能,并防止用户选择代理先验模型。多个代理模型(在本文中称为多重转换)是同时优化的。每个转换都被分配一个群体。不同转变的个体之间的重叠程度提供了对其潜在关系的间接估计。基于相互转换的关系,跨给定转换和最相关的“辅助”转换的知识转移过程被设计为自适应地交换公共信息。最后,MTEFIM考虑每个变换的最优种子集的综合排名,然后输出包含所有代理模型的知识的最终种子集。对一系列综合基准和现实世界网络进行了实证研究,以验证 MTEFIM 的性能。结果表明,与几种流行的 IM 方法相比,MTEFIM 通过跨转换的知识迁移在影响力传播和运行时间方面取得了极具竞争力的性能。
本文的主要研究贡献如下:
1) 受变换之间相似性的启发,提出了一种具有收敛保证的 IM 多变换进化框架,以隐式地利用多个变换的共同和独特的知识。除了单独优化一个代理模型的现有方法之外,所提出的方法在一次运行中同时优化多个变换以避免先验的变换选择。
2)通过考虑不同变换个体之间的重叠程度,提出了一种新颖的变换间关系估计策略来指导多变换环境中的自适应知识转移过程。为了产生最终的输出种子集,引入了一种简单而有效的选择策略,该策略考虑了每个转换的最佳种子集的折衷性能。
本文的其余部分组织如下。第二节提供有关 IM 问题、代理模型和 MTFO 的背景知识。 MTEFIM 在第三节中详细介绍。第四节描述了五个现实世界网络的实验结果和讨论。最后,第五节介绍了结论和未来的工作。
II. Preliminary
在本节中,首先介绍社交网络中 IM 的背景知识和元启发式方法的代理模型。然后,简要回顾了 MTFO 领域的基础知识和相关工作。
A. IM in Social Networks
社交网络被建模为图 G 1⁄4 (V, E),其中 V 1⁄4 {1, 2, ..., v} 和 E 1⁄4 {eij j i, j2V} 相应地是节点集和网络的边缘集[42]。给定具有 k 个种子节点的种子集 A2V,概率影响扩散模型返回受种子影响的节点的预期数量,表示为 s(A)。人们提出了许多模型来描述不同场景下的影响力传播过程,例如 IC、WC 和 LT 模型。 IC模型是研究最广泛的扩散模型之一,并且开发了许多代理模型来近似该模型[43]、[44]。因此,本文选择IC模型来描述影响力传播过程。
在IC模型[9]中,所有节点要么是活动的,要么是非活动的。激活的节点通过节点之间的连接以传播概率 p 影响不活动的节点。考虑具有k个节点的种子集A2V,影响传播过程可以表示如下。第一步,A 中的 k 个种子处于活动状态并保存在集合 A1 中。在步骤t,给定边euv的传播概率p(u,v),节点u2At-1可以以概率p激活不活动邻居v。请注意,u 只有一次机会激活其邻居。那些成功激活的节点保存在集合At中。上述影响传播过程在At 1⁄4 时停止。然后,将影响力传播过程中活跃节点的数量定义为IC模型下种子集A的影响力传播s(A)。
IM 可以被认为是以下离散问题 [45]:给定一个社交网络 G 1⁄4 (V, E) 和种子集 k 的大小,IM 问题的目标是在影响下选择一个种子集 A传播模型使得,

其中j A j是集合A的大小。为了解决上述IM问题,需要使用数万次蒙特卡罗模拟来估计任何给定种子集的影响力传播过程,这是非常耗时的[43]。在下一节中,将介绍两种流行的代理模型 EDV 和 TIS 来近似影响力扩散 s,以取代昂贵的蒙特卡罗模拟过程。
B. Proxy Models for Meta-Heuristic Methods
EDV [18]。对于 IC 模型中的小传播概率 p,EDV 通过 k 个种子来估计受种子集 A 影响的节点的预期数量,

其中 NBðAÞ1⁄4A [fbj9a 2 A; eab 2 Eg 表示种子集 A 的一跳邻居,dðbÞ1⁄4jfaja 2 A; eab 2 Egj 表示A 对b 的影响。 j j 是集合中元素的数量。该公式本质上是提取N(A)的边和节点信息,形成子图来快速评估影响力扩散。一系列现有的工作使用元启发式算法来优化 EDV 或其变体 例如SA[18]、粒子群优化(PSO)[23]、[46]和蚁群优化[24]。与基于启发式的方法相比,这些方法可以在现实网络中快速找到更准确的解决方案。
TIS[20]。对于 IC 模型,TIS 通过 2 跳邻域估计种子集 A 的影响传播,

其中 N ( ) 表示种子 的 1 跳节点覆盖率,p (a, b) 表示活动节点 a 和非活动节点 b 之间的传播概率,a(b) 表示节点的 1 跳影响力传播b.在(3)中,第一项评估A中种子的2跳影响传播之和。第二项和第三项考虑种子之间潜在的冗余影响。 TIS考虑种子邻居和邻居的邻居的信息来快速近似种子集的影响力传播,它已被广泛扩展以解决不同类型网络上的IM问题[25],[47]。基于TIS,提出了一些代理模型,例如LIE[21]、[48]和IEEV[22]。
由于不同的代理模型在种子集上考虑不同的邻居信息,因此使用EDV和TIS可能会导致具有相似特征的不同搜索行为,从而导致在特定问题上的不同性能。 EDV和TIS在之前的研究中一直被强调,因此本文选择它们作为IM问题的替代变换。此外,在第 V.E 节中,提供了更多的比较实验来说明选择 EDV 和 TIS 的基本原理。
C. MTFO
给定目标最小化任务 f 的 S 个替代公式 {f1, f2, ..., fS},MTFO 问题可以形式化为 [32],

其中 D 是目标优化任务 f 的搜索空间,m 是 x 的维度。 MTFO 的目的是通过跨替代公式的有效知识转移找到优化任务 f 的最佳解决方案。该解决方案可以从以下集合中选择,

一般来说,MTFO问题被视为MTO问题。进化多任务优化(EMTO)旨在利用 EC [49]、[50] 激发的一些范式同时解决多个任务。古普塔等人。 [33] 受到生物体之间文化交流的启发,设计了多因素 EA(MFEA)来同时优化许多任务。 MFEA将个体编码到统一的搜索空间中,为知识转移提供基本保证,并为每个个体设置一个技能因子来指示其关联的任务。通过选型配对和选择性模仿,知识以一定的概率rmp跨任务隐式转移,以提高收敛性能。 MFEA 的理论分析表明,跨任务的知识转移是由 rmp 控制的。保释等人。 [36]进一步提出基于在线参数估计的MFEAII,以解决负转移的普遍问题。 Feng 等人提出了一种显式 EMTO 算法,在本文中称为 EMEA。 [34]利用具有不同偏差的多个进化求解器。在欧洲、中东和非洲地区,每个任务都分配有一个进化求解器,并且每个任务上的顶尖个体都根据自动编码显式转移到其他任务,该自动编码学习跨任务的最佳线性映射。廖等人。 [35]提出了生物群落(SB)优化中的共生来处理 MTO,它利用 SB 的概念跨任务传递知识。据我们所知,虽然已经提出了一系列优秀的 EMTO 方法,但没有一个是专门为解决 IM 问题而设计的。

图 2 MTFO 的核心思想,其中目标任务的多个交替转换由多任务 EA 同时优化。
图2说明了MTFO的核心思想,其中目标任务的多个替代转换由多任务EA同时优化。通过搜索过程中发生的知识转移,利用了替代公式的独特优势和相似性。 MTFO的基本思想用于解决现有工作中的复杂优化问题[38]、[40]、[41]。丁等人。 [40]提出了针对单个昂贵问题的跨低保真度和高保真度转换的有效知识转移。为了解决大规模优化问题,现有工作使用降维构造低维优化变换的方法,例如无监督神经网络和随机嵌入[38]。冯等人。 [39]提出了一种多变量搜索来同时优化高维和低维变换。多变量协同工作不仅利用了每种替代变换的独特优势,而且避免了用户先验的变换选择。然而,由于IM问题的个体表示的特殊性,现有的MTFO方法不能直接处理多变换IM。
III. The Problem Form and MTEFIM
A. Outline of MTEFIM
给定影响力传播模型下社交网络 G 1⁄4 (V, E) 上 IM 问题 s 的 S 代理模型 {s1, s2, ..., sS},多变换 IM 可以表示为,

其中从网络中选择的种子集的大小限制为 k。所有转换共享相同的搜索空间。其目的是同时优化所有转换,通过进化多任务开发其潜在知识。
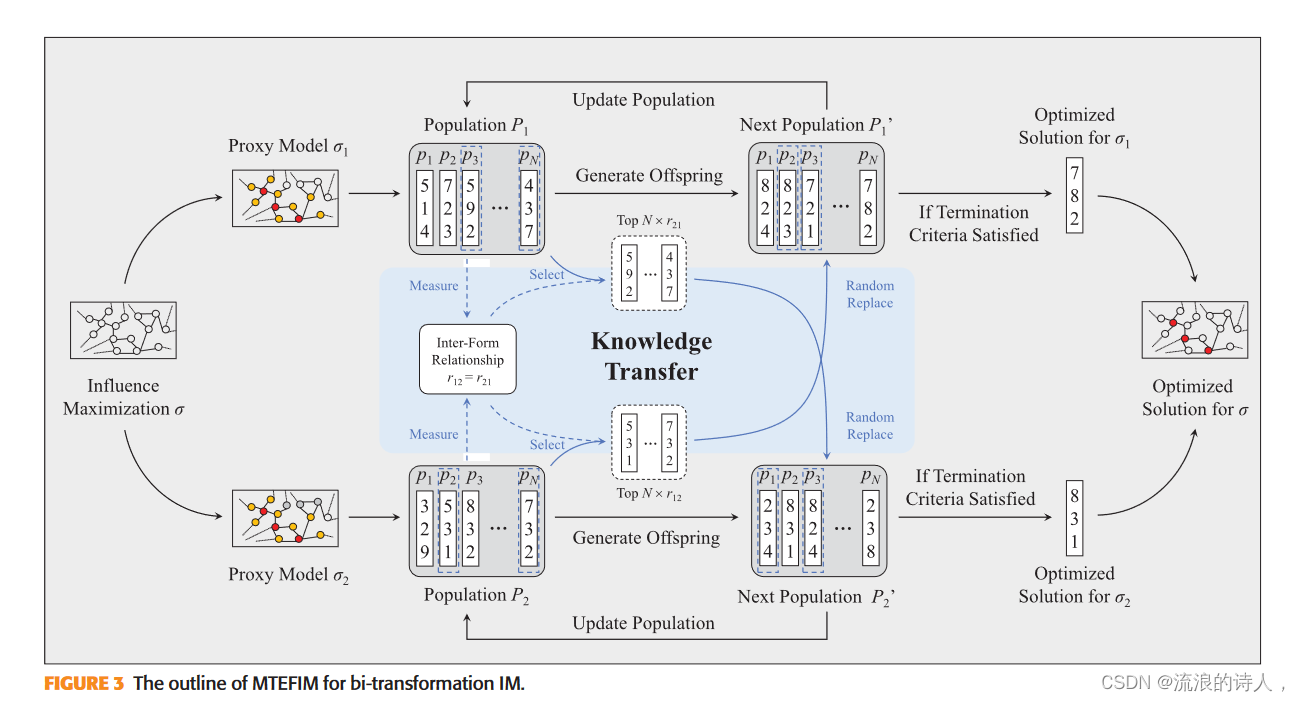
双转化 IM 的 MTEFIM 轮廓如图 3 所示。据观察,每个转化都分配了一个群体。所有群体中的个体(即种子集)都在同一搜索空间 A2V 中初始化。每个群体仅根据相应的转换进行评估。在主循环中,对于任意两个变换 si 和 sj,相互变换关系 rij 通过以下程度来估计:
在线不同转变的个体之间重叠。每个种群都根据设计的遗传算子来生成后代种群。然后,对于每个变换,根据变换间关系 R 1⁄4 {rij j 1 i, j S, i 61⁄4 j, rij 1⁄4 rji},将最相关变换中的顶级个体转移到随机替换当前变换中的一些个体,如图3所示,其中被替换的个体被视为跨变换的公共知识的载体。然后,通过精英主义从亲代群体和后代群体中选择下一个群体。最终的输出解是从每次变换的最优解中选出的,它包含了所有代理模型知识。在 MTEFIM 中,每个变换都分布有一个进化求解器。可能携带共享知识的个人在转型过程中流动。算法1描述了用于多变换IM的MTEFIM的框架。接下来,本节给出MTEFIM的细节。
B. Population Initialization
n MTEFIM,所有群体中的每个个体p代表一个具有k个节点的种子集,可以表示为,
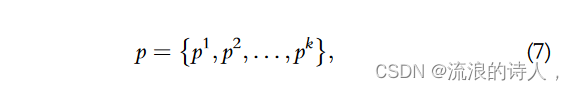
其中 pk 是 {1, 2, ..., v} 中的节点索引,v 是社交网络 G 中的节点数量。
 图 4 显示了该表示的图示
图 4 显示了该表示的图示
由于随机初始化往往会导致收敛速度较慢,因此MTEFIM采用了IM中常用的热启动方法,即度折扣启发式[21]。值得注意的是,其他启发法仍然适用。这基于度启发式的热启动方法描述如下:
1)通过选择社交网络G中度数最高的k个种子来初始化每个个体;
2) 每个个体中包含的每个节点都以0.5的一定概率被其在社交网络中的邻居节点替换,除了当前个体中包含的节点之外。
执行上述初始化后,可以获得具有基于程度的知识和多样性的群体。
C. Genetic Operators
种群初始化后,对初始种群进行交叉、变异等遗传算子,生成更好的种子集。
对于种群中的每两个个体,共享种子信息,以概率 pc 在交叉算子中获得更高的潜在种子集。在本文中,采用了双点交叉[51],因为它的效率高且复杂度低。

图 5 显示了个体 p1 和 p2 上的两点交叉。给定来自父代群体的两个父代个体 p1 和 p2,首先生成两个交叉位置 x1 和 x2,其中 {x1, x2 j 1 x1 ,x2k,x1<x2}。然后,通过在 p1 和 p2 的位置 x1 和 x2 之间交换种子来生成两个新候选 p1 和 p2 。接下来,要保证 p1 和 p2 的有效性,即个体中不存在完全相同的种子。具体来说,随机生成新种子来替换候选中的重复种子。
对于群体中的每个个体 p,进行以下变异算子[52]以帮助在交叉后逃离局部最优。

图6给出了个体p上的变异算子的说明。个体中的每个种子以一定的概率pm被网络中的其他节点替换,并保证个体的可行性。
D. Estimating the Inter-Transformation Relationship
利用相互转换关系来指导不同转换之间的知识转移。在演化过程中,每个变换都被分配一个选定的最相关的辅助变换。知识转移发生在他们之间,以个人为载体。一般来说,两个变换越相似,它们包含的共同知识就越多。这是因为相似的变换包含更多用于搜索的常识,例如相似的适应度景观(见图 1)。由于景观分析的计算成本很高,因此使用群体来隐式估计多转化环境中的相互转化关系。
两个种子集之间的重叠程度可以直接反映它们的相关性。因此,估计两次变换对应的两个种群中个体之间的重叠程度,即可得到相互转化关系rij。变换间关系估计如算法2所示。计算两个种群的相应种子集中相同种子的比例以近似变换间关系。
 图
图
7 演示了两个变换之间的变换间关系估计。
如果算法2中步骤6的计算复杂度为O(k2),则变换间关系估计的计算复杂度为:
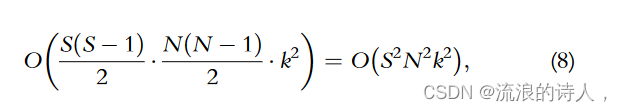
其中 S、N 和 k 分别是转换次数、种群大小和种子集大小。
E. Selecting Output Seed Set
由于每个转换从不同的角度解决 IM 问题,因此它们的最佳种子集也可能不同。一个直观的想法是使用蒙特卡洛模拟来评估每个最优种子集,并选择性能最好的种子集作为输出种子集,称为MCSS,但由于多次模拟,成本较高。
在获得每个变换的最优个体后,提出了一种易于实现的选择输出种子集(SOSS)的方法。给定 S 最优个体 p 1⁄4 {p1 , p2 , ...., ps } 对于 S 变换 s 1⁄4 {si,1 i S} ,这可以指定如下:
1) 每个最优个体 pi 在所有变换 s 上进行评估。
2) 计算升序因子成本列表上每个最优个体pi对应于每个变换sj的排序索引rankij。
3) 将每个最优个体 pi 的排名指数rankij 相加,

其中Cj表示用户对第j次变换的先验偏好,并且满足以下条件,

当用户未提供时,用户优先偏好Cj可以设置为1/S。这意味着变换之间不存在明显的可确定的偏好。
4) 采用累积排名CR最高的种子集作为最终的输出种子集。
该方法综合考虑了最优种子集在所有变换中的性能,避免了昂贵的蒙特卡罗模拟过程。
F. Theoretical Analysis of MTEFIM
在本节中,提出了 MTEFIM 的渐近全局收敛分析。不失一般性,与变换 s 相关的子总体和目标函数分别定义为 Ps 和 ss。在时间步 t,假设第 3 个子群体服从概率分布 ps(x,t)。因此,在 MFEAIM 的第 t 次迭代中,为第 s 次变换生成的后代群体被认为是从以下混合概率分布中得出的。
Lemma 1.假设在 MTEFIM 中采用以父代为中心的遗传算子,则在时间步 t 第 s 次变换的后代的混合概率分布 ps(x, t) 可以表示为:

证明。在多变换环境中,子群体 s 中的后代解 x 是从概率分布 ps(x,t) 或 pj (x,t) 中得出的。从 ps(x,t) 中得出 x 的概率 P(x ps(x, t) j x2s) 在两种情况下发生(参见算法 1):
情况1:当随机数rand()大于或等于rs,j(t)时,子代x2s的所有个体均来自于ps(x,t)。该情况的概率为,
![]()
情况 2:当随机数 rand() 小于 rs,j (t) 时,从 ps(x,t) 导出后代 x2s 的概率为,

因此,概率 P(x ps(x,t) j x2s) 可以表示为:

类似地,从 pj (x,t) 导出后代 x2s 的概率为:
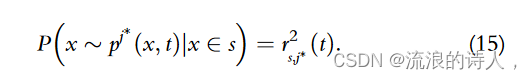
根据算法2,可以通过两个种子集之间的重叠程度来计算相互变换关系rs,j(t),

其中 xs i(t) 是步骤 t 中第 s 个子种群中的第 i 个种子集。 I(xs m(t), xj n(t)) 是 xs m(t) 和 xj n(t) 中相同种子的数量。结合(14)、(15)和(16),可以获得混合概率分布ps(x,t)。此外,还提出了 MTEFIM 的渐近全局收敛分析。
假设1. 假设:1)种群规模非常大(N!1),2)采用以父代为中心的遗传算子和截断参数为a的截断选择,3)ps(x,0)为正且在搜索空间 X、s 1⁄4 1、...、S 和 4) 中连续,截断参数 a < 1 r2 s;j ðtÞ。
在证明中,考虑了更复杂的截断选择而不是精英主义,因为采用精英主义策略的进化算法通常具有渐近全局收敛特性。
定理1.假设满足假设1,则MTEFIM在多变换环境下的每次变换都具有渐近全局收敛性,

证明。证明在附录A中,它类似于对分布算法[53]和MFEA[36]的大多数估计的理论分析。该定理指出,随着迭代次数的增加,每次变换的总体分布都会向搜索空间中的全局最优位置移动。
IV. Experimental Study
在本节中,首先分析了 MTEFIM 中的知识转移过程、相互转换关系估计以及输出种子集的选择。然后,提出了所提出的 MTEFIM 在一系列网络上的功效。对于综合基准和真实世界网络的情况,采用多种方法作为基准,在影响力分布和运行时间方面进行比较。采用10000次运行的蒙特卡罗传播模拟来评估所有方法获得的种子集的影响传播。所有实验均在具有 3.00 GHz Intel Core i7-9700 CPU 和 16GB RAM 的 PC 上进行,源代码用 Python 实现。本节解释了以下观察结果:
1) MTEFIM 中的知识转移策略可以通过利用跨转型的共同知识来提高绩效(参见第 IV.B 节)
2)对于IM问题,MTEFIM中的知识转移机制优于其他EMTO方法中的知识转移机制(参见第IV.B节)。
3)参数r可以明确地反映变换之间的关系(参见第IV.C节)。
4) 输出种子集选择策略 SOSS 是有效的(参见第 IV.D 节)。
5) EDV 和 TIS 的组合在多转换环境中提供了最佳性能,这说明了选择 EDV 和 TIS 的基本原理(参见第 IV.E 节)。
6)与流行的 IM 方法相比,MTEFIM 通过利用不同转换的独特知识表现出极具竞争力的性能(参见第 IV.F 节)。
A. Experiment Setting
1) Datasets
MTEFIM 的性能在一个著名的合成网络和五个现实网络 [54]、[55]、[56]、[57] 上进行了验证,包括 GN-Network、Email URIV、Hamsterster、Ego-facebook、Fb -pages-public-figure 和 NetHEPT2。采用GN网络来表示具有4个社区和128个节点的模块化网络,其中每个节点的度数相同为16。参数m用于控制社区之间的链接数量。本文中的所有基线均在 m 1⁄4 1 的 GN 基准网络上进行测试。电子邮件 URIV 是电子邮件网络的类别。 Hamsterster 网络代表网站 http://www.hamsterster.com 成员之间的友谊和家庭联系。 Ego-facebook 网络由使用 Facebook 的调查参与者的好友列表组成。大规模的 Facebook-pages-public-figure 网络描述了不同类别的 Facebook 页面网络。大规模的 NetHEPT 是论文共同作者的协作网络。

这些网络的基本特征如表1所示,其中jVj和jEj分别表示节点和边的数量。 AC是平均聚类系数。本文采用IC模型作为一种广泛流行的影响力传播模型。根据jVj和AC,IC模型中激活概率p的配置如表1所示。此外,选择EDV和TIS这两种流行的代理模型作为IM问题的替代变换。
2) Methods
为了证明 MTEFIM 中知识转移的有效性,通过删除知识转移过程(算法 1 中的第 10 13 行)构建了 MTEFIM 的变体版本 MTEFIM-NK。此外,四种流行的EMTO方法被作为比较算法来说明所提出的知识转移策略的有效性,包括MFEA[33]、MFEAII[36]、EMEA[34]和SBEA[35]。 MFEA是第一个针对MTO问题量身定制的方法,已应用于许多实际问题[58]、[59]、[60]、[61]。 MFEAII 试图最小化任务之间的负迁移趋势,以提高 MFEA 中的知识利用率。 EMEA 是一种显式 EMTO 算法,使用去噪自动编码器执行跨任务的单独传输。 SBEA 是一种新颖的多任务优化算法,其灵感来自于生物群落中的共生。所有方法都使用相同的遗传算子和本文提出的 SOSS 进行公平比较。 MFEA和MFEAII中的种群大小为200,其他方法中每次变换的种群大小设置为100。交叉和变异的概率相应设置为1.0和1/k。所有方法中函数评估的最大数量设置为 5000 S,其中 S 是变换数量。
选择IM问题的八种流行方法作为基线来验证MTEFIM的性能,包括Degree[62]、PageRank[63]、SDD[10]、CELFþþ[14]、EDVEA[18]、TISEA[19]、MA -IM[20]和EDRL-LM[26]。Degree、PageRank和SDD是三种流行的启发式方法。这些方法根据不同的指标对节点进行排序,然后选择前 k 个节点作为种子集。 CELFþþ 是一种改进的贪婪算法,它利用目标函数的子模块性。该方法中蒙特卡罗模拟的次数设置为10000。采用三种流行的基于遗传算子的 EA 作为比较算法。 EDVEA和TISEA的优化目标相应为EDV和TIS。这些方法中使用相同的遗传算子以进行公平比较。 MA-IM 是一种流行的 IM 问题模因算法帽子包含两个主要组成部分,特定于问题的群体初始化和基于相似性的本地搜索。 EDRLLM 是最先进的进化深度强化学习框架,用于 IM 优化 2 跳影响力传播。所有对比方法的其他参数均与原论文一致。
B. Analysis of Knowledge Transfer Process

表II列出了MTEFIM和MTEFIM-NK在20次独立运行中获得的影响力分布,其中所选种子集k的大小设置为3、12、21和30。符号“ ”、“þ”和“ –”表明 MTEFIM-NK 在 Wilcoxon 秩和检验上与 MTEFIM 相似、明显优于或较差,置信度为 0.95 [64]。最佳值以粗体表示。
对于小规模的社交网络,如 GN-Network、Email ERIV 和 Hamsterster,MTEFIM-NK 和 MTEFIM 都可以找到很好的种子集。对于 Egofacebook、Fb-pages-public-figure 和 NetHEPT 等大型社交网络,MTEFIM 的性能优于 MTEFIM-NK。此外,随着 k 或 N 的增加,MTEFIM-NK 和 MTEFIM 之间的性能差距变得更大。这些现象表明,随着复杂网络优化难度的增加,例如网络节点的数量和搜索空间的维数,知识转移的有效性变得越来越明显。总体而言,与 MTEFIM-NK 相比,MTEFIM 在 12 个案例中表现更好,在影响力传播方面,16 个案例中 4 个案例并列,这表明了 MTEFIM 中知识转移过程的有效性。通过在 EDV 和 TIS 之间转移个体,在进化过程中利用了共同知识。

图 8 MTEFIM 和 MTEFIM-NK 在 20 次独立运行中 k 1⁄4 30 的两个代表性网络上的平均收敛趋势,其中 x 轴代表 EDV(TIS) 值,y 轴代表函数评估。 (a) 电子邮件 URIV-EDV,(b) 电子邮件 URIVTIS,(c) Facebook-pages-public-figure-EDV,以及 (d) Facebook-pages-public-figure-TIS。
MTEFIM和MTEFIMNK在两个代表性网络上的平均收敛趋势如图8所示,进一步说明了知识转移过程的有效性。从图8可以看出,在EDV和TIS两种变换的平均收敛趋势上,MTEFIM总体优于MTEFIM-NK。与 MTEFIM-NK 相比,MTEFIM 在 10000 次函数评估内收敛速度更快。这种现象在更复杂的 Facebook-pages-publicfigure 网络上尤为明显。基于上述观察,可以推断MTEFIM中的知识转移过程可以显着增强收敛性能。
此外,为了验证所提出的知识转移过程的效率,在两个代表性网络(小型电子邮件 URIV 网络和大型 Fbpages-public-figure 网络)上将 MTEFIM 与 MFEA、MFEAII、EMEA 和 SBGA 进行了比较,如图9所示。在这些图中,x轴表示种子集k的大小,y轴表示影响力分布的值。
总体而言,MTEFIM 表现出一贯的卓越性能。所有方法获得的影响力分布随着k的增加而稳定增加。首先,就电子邮件 URIV 网络中不断增加的范围而言,所有方法都会产生相似的结果。这可能是因为确定种子集并不困难在小规模网络上。因此,不同方法获得的种子集并没有表现出明显的区别。那么,在大规模的Fb-pages-public-figure网络中,不同方法的性能差距就很明显了。 MTEFIM 中知识转移过程的效率得到了证实,因为除了知识转移之外,所有 EMTO 方法都具有相同的基本遗传操作和选择输出种子集策略。由于 MFEA 中的知识转移是无目的的,因此 MFEA 无法跨转换自适应地转移共享知识。在本文采用的种子集编码策略中,多个个体可能代表相同的种子集,
如图10所示。这种现象可能导致MFEAII、EMEA和SBGA中知识转移过程的低效率。以MFEAII为例,代表同一种子集的不同个体可能会影响当前任务概率分布的准确表示,导致模型不准确。在知识转移策略中,估计种子集之间的重叠程度来捕获转换之间的关系,从而避免了这个问题。
C. Analysis of Inter-Transformation Relationship Estimation
相互转换关系 R 对于控制 MTEFIM 中转换之间的知识转移程度至关重要。通过在线计算种群之间的重叠程度,变换之间的知识交换在进化过程中是自适应的。

图11显示了四个代表性社交网络上MTEFIM中参数r12的图示,其中k设置为30。在这些图中,x轴表示函数评估,y轴指参数r12。
这些曲线突出了 EDV 和 TIS 转换对之间的协同作用。如图 11 所示,在所有网络上估计 r12 的值都很高,这表明 EDV 和 TIS 之间具有很高的相似性。这与适应度景观之间相似性分析的结论一致(见图1)。因此,基于观察,转换间关系估计可以捕获转换之间的潜在协同作用。另外,转移的个体数量由r12决定。在不同的进化阶段,估计的r12自适应地引导不同程度的知识交换,以加速MTEFIM收敛。
D. Analysis of Selecting Output Seed Set
在获得每次变换的最优个体后,综合考虑个体在所有变换中的综合表现来选择最终的输出种子集。表 III 列出了 MTEFIM 在 4 个代表性网络上使用 MCSS 和 SOSS 获得的两个输出种子集在 20 次独立运行中相同的概率,其中用户的先验偏好 C 设置为 1/S 以平等对待每个转换。
从表3可以看出,MCSS和SOSS在大多数情况下选择相同的输出种子集,这表明所提出的输出种子集选择策略的有效性。值得注意的是,在大规模的Fb-pages-publicfigure网络中,所有变换中整体表现最好的个体并不一定是蒙特卡罗模拟中最好的。这可能是因为不同变换的搜索过程中存在一些偏好知识,导致最优的个体偏差。然而,所提出的方法提供了一种有效的输出种子集选择策略,避免了昂贵的蒙特卡罗模拟。
E. Analysis of Selecting Transformations
在本节中,进一步展示了具有不同变换的 MTEFIM 的性能。除了EDV和TIS之外,还考虑了另一种常用的变换——概率排序(PS),它是典型的扩散模型约简代理模型[29]。 PS 计算所研究的社交网络的简化代表实例。在PS上进行单次扩散模拟,以近似原始社交网络上的扩散过程。表IV列出了小规模GN网络和大规模NetHEPT网络在20次独立运行中不同变换组合所获得的影响分布,其中所选种子集k的大小设置为3、12、21和30。与单独优化每个变换相比,优化任意变换组合在影响力传播方面具有更好的性能,其中被转移个体携带的有用知识可以被有效地共享。此外,不同的变换组合具有相似的性能,这也表明所提出的方法可以应对不同代理模型的场景,而不是针对某一特定模型进行定制。
F. Performance Comparison
为了进一步验证MTEFIM的有效性,在影响范围和计算时间方面进行了多次对比实验。图 12 报告了各种 IM 方法对 GN 基准网络和现实社交网络的影响分布。

图 12(a)中的实验结果表明,MTEFIM 在 GN 网络中比启发式方法(Degree、PageRank 和 SDD)具有更好的性能,这一观察结果在现实世界网络中也很普遍(见图 12)。 12(b)-(f))。随着种子集k(搜索空间)大小的增加,启发式方法更有可能陷入局部最优。这是因为他们注重提高开发景观的能力,而忽视了探索景观的能力。如图 12(b)-(f) 所示,不同的 IM 方法在现实网络中具有不同的性能。在图12(b)中,九种算法的影响力传播对于电子邮件网络的差异并不明显。随着k的增加,所有方法获得的影响都在稳步扩大。与单一变换相比优化方法中,EDVEA、TISEA、MTEFIM产生了较好的结果。这意味着 MTEFIM 可以在搜索过程中同时利用独特知识的所有转换来显着提高性能。这种观察结果在大型社交网络中更为明显(见图 12(e))。在图 12(b) 和 (c) 中,对于仓鼠和 Ego-facebook,CELFþþ、EDRL-LM 和 MTEFIM 在影响力传播方面取得了相似的结果。当 k > 15 时,MTEFIM、EDRL-LM 和 CELFþþ 的性能优于所有其他方法。在图13(e)中,对于大规模的Fb-pages-public-figure网络,MTEFIM与CELFþþ类似。 Degree 和 EDVEA 的影响范围随 k 缓慢增加。这可能是因为这些方法忽略了重叠的二级邻域。在图12(f)中,对于NetHEPT网络,MTEFIM优于所有其他基线方法,这进一步说明了MTEFIM在大规模网络上的有效性。总体而言,所提出的MTEFIM在不同规模的社交网络上都获得了极具竞争力的结果。
GN网络具有清晰的社区结构,没有明显的异构结构信息。与GN网络相比,真实网络呈现出更加异构的结构信息。图 12 显示 MTEFIM 在合成 GN 网络中全面优于贪婪方法 (CELFþþ)。在大多数现实网络中,MTEFIM 与 CELFþþ 相比具有极具竞争力的性能。这是因为CELFþþ的主要贪心原理是根据网络的异构信息剪裁的,而本文应用的MTEFIM不依赖于特定的网络结构属性。此外,现实网络表现出节点的无标度特性,这使得通过少量高节点度的节点获得良好的影响力传播成为可能。

图 13 显示了 GN 基准网络和现实社交网络上的比较方法的运行时间分析,其中计算时间是指 k 1⁄4 3, 6, 10 种配置中方法的运行时间总和。 9、...、30。首先,由于Degree、SDD和PageRank这三种启发式方法只需要根据指标对节点进行排序,然后选择前k个节点作为种子集,因此它们的计算成本非常微薄。另外,PageRank的运行时间随着网络规模的扩大而迅速增加。其次,单变换优化方法 EDVEA 和 TISEA 在计算成本方面比 MTEFIM 表现更好。然而,MTEFIM可以通过同时优化EDV和TIS来找到更高质量的种子集。第三,MA-IM和EDRL-LM的计算成本高于其他基于进化的方法,因为MA-IM中的局部搜索和EDRL-LM中的模型学习的计算成本很高。最后,所提出的 MTEFIM 以低得多的计算成本实现了与 CELFþþ 高度竞争的性能。
V. Conclusion
受社交网络中影响力最大化的不同转换的相似性和独特优势的启发,本文引入了一种新颖的多转换进化框架。通过考虑不同转换的种子集之间的重叠程度,该方法可以捕获转换间的潜在关系,从而控制知识转移过程的频率和程度。此外,还提供了输出种子集选择策略,以避免用户手动选择。采用一些基准测试和现实社交网络的实验来说明上述主张的合理性。与EMTO和IM特定方法相比,MTEFIM可以以较低的计算成本获得高质量的种子集。
由于 IM 的广泛应用潜力,以下主题值得进一步研究。首先,从理论上探讨 IM 转换之间的关系仍然是值得的。其次,一系列基于群体智能的 IM 方法表现出了非凡的性能 [21]、[22]、[24]、[25]、[46]、[47]、[48]。可以考虑跨越群体智能优化方法中的多个转换的知识转移过程设计,以增强 IM 的性能。最后,应用MTEFIM解决更复杂的IM问题,例如竞争性IM[28]和多轮IM[65]、[66]也是一个有前途的研究课题。















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









