








本文提出了一种利用图嵌入和图神经网络来进行影响力预测的模型SGNN。具体来讲,作者将影响力最大化考虑成一个伪回归任务:首先利用struc2vec得到节点的嵌入表示,然后将嵌入表示输入到GNN中得到节点的最终表示,最后将最终表示输入到一个回归器中对影响力进行预测。模型训练时,回归标签为节点的影响力(通过SIR模型得到每个节点的传播规模)。
abstract
随着近年来科技和移动网络的蓬勃发展,在线社交网络已经成为我们日常生活中不可或缺的一部分。这些虚拟网络将世界各地的人们连接起来,为他们提供了极好的平台来推广他们的产品和想法。通常情况下,在社交网络中,某些用户比其他用户更有影响力。有效识别有影响力的用户以最大化网络中特定信息的过程称为影响力最大化( Influence Maximization,IM )。在本文中,我们利用图嵌入和图神经网络的思想,提出了一种新颖的影响力最大化方法。本研究拟将复杂网络中的影响力最大化问题转化为伪回归问题。作为我们方法的一部分。
1. Introduction
如今,各种在线社交网络( Online Social Networks,OSNs ),如Twitter,Facebook,Instagram等,已经使世界成为一个超连接的全球世界,并为用户之间发生各种社会交往提供了虚拟平台。这些OSNs为用户提供了一个共享和推广新思想、产品或信息的理想平台。一个在线社交网络可以被建模为一个图G 1 ? ? V;E Þ,其中V表示网络中存在的人或实体的集合,E表示边。社交网络中两个实体之间的边对应着一种虚拟的熟人关系,如朋友关系和追随关系。由于在这些社交网络上存在着许多来自世界各地的用户有助于以更快的速度促进信息的传播。影响力节点是具有高传播能力的节点,源自它们的一条信息可以通过触发信息扩散级联在网络中达到最大程度。为影响力最大化任务识别有影响力的节点是网络科学[ 1、2 ]领域的热门研究课题之一。形式化地讲,影响力最大化的任务可以表述为"给定一个被建模为图G的复杂网络和一个非负小数k,找到k个种子节点的集合S,使得通过初始激活它们,可以在一定的信息传播模型下最大化整体的影响力传播规模"。

其中 S 是受种子集 S 和 rG 影响的用户数量;MðS Þ 是受 S 影响的预期用户数量。病毒式营销是影响力最大化的流行应用之一,公司打算通过扩散级联从最初选择的有影响力的种子节点接触大量用户。基于口耳相传的概念并利用用户之间的相互信任,来自有影响力节点的信息可以最大程度地到达网络,从而构成病毒式营销的基础[3,4]。各种社交网络在业务推广和病毒式营销方面的优势因其低成本和信息传播快而被普遍接受[5]。 据观察,信息的级联、传播和同步、谣言控制、社会推荐、政治竞选等许多现象都受到网络中某些特定影响力节点的影响[6,7]。肯佩等人。 [8]证明,在经典扩散模型下获得影响力最大化问题的最优解是一个NP难优化问题。多年来,我们在影响力最大化领域做了大量工作。其中,基于节点中心性和基于贪婪的方法更受欢迎。基于节点中心性的方法根据某些拓扑特征及其在网络中的相对位置为每个节点分配分数。基于节点中心性的方法在计算上具有成本效益,但结果是特定于网络的,不能有效地推广到其他网络。另一方面,基于贪婪的方法通常更准确,理论上可以保证性能,但计算量较大[8,20,21]。
网络的巨大规模和复杂性往往会导致在网络上执行任何有意义且有效的任务时产生大量的计算成本。图嵌入是一种将网络节点的经典表示转换为低维向量空间的技术,可有效地用于各种网络分析任务。另一方面,图神经网络(GNN)通过消息传递机制优化局部和全局目标函数来处理节点特征,以获得每个节点的新特征向量。影响力最大化领域现有的大部分工作都致力于利用网络的结构特征来确定网络节点的相对分数,以区分网络中节点的可能影响能力。
我们提出了一种通过将影响最大化问题视为伪回归任务来解决影响最大化问题的新方法。利用利用网络中节点的结构身份的思想,我们的模型在算法的初始阶段采用 struc2vec 节点嵌入来为网络中的每个节点生成嵌入。然后,这些节点嵌入充当网络中节点的特征向量。然后我们利用图神经网络(GNN)的消息传递系统。从 struc2vec 生成的节点嵌入被传递到基于 GNN 的回归器上。我们使用 SIR 信息扩散模型 [9,10] 计算训练网络中每个节点的影响。计算出的影响形成训练模型时回归任务的标签。然后使用经过训练的模型通过回归来预测对测试网络的可能影响。最后,我们根据预测的影响力选择前 k 个节点,从而选择大小为 k 的种子集。我们提出的工作 SGNN 的性能与几个合成和现实网络的易感感染恢复(SIR)扩散模型和独立级联(IC)模型下影响最大化的几种当代算法进行了比较。实验结果表明,所提出的方法通过优化识别网络中的影响力节点,提供了比几种当代影响最大化方法更好的结果。我们工作的主要贡献如下。
1. (i) 我们提出了一种使用 Struc2vec 嵌入和基于图神经网络(GNN)的回归器的名为 SGNN 的影响最大化的新方法。
2.(ii)我们将影响力最大化问题解释为伪回归任务,以便可以利用多种深度学习和机器学习技术来完成该任务。
3. (iii) 我们使用 LSTM 单元作为模型 GNN 部分的邻域聚合器函数。我们尝试优化回归器段的计算影响力和预测影响力之间的误差。
4. (iv) 我们对几个合成网络和现实网络进行了深入的实验,这揭示了我们的模型与其他影响力最大化算法相比具有值得称赞的性能。
本文的其余部分组织如下:第 2 节讨论了影响力最大化领域之前所做的一些工作。第 3 节介绍了更好地理解这项工作所需的概念。第 4 节详细描述了我们提出的方法。第 5 节提到了我们用于本研究目的的数据集和评估指标。第 6 节提供了我们获得的实验结果及其分析。最后,第 7 节提到了结论性意见和未来工作的范围。
2. Related Work
在本节中,我们讨论复杂网络影响力最大化领域现有的研究工作。近年来,社交网络分析领域的影响力最大化问题得到了广泛的研究。基于中心性的算法是对节点传播能力进行排名的流行方法。此类方法利用网络的拓扑结构为每个节点分配分数,选择分数高的节点作为种子节点。
度中心性[14]估计节点的局部重要性,并将分数分配给每个节点,该分数等于该节点的直接邻居的数量。介数中心性 [14] 根据经过特定节点的每对节点之间的最短路径的比例来确定节点的重要性。根据接近中心性,如果一个节点到所有其他节点的路径距离最短,则该节点更相关[15]。一般来说,与外围节点相比,位于网络核心的节点对传播影响力的贡献更大,基于这一假设,Kitsak 等人。 [16]提出K-shell中心性。它将从外围开始到内壳的节点进行修剪,并将 Kshell 值逐级分配给每个节点。 K 壳中心性的一个主要缺陷包括为同一壳中存在的所有节点分配相同的分数。为了改善这一点,Bae 等人。 [17]提出了邻域核心性(NC)中心性,通过添加其邻居的 K-shell 值,能够区分位于同一 K-shell 中的顶点的扩展能力。使用投票过程的概念引入了一些寻找有影响力节点的技术[18,19]。在每一轮中,每个节点向其邻居提供选票,获得最高票数的节点被选为该轮中的传播者。
文献中存在许多针对 IM 问题的基于贪婪的算法 [8,20,21],它们利用独立级联 (IC) 模型的子模性和单调性以及蒙特卡罗模拟来改善影响扩散。通常,基于贪婪的算法比基于节点中心性的方法产生更好的结果,但由于许多蒙特卡洛模拟而具有较高的时间复杂度。影响力最大化问题是子模问题,并且是 Kempe 等人证明的 NP 难问题。 [8]使用贪心方法。莱斯科维奇等人。 [20] 提出了一种改进且高效的基于贪婪的算法,名为 CELF,通过利用基于选择种子的“惰性前向”优化的子模块性。 CELF 的计算成本效益往往比基于贪婪的框架高 700 倍。他们采用了幂律原理的思想,并假设社交网络中的大多数节点影响力非常小,因此可以在后续迭代中轻松修剪。它建立在各种现实世界网络表现出子模块属性的事实之上,并致力于利用网络的这种属性来提出可扩展的贪婪算法。戈亚尔等人。 [21]提出了CELF++,它是对CELF算法的改进,通过利用影响传播模型的扩展函数的子模特性来避免不必要的蒙特卡罗模拟重新计算。近年来,文献中引入了许多基于混合的影响力最大化方法。贝拉曼德等人。 [22]提出了DCL算法,该算法考虑了节点的位置参数,例如度、邻居度、节点与其邻居之间的公共链接以及逆聚类系数。萨拉瓦蒂等人。 [23]提出了GLR算法,该算法利用节点的局部网络结构来改进紧密中心性计算,然后利用该信息根据节点的可能影响力对节点进行评分。文等人。 [24]提出了一种通过考虑中心节点(i)周围的局部结构特性,使用局部信息维度(LID)来识别有影响力的传播者的方法。该方法通过香农熵来衡量盒子内节点的信息。中心节点(i)周围的盒子l的大小从1到ceil(di=2)变化,其中di是中心节点的度数。盒子大小变化的目标表明该方法集中于中心节点的拟局部结构并降低时间复杂度。瑞等人。 [25]提出了RNR算法,该算法利用节点的反向排名信息以及节点的邻居对节点的影响。
最近,影响力最大化的问题也已经使用深度学习技术得到了解决。李等人。 [26]使用网络嵌入和深度强化学习来解决影响力最大化问题并取得了改进的结果。帕纳戈普洛斯等人。 [27]提出了IMINFECTOR,它使用扩散级联的对数来嵌入扩散概率,然后使用这些概率通过贪婪方法找到种子集。田等人。 [28]使用元学习解决了主题感知影响最大化问题。他们提出了一种基于独立级联和基于线性阈值模型的深度影响评估模型。于等人。 [29]提出了一种基于图卷积网络(称为 RCNN)的方法来解决影响力最大化问题。他们为每个节点生成一个特征矩阵,并使用卷积神经网络来训练和预测节点的影响。他们使用 Barabasi-Albert (BA) 模型对模型进行预训练,因为大多数现实世界的网络都可以使用 BA 模型进行建模。这构成了我们选择 BA 模型来训练我们提出的迁移学习模型的基础。选择如此庞大的网络的目的是为了获得模型参数更好的泛化能力。
3. Preliminaries
本节说明了更好地理解这项工作所需的背景概念。
3.1. Graph or Network Embedding
它是一种启发式方法,将网络节点表示为低维向量空间,同时保留网络的结构和拓扑特征[30]。节点的这种矢量表示提高了计算可行性用于执行各种网络分析任务,例如影响力最大化。多年来,人们提出了很多节点嵌入方法,例如基于拉普拉斯特征图[31]的节点嵌入、HOPE[32]、node2vec[33]、SDNE[34]等。这些节点嵌入考虑了第一、第二和网络结构的高阶近似性,以更好地捕获节点的属性和网络的固有动态。 Struc2vec [35] 是一种图嵌入类型,专注于图节点的结构标识。它在向量空间中生成嵌入,其中具有相似结构连接性和方向的节点放置得更近。无论节点和边缘标签或属性如何,它都可以识别结构。它也适用于未连接的图,通过识别图的不同组件中的相似节点。它系统地开发了一个结构层次结构,以获得局部和全局层面的相似性。 struc2vec 还为网络中的节点生成随机上下文。这些是具有与网络上的加权随机游走观察到的相似结构的节点序列。语言模型可以进一步使用它来学习网络中节点的潜在表示。
3.2. Graph Neural Network (GNN)
图神经网络 [12] 是先进的深度学习模型,它通过网络节点之间的消息传递技术来利用节点的连接性。 GNN 凭借邻域聚合特性改进了基本的神经网络模型,该特性在每次迭代中从任意深度的邻域收集信息。总体而言,GNN 倾向于通过局部聚合器函数从其邻域子图获取节点的信息,同时也为全局聚合器函数生成值。 GNN 根据节点在网络中的连通性和相对位置,为每个节点提供经过处理的属性形式。这些属性被更新,旨在优化与网络相关的损失函数。
3.3. Information Diffusion Models
本节介绍本工作中使用的各种信息传播模型。一般来说,信息扩散模型是可以对信息在网络中传播进行建模的数学模型[36]。本文使用的信息扩散模型有:易感感染恢复模型(SIR)和独立级联模型(IC)。
1. (i) SIR信息扩散模型:SIR模型是一种被广泛研究的流行病学模型。它主要用于计算特定时期内人群中感染传染病的人数并预测疾病的升级。 SIR模型还用于分析谣言、信息和生物疾病等多种传播过程。整个群体可以分为易感个体、感染个体和康复个体,因此,该模型中的每个节点都包含三个离散状态。第一个状态是易感状态 SðtÞ,表示尚未受到影响的易感人群数量。第二个和第三个状态是感染状态和恢复状态,分别用 IðtÞ 和 RðtÞ 表示。最初,除了少数名为传播者节点的节点处于受感染状态外,所有节点都处于易感状态。感染者可以将疾病传播给易感者,而康复者不会再次受到影响。 b为易感者与感染者之间的传播系数,c为感染者的康复率。受感染的节点以 b 的概率将疾病传播到其易受影响的邻居,然后以 c 的概率进入恢复状态。该模型基于这样的假设:一旦康复,个体就会对该疾病免疫并且不会再次感染。 FðtÞ是t时刻被感染节点和恢复节点的总和,可以用来评估当时最初被感染节点的影响力。随着时间t的增加; FðtÞ 也会增加并在最后变得稳定。重复此过程,直到网络中没有受感染的节点。
2. (ii) 独立级联模型:IC 模型是一种信息扩散模型,其中每条边都与感染概率相关。该概率是根据地理邻近性、交互频率或历史感染痕迹来分配的。在该模型中,信息流通过网络级联发生,每个节点要么处于活动状态,要么处于非活动状态。处于活动状态的节点表示扩散中的信息已经影响了该节点,而如果该节点不知道该信息或尚未受到该信息的影响,则该节点处于非活动状态。最初,只有一些名为传播节点的节点接收信息并变得活跃。这些活动节点可以根据与该边对应的传播概率在下一个离散步骤中影响不活动邻居。无论成功与否,该节点只有一次机会激活该特定的不活动邻居,并且永远不会再有机会。假设,如果 G 是给定网络,p 是描述传播概率的常数,则在时间 t; p 是活动节点 v 感染其不活动邻居 u 的概率。如果 v 成功,则节点 u 将在时间 t + 1 时变为活动节点。在其他情况下,如果 u 的邻居数量大于 1,则有v 没有特定的顺序尝试感染其邻居,并且此过程将继续,直到没有节点可以激活。
4. Proposed Work
在本节中,我们详细介绍了我们提出的影响力最大化方法。影响力最大化问题中的重要活动之一是根据通过适当方法计算出的可能影响力对节点进行排序。
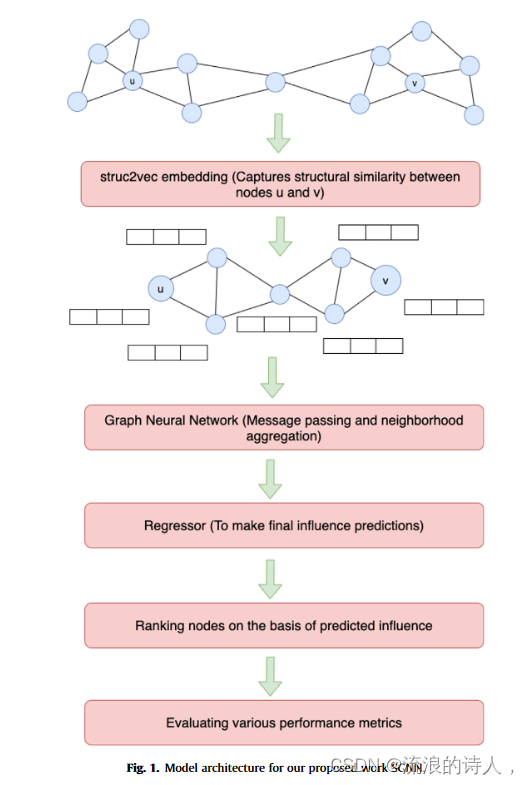
这些可能的影响形成了一组连续的值。因此,我们将影响最大化问题解释为预测一组连续值的任务,这些值形成基于特定节点特征的伪回归活动。节点特征应保留节点的结构身份及其在网络中的拓扑特征。为了提取和处理这些节点特征,我们利用 struc2vec 节点嵌入为网络的每个节点生成合适维度的特征向量。这简化了在网络上执行的各种机器学习和深度学习任务的适用性。生成的节点嵌入由 GNN 架构进一步处理。然后将这些处理后的嵌入传递给回归器,以预测网络中节点实现的最终影响力传播。我们算法的底层功能是在训练网络上训练所提出的基于 GNN 的模型以获得模型参数,然后在目标网络上使用该训练模型来执行影响最大化。通过计算信息扩散模型下训练网络节点的个体影响力来生成训练模型所需的标签。图 1 显示了我们提出的工作的整体模型架构,它描述了所提出的方法如何充当端到端框架来预测网络中节点的可能影响。该网络作为模型的输入。然后,该模型使用 struc2vec 嵌入为网络中的节点生成嵌入。然后,这些嵌入由 GNN 的消息传递和邻域聚合机制进一步处理。 GNN 生成的输出随后被输入回归器,以对网络中的节点进行可能的影响预测。然后根据节点的预测影响力对节点进行排名,从而评估各种性能指标。
我们提出的方法的各个算法步骤可以表述如下。
4.1. Label Generation
在我们的研究中,我们将影响力最大化问题解释为伪回归问题。然而,对于任何回归任务,我们都需要一组明确定义的连续标签。沿着这些思路,我们还需要标签来回归网络特征以进行训练。我们利用 Barabasi-Albert (BA) [11] 合成网络的几种变体作为训练网络来训练我们的模型以实现影响力最大化任务。选择不同复杂度的 BA 网络的目的是为了更好地理解我们的 SGNN 模型影响力最大化的性能能力。为了沿着伪回归任务的思想发展,我们在SIR信息扩散模型下计算每个节点在训练网络中的影响力。计算出的影响形成了用于训练回归任务的 SGNN 模型的标签。对于选定的信息扩散模型(IDM),标签集(label)表示计算出的图(G)中每个节点的影响力可以表示如下。
![]()
4.2. Feature Generation using struc2vec Embedding
大多数现实生活中的网络(例如在线社交网络)正在不断发展,规模庞大,并且通常难以处理和分析。一些网络还关联特定的节点属性,但并非所有网络都如此。为了解决这个难题,我们使用节点嵌入技术为每个网络生成节点属性。因此,我们的目标是提供一个通用的影响力最大化框架,利用网络结构来生成网络中节点的特征。作为这项工作的一部分,我们采用基于 struc2vec 节点嵌入的方法为网络中的每个节点生成低维向量。这些向量的维数选择为 128,以更好地捕获网络细节,同时降低处理网络的计算成本。在网络节点上使用 struc2vec 执行特征生成后,我们为网络中的每个节点获得大小为 128 的特征向量。令 S 为使用维度为 d 的 struc2vec 为图 G 生成的节点嵌入。我们获得嵌入如下。
![]()
S是网络中所有节点的嵌入集合。因此,节点 v 的嵌入可以表示为:
![]()
这里,sv 表示为网络的每个节点 v 生成的嵌入。因此,对于网络中的每个节点,我们获得一个特征向量,该向量在下一步中进一步传递到 GNN 架构中进行处理。
4.3. Feature Processing using GNN
在此步骤中,我们讨论使用神经图网络(GNN)进行特征处理。 GNN 是基于人工神经网络的模型,它使用图节点之间的消息传递和邻域聚合来捕获图信息。它有助于表示来自任意深度的节点的邻域的信息,定义从该节点形成邻域的跳数。 GNN 架构进一步增强和增强了 struc2vec 捕获的网络细节。这有助于更好地举例说明网络节点的结构细节。 GNN 中的聚合函数可以是参数的,也可以是非参数的。在我们的研究中,我们考虑参数聚合器函数,因为它通过不断更新学习参数的值来更深刻地捕获网络的复杂结构以获得更好的结果。 GNN 生成一个最终状态向量,表示网络中每个节点 v 的特征,如下所示
![]()
这里,hv是为节点v生成的最终状态向量; sv 是上一步中为节点 v 生成的嵌入,hne1⁄2v 是 v 的邻居的状态向量,sne1⁄2v 是节点 v 的邻居的嵌入。GNN 的邻域聚合器函数表示为f,也称为局部转移函数。我们使用长短期记忆 (LSTM) 细胞作为本研究的聚合函数。选择 LSTM 单元是因为它们是经典循环神经网络的进步,在更新模型参数时可以很好地抵抗梯度消失。令 H 为根据式(1)堆叠所有状态得到的向量。 3 S 是网络中所有节点的堆叠嵌入。因此,我们可以表示方程。 5 紧凑形式如下
![]()
其中 F 是全局转换函数,是图中所有节点的 f 的堆叠版本,而 H 是方程的固定点。 6. 所使用的 GNN 按照以下等式更新状态向量。

其中 Hi 表示 H 的第 i 次迭代(所有堆叠在一起的节点的最终状态向量)。
4.4. Final Influence Spread Prediction using a Regressor
一般来说,回归器用于输入数据点的一组特征并生成一组连续的值作为输出,同时优化损失函数。回归器是所提出的 SGNN 架构的一部分,用于预测网络中可能的影响。 GNN 在前面的步骤 4.3 中生成的最终特征向量被输入到回归器中。回归器使用均方误差 (MSE) 作为损失函数来优化训练阶段的模型行为。经过训练后,整个模型将用于预测目标网络中节点的可能影响。回归器的工作是将影响预测作为一组连续值。然后根据节点的预测影响来排列节点。排序后的前 k 个节点形成启动信息传播所需的种子节点集合,其目的是最大化影响力传播。设 Infv 为节点 v 的预测影响力,可以表示为:
![]()
这里,o是回归函数,也称为局部输出函数,b是回归参数的集合。令 INF 为通过堆叠网络中所有节点的所有预测 Infv 构建的向量。形式上,它可以表示如下。
![]()
其中 O 是全局输出函数,并且是图中所有节点的 o 的堆叠版本。损失函数可以表示为

其中Calcv是计算出的对节点v的影响。所提出的算法尝试使用梯度下降法来减少损失值。聚合器函数 F 的权重 W 的梯度是根据损失函数计算的。聚合器函数 F 的权重 W 根据计算的梯度进行更新。对于作为权重向量 W 的第 i 个分量的 Wi,可以使用以下等式来完成。

基于上面讨论的方程,我们推导出训练和测试模型的方程如下。

在这里,SGNNðGtrain; SG火车;标签列车; F ; oÞ 在训练网络 Gtrain 上训练 SGNN 模型,并返回经过训练的 SGNN 模型。经过训练的 SGNNðGtest; StestÞ 为测试网络中的每个节点生成一组预测影响力,Gtest 表示为 Predicted Influence。训练有素的 SGNNðGtest;测试; kÞ 通过选择由具有最高预测影响力的节点构成的初始种子集大小 k 生成最终的感染规模。
4.5. Parametric Analysis
因为我们通过在一个网络上训练 SGNN 并在完全不同的网络上进行预测来进行影响预测。因此,我们进行参数分析以确定最佳训练网络。为此,我们在 BA 模型下创建两组网络,分别用于训练和测试,DTrain 和 DTest,如第 5 节所示。通过在不同训练网络上训练 SGNN 的性能评估如下。

这里 FðtcÞ1⁄2i 1⁄2j 表示由于所选种子集而达到的最终感染规模或影响传播的值,并根据方程进行评估。如图 18 所示,当模型在第 i 个训练网络上进行训练并在第 j 个测试网络上进行测试时,种子集大小 k 以 5 为步长从 10 变化到 50。Dtrain1⁄2i 代表第 i 个训练网络,Dtest1⁄2j 代表第 i 个训练网络。 jth测试网络。此外,SDtrain1⁄2i 和 SDtest1⁄2j 表示第 i 个训练网络和第 j 个测试网络的 struc2vec 嵌入。根据以下方程选择最佳训练网络:

4.6. Algorithms
作为我们研究的一部分,我们提出了两种算法来逐步说明我们的工作。我们的工作依赖于在训练网络上学习模型参数,然后使用这些学习到的参数对目标网络进行影响预测。因此,我们提出两种算法,一种用于训练,另一种用于预测目标网络。因此,我们提出两种算法,一种用于训练,另一种用于对目标网络进行预测。算法 1 描述了训练所提出的 SGNN 模型以实现影响力最大化的过程。算法1以一组训练网络(Dtrain)、一组测试网络(Dtest)、嵌入维度d、信息扩散模型(IDM)、聚合函数(f)和输出函数(o)作为输入。该算法返回最优训练网络来训练模型(Opt Train),并在最优训练网络(SGNNopt)上训练SGNN模型。 SGNNopt是用于对目标网络进行最终影响预测的模型。

算法1的简要描述如下。
1. (i) 步骤 1:此步骤涵盖算法 1 的第 1 行到第 4 行。在这一步中,我们迭代训练网络集 Dtrain 中存在的所有训练网络。我们使用等式 1 为第 i 个训练网络中的每个节点生成维度 d 和标签的 struc2vec 嵌入。分别为3和2。之后,我们使用等式 1 来训练第 i 个训练网络的 SGNN 架构。 13.
2. (ii) 步骤 2:在这一步中,我们迭代测试网络集 Dtest 中存在的网络。使用方程 1 为第 j 个测试网络中的每个节点生成维度为 d 的 struc2vec 嵌入。 3. 最后,我们将第 i 个训练网络和第 j 个测试网络的最终实现的扩展初始化为零。此步骤涵盖算法 1 的第 5 行至第 7 行。
3. (iii) 步骤 3:这一步描述了算法 1 的第 8 行到第 13 行。在这一步中,我们计算模型在第 i 个训练网络上训练时,模型选择的一组种子节点所实现的传播并使用式(1)在第j个测试网络上对模型进行测试。 15. 种子集大小从 10 到 50 不等,每次增量为 5。
4. (iv) 第 4 步:根据上一步中节点实现的各种传播值,我们使用方程式选择最佳训练网络 Opt Train。 17. 此步骤说明了我们算法的第 14 行。
5. (v) 步骤 5:此步骤涵盖第 15 至 17 行。我们使用等式 1 为最优训练网络 Opt Train 中的每个节点生成维度 d 和标签的 struc2vec 嵌入。分别为3和2。然后我们训练我们的 SGNN 架构以获得最佳训练网络 Opt Train 使用等式: 13. 最后,我们返回经过训练的模型 SGNNopt 和最优训练网络 Opt Train。

在最佳训练网络上训练模型后,我们继续对目标网络进行影响预测。该启发式由算法 2 表示。它将训练好的 SGNNopt 模型、目标网络、要实现影响最大化的 Gtarget、嵌入维度 (d) 和种子集大小 k 作为输入。根据算法 2,我们首先为大小为 (d) 的目标网络生成嵌入。然后我们预测网络中每个节点的个体影响。然后按照其预测影响力的降序对节点进行排序,并从这组节点中选择前 (k) 个节点。这形成了大小为 k 的节点种子集 (S)。然后,我们根据生成的种子集评估各种性能指标。算法 2 最终返回种子集或有影响力的传播者 (S) 以及评估的指标。算法2逐行简要描述如下。
1. (i) 第 1 行:首先,我们使用等式计算具有维数 d 的 struc2vec 嵌入。 3为目标网络(Gtarget)。
2. (ii) 第 2 行:我们使用基于等式 1 的最佳训练网络 (SGNNopt) 上的 SGNN 模型生成目标网络 (Gtarget) 中每个节点的预测影响。 14.
3. (iii) 第 3 行:在这里,我们按照预测影响力的降序对节点进行排序。此步骤将预测影响力最高的节点排在顶部,将预测影响力最低的节点排在底部。
4. (iv) 第 4 行:我们选择这些已排序节点中的前 k 个节点以获得大小为 k 的种子集。该种子集由 S 表示,其中包含由我们提出的算法生成的有影响力的节点。
5. (v) 第 5 行:在第 5 行中,我们评估上一步中获得的种子集的各种性能指标。最后,我们返回种子集 (S) 和第 5.2 节中列出的各种性能指标。
5. Datasets and Evaluation Metrics
本节介绍我们选择的各种网络和评估指标,以验证我们提出的模型 SGNN 的性能。
5.1. Datasets
因为,根据所提出的模型的工作原理,我们必须首先在回归任务的训练网络上训练模型。经过训练的模型有助于对测试网络进行影响预测。因此,我们选择两种类型的数据集进行研究,即训练数据集和测试数据集。 S. Kumar、A. Mallik、A. Khetarpal 等人。信息科学607(2022)1617–1636
训练数据集:为了训练网络,我们利用基于 Barabasi-Albert (BA) 模型的合成网络 [11]。选择BA网络是因为现实生活中的各种网络都可以在BA模型上进行建模。此外,对于 BA 网络,网络通过以优先附着方式向节点添加边来增长,类似于现实世界网络的增长方式。但为了更好地了解 SGNN 与训练网络的性能兼容性,我们尝试了几种不同复杂度和维度的 BA 网络。然后我们在预测性能和计算成本方面选择最佳的训练网络。根据训练网络,我们选择六个网络。训练网络表示为Train_n_k:由BA模型生成的无标度网络,有n个节点,平均度为k。 n 取两个值,1000 和 3000,而 k 取三个值,2、4 和 8。所以总共有六个训练网络。
测试数据集:我们选择了六个基于 BA 模型的合成网络和八个现实生活中的社交网络作为训练数据集的一部分。合成网络用于测试改变训练网络的节点大小和平均度对 SGNN 性能的影响。而现实生活中的网络则用于将 SGNN 的性能与一些当代算法进行比较。使用的合成网络表示为 Test_n_k:由 BA 模型生成的无标度网络,具有 n 个节点,平均度为 k。 n 取两个值,2000 和 4000,而 k 取三个值,2、4 和 8。
目标数据集:目标数据集代表我们用来执行各种实验并评估模型的不同性能指标的一组现实网络。选择用于确定所提出的影响最大化方法的性能的现实目标网络如下。
1. (i) Wiki [37]:这是一个代表维基百科自成立以来至 2008 年 1 月的投票数据的网络。网络中的节点代表维基百科用户,而边代表用户之间的投票。该数据集包含 889 个节点和 2914 条边。
2. (ii) Fb-Food [38]:它包含一个关于经过验证的 Facebook 食品页面网络的图网络。节点代表页面,链接代表页面之间的相互喜欢。有620个节点和1483个链路。
3. (iii) Web-edu [39]:Web-edu 是一个基于网络的网络,其中节点代表网页,而边代表网页之间的超链接。网络中有3031个节点和6474条边。
4. (iv) Fb-Messages [40]:这是一个类似 Facebook 的社交网络,代表加州大学欧文分校学生之间通过在线社交社区进行的互动。节点代表学生,边代表学生之间的交互。如果两个学生之间至少发送或接收一条消息,则两个节点之间存在边。有 1266 个节点和 6451 个边,
5. (v) USAir 500 [41]:这是一个代表美国 500 个最繁忙商业机场的网络。节点代表机场,而边存在于两个节点之间(如果 2002 年在两个节点之间安排了航班)。网络中有 500 个节点和 2980 个边。
6. (vi) NB’09 [13]:这是挪威的联锁理事会网络。它代表了自 1999 年 11 月以来挪威上市公司董事会组成的变化。网络中有 1495 个节点和 4065 个边。
7. (vii) Hamster [42]:Hamster 是一个复杂的网络,呈现网站 http://www.hamsterster.com 上各个用户之间的交互。节点代表用户,边代表用户之间的交互。有2426个节点和16630条边。
8. (viii) 比特币[43]:比特币是一个基于信任的网络,供用户在比特币交易平台比特币 OTC 上进行交互。这是一个加权网络,尽管为了保持通用性我们忽略了边权重。该数据集有 5881 个节点和 21492 条边。
 表1列出了所选网络的各种统计细节。这里,bth1ð1=kÞ和bth2ðk=k2Þ是流行病阈值的选定值,其中<k>是网络的平均一阶度,<k2>是网络的平均一阶度。网络的平均二阶度。本工作中的感染率b是在考虑一级和二级的阈值bth1和bth2后选择的,因为b没有标准值,所以我们选择b为0.1以保持网络之间的一致性。
表1列出了所选网络的各种统计细节。这里,bth1ð1=kÞ和bth2ðk=k2Þ是流行病阈值的选定值,其中<k>是网络的平均一阶度,<k2>是网络的平均一阶度。网络的平均二阶度。本工作中的感染率b是在考虑一级和二级的阈值bth1和bth2后选择的,因为b没有标准值,所以我们选择b为0.1以保持网络之间的一致性。
5.2. Evaluation Metrics
为了测试我们提出的基于 GNN 的模型的性能,我们计算了影响力最大化领域中流行的几个性能指标。选择这些指标是为了评估所达到的影响力的传播和效率。还考虑了吊具的相对定位。我们选择的性能指标如下。
1. (i) 最终感染规模或影响传播与种子集大小、FðtcÞ 与 k:我们评估 SIR 模型和 IC 模型的这一指标。 SIR 模型采用初始种子集大小 k、感染概率 b 和恢复概率 c。该模型的工作原理是,在每个阶段,受感染的节点可以以 b 的概率感染其邻居,并且在后续阶段,受感染的节点可以以 c 的概率恢复。为了实验的简单性,我们将c的值取为1,将b的值取为0.1。这意味着每个受感染的节点都将在下一阶段恢复。另一方面,IC模型考虑传播概率p。它指的是单个节点感染其邻居的可能性。在我们的研究中,我们将其视为 0.1。因此,最终的感染规模可以用数学方式表示如下。

其中,nIðtÞ 表示模拟结束时受感染节点的总数,n 表示网络中节点的总数。这些实验是通过不断改变种子集大小 k 来进行的。
2. (ii) 最终感染规模或影响传播与感染概率:该指标被认为可以更好地了解不同模型的感染概率变化对最终感染规模 FðtcÞ 的影响。感染概率表示受感染节点感染其邻居的概率。最终感染规模往往随着感染概率的增加而改善。
3. (iii) 传播器之间的平均距离,ðLsÞ:所选源传播器节点的最佳集合应均匀分布在网络周围。分布器之间的平均距离是一种衡量标准,可以公平地估计这些分布器节点分布的稀疏程度。通常,Ls 的值越高,种子集被考虑得越好,从而减少这些节点的重叠邻域大小。从数学上来说,它可以表达如下。

其中 Duv 是种子集中任意两个节点之间的距离,k 是种子集大小。
4. (iv) Kendall tau 值,s:影响力最大化算法,旨在生成有影响力节点的初始列表。可以通过根据节点在网络中的个体影响力对节点进行排名来创建另一个列表。估计任何影响力最大化算法的经验实用性的一种方法是将这个通用节点列表与正在考虑的算法列表进行比较。如果这些列表相似,则所提出的算法被认为是可行的。 Kendall tau 值衡量两个有影响力节点列表之间的相似性。如果节点 u 在一个列表中出现在节点 v 之前,则它也会按该顺序出现在第二个列表中。每一个这样的对被称为一致对 ðkcÞ,而每一个以其他方式显示的对被称为不一致对 ðkdÞ。从数学上来说,Kendall 的 tau 值可以表示如下。

这里,k是种子集大小,s值从1到1变化。1表示列表完全相似,1表示列表之间的绝对不相似。
6. Experimental Results and Analysis
本节介绍实验设置和我们提出的模型获得的结果,并将其性能与一些当代影响最大化方法进行比较。我们的方法依赖于预先训练基于 GNN 的模型,然后使用该训练模型来预测每个节点在目标网络中的可能影响。基于 GNN 的模型的训练是至关重要的一步,我们还进行了参数分析,以选择用于训练目的的最佳网络。对使用 Barabasi Albert (BA) 模型生成的六个合成网络进行了参数分析。我们通过对第 5 节中提到的不同复杂性、维度和多样性的八个现实生活网络进行实验来研究我们提出的模型的性能。将获得的结果与一些当代影响力最大化算法(即度数、聚类系数和位置)进行比较( DCL)[22]、局部信息维数(LID)[24]、反向节点排序(RNR)[25]、GLR[23]和RCNN[29]。对于每个数据集,我们根据第 5.2 节中提到的信息传播的易感-感染-恢复 (SIR)、独立级联 (IC) 模型下的所有评估标准,获得了各种经过考虑的算法的结果。由于SIR模型将节点种子集、感染概率b和恢复概率c作为输入参数。感染概率(即节点被感染的概率)设置为 0.1,以保持我们在整个网络中的分析的一致性。恢复概率,即受感染节点被恢复的可能性,设置为 1。这意味着一旦节点被恢复,被感染,然后在下一次迭代中,它尝试感染其邻居,然后恢复自身。对于IC模型,我们选择传播概率p为0.1。由于这两个模型本质上都是随机的,因此我们将所有实验进行了 100 次,并对结果进行平均以获得更通用的结果。
6.1. Parametric Analysis
我们进行了参数分析,以确定我们提出的模型 SGNN 的性能能力,以及训练网络的大小和复杂性的变化。我们在六个合成网络上训练 SGNN,并在六个前所未见的合成网络上对其进行测试。所有这些网络都是 Barabasi Albert (BA) 模型的变体,具有不同的复杂性。图 2 显示了在不同训练网络上训练 SGNN 以及通过改变种子集大小对不同测试网络进行测试所获得的结果。 y 轴表示所生成的种子集的影响范围,而 x 轴表示所选种子集大小的不同值。训练网络以Train n k 的形式表示,而测试网络以Test n k 的形式表示。这里,n是网络中的节点数,而k表示BA模型的网络平均度。从图 2 可以看出,为网络训练的模型,Train 1000 4 在整个复杂性中表现得非常好。也与式(1)一致。 17. 它还表明,随着节点数量和网络度的增加,性能提高。然而,在具有较高节点的网络上训练的模型在具有较少节点的网络上表现不佳。考虑到上述分析,我们最终决定使用 Train 1000 4(一个具有 1000 个节点、平均度等于 4 的训练网络)来训练网络。在为 SGNN 选择最佳训练网络后,我们在一些现实世界的网络上进行实验,以确定 SGNN 在现实场景中执行影响力最大化任务的合理性。性能评估是在第 5 节中提到的各种数据集上进行的。下面讨论所提出的方法与基于多个评估标准的几种当代影响最大化算法的详细性能比较。



图 2.(a)-(f) 测试网络的最终感染规模与种子集大小 (k)。 SIR模型下感染概率b设置为0.1。
6.2. Final infected scale or influence spread vs seed set size(FðtcÞ vs. k)
1. (i) SIR 模型:




图 3. (a)-(h) 在不同的现实数据集上通过各种方法获得的最终感染规模与种子集大小值。 SIR模型下感染概率b设置为0.1。
图 3 显示了在 SIR 模型下,通过各种算法在具有不同种子集大小的所有选定数据集上获得的最终感染规模或影响范围。为了绘制 FðtcÞ 的值,所有数据集的种子节点值取值范围为 10 到 50,步长为 5。从图中可以看出,随着种子集大小的增加,最终获得的传播得到改善。图 3(a) 显示了 Wiki 网络获得的结果。对于 Wiki 网络,SGNN 是表现最好的,紧随其后的是 LID,其余算法也紧随其后。从图3(b)可以看出,对于Fb-Food网络,SGNN在最终感染规模或使用不同种子集大小获得的影响扩散方面优于所有其他算法。对于 Web-edu 网络,从图 3(c)中可以清楚地看到 SGNN 再次表现最佳;然而紧随其后的是 LID。对于 Fb-Messages 网络,SGNN 也是表现最好的,如图 3(d) 所示。接下来依次是 LID、DCL 和 GLR。对于 USAir 500 网络,SGNN 再次表现最好,其次是 LID 和其他算法。这可以从图3(e)中观察到。图 3(f) 显示,对于 NB’09 网络,SGNN 也优于所有其他算法。图 3(g)和(h)表明,所提出的方法 SGNN 也超过了 Hamster 和比特币网络的其他算法的性能能力。 FðtcÞ 与 k 的总体结果得出的结论是,就最终感染规模而言,所提出的 SGNN 方法优于所有其他当代方法。此外,与其他几种方法相比,SGNN 在种子集大小范围内表现出示范性的性能和更好的稳定性。这表明 SGNN 作为选择初始种子节点集以获得最大影响力的最佳选择的合理性。
2. (ii) IC 模型:
图 4 描述了使用独立级联 (IC) 信息扩散模型针对不同种子集大小的所有网络的最终感染规模或影响力传播的结果。种子集大小 k 从 10 到 50,步长为 5。对于 Wiki 网络 4 (a),SGNN 表现最好,其次是 RCNN 和 DCL。对于Fb-Food网络,SGNN之后是DCL和RCNN,从图4(b)可以看出。对于 web-edu 网络 4 (c),SGNN 也是表现最好的,其次是 RCNN。即使当种子集大小相对较小时,SGNN 也能提供良好的性能,从 FbMessages 网络 4 (d) 可以看出,其中所有其他算法都难以保持相当大的性能。对于 USAir 500 网络 4 (e),所有算法都提供了有竞争力的性能,但 SGNN 仍然表现最好。对于 NB’09 网络 4 (f) 网络,SGNN 也表现最佳。随着种子集大小进一步增加,这得到了例证。对于 Hamster 4 (g) 和 Bitcoin 4 (h) 网络来说,SGNN 也是表现最好的,尽管随着种子集大小 k 的增加,其他算法开始迎头赶上。上述讨论表明,所提出的 SGNN 方法在种子集大小 k 上实现了更大的最终感染规模。即使对于较小的种子集大小,SGNN 的性能也比其他算法更好。
6.3. Final infected scale vs. infection probability
1. (i) SIR模型:

 图 5. (a)-(h) 在 SIR 模型下通过不同方法针对各种选定算法获得的最终感染规模与感染概率 b 值。初始种子节点的数量取每个网络中节点总数的百分之二。
图 5. (a)-(h) 在 SIR 模型下通过不同方法针对各种选定算法获得的最终感染规模与感染概率 b 值。初始种子节点的数量取每个网络中节点总数的百分之二。
图5描述了改变感染概率对最终感染规模或影响传播的影响。对于所有数据集,传播器的初始数量一直保持在网络中节点总数的百分之二。例如,对于具有889个节点的wiki网络,初始传播器数量选择为0.02*889,即17个节点,对于具有5881个节点的比特币网络,初始种子节点数量选择为0.02*5881,即 117 个节点。对于所有使用的数据集,b 的值选自以下值:0.01、0.02、0.05、0.1、0.2 和 0.5。从结果中可以清楚地看出,随着感染概率的增加,每个数据集中所有方法的最终感染规模趋于增加。对于 Wiki 网络 5(a),所提出的 SGNN 方法优于所有方法,其余方法均优于 -彼此形成非常接近。对于 Fb-Food 网络 5 (b)、Web-edu 5 (c)、Fb-Messages 5 (d)、USAir 500 网络 5 (e) 和 NB'09 网络 5 (f),趋势相同,其中所提出的 SGNN 方法击败了 DCL、RNR 和 LID 等其他方法,但是其余算法的性能之间的区别并不是很明显。如果是与 Hamster 网络 5 (g) 和比特币网络 5 (h) 相比,所提出的 SGNN 方法表现优于其他方法,其次是 LID 和 DCL。此外,随着感染概率的增加,算法性能的差异变得更加明显。因此,可以得出结论,对于较低的感染概率值,获得的结果相当有竞争力。尽管一旦感染概率超过 0.05,SGNN 的性能就表现出色且高效。
2. (ii) IC 模型:

 图 6. (a)-(h) 在 IC 模型下通过不同方法获得的各种选定算法的最终感染规模与传播概率 p 值。初始种子节点的数量取每个网络中节点总数的百分之二。
图 6. (a)-(h) 在 IC 模型下通过不同方法获得的各种选定算法的最终感染规模与传播概率 p 值。初始种子节点的数量取每个网络中节点总数的百分之二。
图 6 显示了随着使用独立级联 (IC) 信息扩散模型改变传播概率,不同网络的各种算法实现的最终感染规模。感染概率p在0.01到0.5之间变化。初始种子集大小选择为网络节点总数的 2%。例如,对于具有 3031 个节点的 Webedu 网络,初始种子集将包含 0.02*3031 = 60 个节点。具有 2426 个节点的 Hamster 网络的初始种子集大小为 0.02*2426 = 48 个节点。从图中可以看出,与其他当代算法相比,随着传播概率 p 的变化,SGNN 是所有网络中表现最好的。此外,与其他性能参差不齐的算法相比,SGNN 在不同的感染概率值下都能提供稳定的性能。上述分析表明,SGNN 在所有选定的网络和 IC 模型的信息扩散模型参数值中提供了一致的性能。
6.4. Average distance between spreaders, ðLsÞ:
 表 2 显示了所有数据集的不同算法所获得的吊具之间的平均距离值。对于所有算法,有影响力的传播者的数量被选择为 50 个。从表 2 可以看出,我们检测初始种子集以获得最大影响力的方法往往会为大多数网络提供最佳结果。从 Wiki、Fb-Food、Hamster 和比特币网络获得的结果可以明显看出这一点,其中 SGNN 是表现最好的。即使对于像 Web-edu 和 Fb-Messages 这样的网络,SGNN 也不是表现最好的,但它仍然可以与一些当代算法相比提供具有竞争力的性能。 SGNN 在该指标上实现的示例性性能表明,传播器是从整个网络中选择的,并且不仅仅聚集到特定的邻域。这可以归因于 struc2vec 嵌入能够捕获整个网络节点之间的结构身份。
表 2 显示了所有数据集的不同算法所获得的吊具之间的平均距离值。对于所有算法,有影响力的传播者的数量被选择为 50 个。从表 2 可以看出,我们检测初始种子集以获得最大影响力的方法往往会为大多数网络提供最佳结果。从 Wiki、Fb-Food、Hamster 和比特币网络获得的结果可以明显看出这一点,其中 SGNN 是表现最好的。即使对于像 Web-edu 和 Fb-Messages 这样的网络,SGNN 也不是表现最好的,但它仍然可以与一些当代算法相比提供具有竞争力的性能。 SGNN 在该指标上实现的示例性性能表明,传播器是从整个网络中选择的,并且不仅仅聚集到特定的邻域。这可以归因于 struc2vec 嵌入能够捕获整个网络节点之间的结构身份。
6.5. Kendal l’s Tau value (s)
表 3 列出了在所有数据集上不同所选算法的 Kendall tau 值获得的实验结果。在计算Kendall’s tau值的SIR模型下,感染概率b的值为0.1。从表中可以得出结论,我们提出的方法 SGNN 往往会在 Kendall tau 值方面给出出色的结果。这可以归因于以下事实:肯德尔的 tau 值根据每个节点的影响力检查列表之间的相似性由正在考虑的算法生成的列表。由于我们提出的方法使用每个节点的影响力进行训练,并根据节点的预测影响力对节点进行排名,因此它往往与通过对每个节点对网络的影响进行建模而生成的列表高度相似。
7. Conclusion
影响力最大化一直是复杂网络分析中研究最多的问题之一。它具有广泛的应用,从病毒式营销到疾病爆发研究,再到识别意见领袖。影响力最大化问题是指选择一组初始种子节点,这些节点在被激活时往往会更快、更有效地传播和传播信息。在这项工作中,我们通过将影响最大化问题解释为伪回归任务来解决它。我们通过结合 struc2vec 节点嵌入和基于图神经网络(GNN)的回归器提出了一种影响力最大化的新框架,以对网络中的节点进行可能的影响力预测。 struc2vec 节点嵌入侧重于生成嵌入的节点的结构标识。然后将这些节点嵌入输入到 GNN 中。嵌入由 GNN 的消息传递机制进一步处理,然后通过回归器进行最终的影响预测。最初,我们在合成网络上训练 SGNN 架构,其中网络中节点的标签是通过计算它们在扩散模型下的影响力来获得的。为了确定最佳的训练网络,我们在多个训练网络上训练模型,并在各种综合测试网络上测试其性能。使用的合成网络是使用 BA 模型生成的。然后使用经过训练的模型对现实测试网络进行影响预测,以了解 SGNN 在现实场景中的功能。然后根据节点的预测影响力对节点进行排名,并选择所需大小的种子集。实验针对 SIR 和 IC 信息扩散模型进行。我们研究了所提出的模型在几个现实生活中的复杂网络上的合理性,并与一些当代影响最大化算法进行了比较。通过对总共八个不同规模和应用的现实网络的实验表明,我们提出的方法提供了示范性的性能,通过根据各种性能指标选择初始种子集来最大化整体影响力。作为这项工作未来增强的一部分,该算法可以扩展到加权网络和不同复杂度的多层网络。














 860
860











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









