







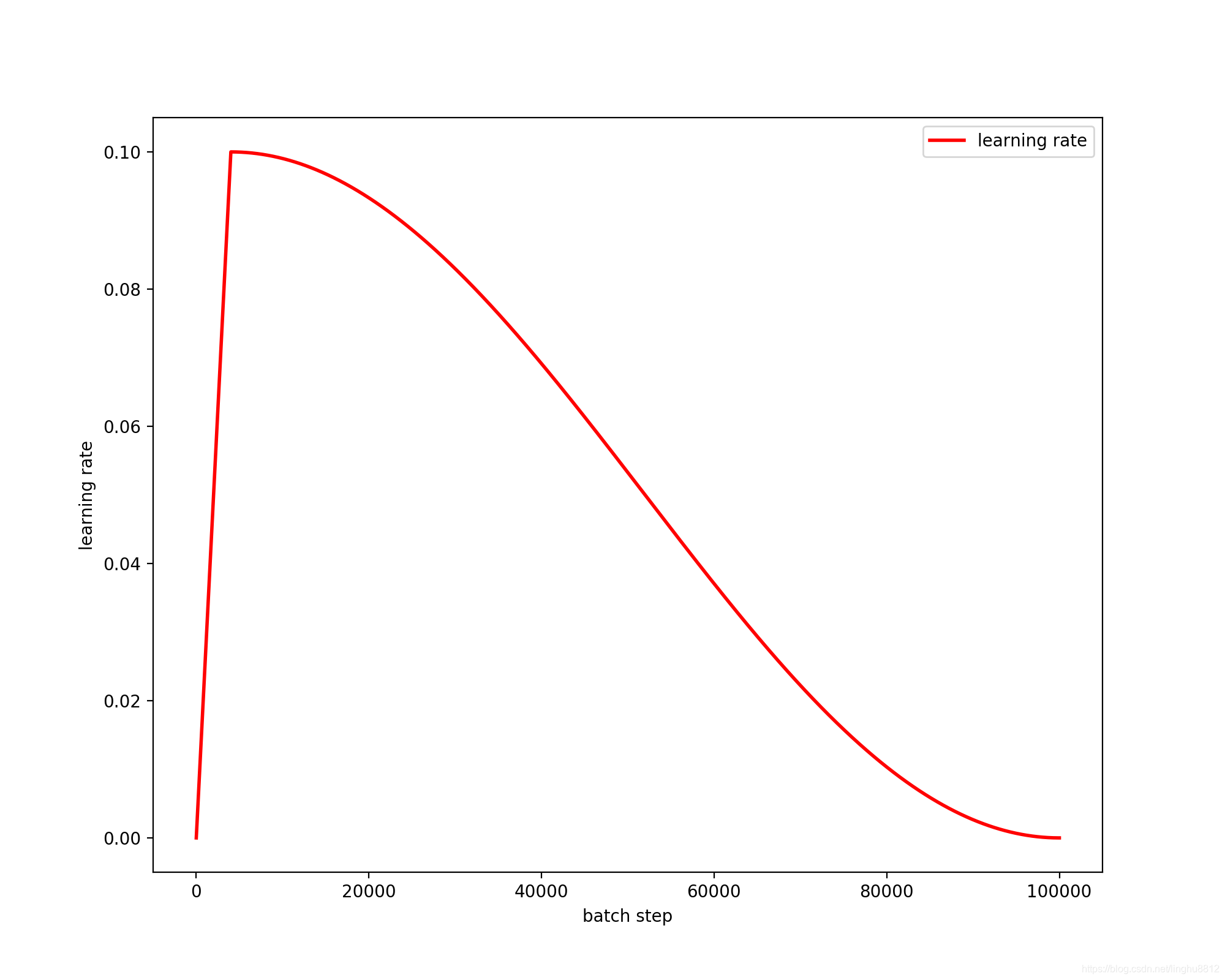
余弦学习率衰减
公式:

需要用到lambda 表达式:
lambda:epoch: (epoch / 40) if epoch < 40 else 0.5 * (math.cos(40/100) * math.pi) + 1)
初始学习率为lr=10^-3
如果是总的100个epoch,只使用后60个应用余弦学习率衰减,那么前40个不作cosine计算,前40个epoch的学习率为:lr1=epoch/40*lr, 那么后60个epoch适用0.5 * (math.cos(40/100) * math.pi) + 1)。
计算得到最末尾的学习率为2.5x10^-4.
eg:


















 414
414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









