






Background & Motivation
小样本图像分类的方法可以用到检测网络特定的模块中,比如 head。小样本检测中由于数据量有限,其测试集尺度空间可能与训练集、预训练模型的尺度空间分布有很大不同。而半监督学习和弱监督学习虽然减轻了人工标注的负担,由于需要大量的训练数据,因此不适合小样本学习任务。
Motivation 是为了解决小样本检测中的多尺度问题,即如何应对小目标。由于 novel 类中的样本有限,因此其尺度空间很有可能与 base 类的尺度空间有所不同,如下图。

而在通常的目标检测任务中可以采用 FPN 来丰富其尺度空间,但是 FPN 和如 SPP Net 中的多尺度学习的方法,都解决不了这个问题,有一个重要原因:
Specifically, multi-scale inputs result in an increase in improper negative samples due to anchor matching. These improper negative samples contain a part of features belonging to the positive samples, which interferes their recognition.

如上图中红色方框内在这张图像中是 neagtive sample,然而在其他图像中(如白色虚线框)中则是 positive sample,这样的话红框里的特征对网络应该是惩罚还是奖励?会导致网络精度的下降,这就是 improper negative sample 的含义。如果有大量数据的话,网络可以学习更多不同的特征而抑制这些 improper negative sample,但是在 few-shot 这种尺度空间十分稀疏的情况下可能会有损网络精度。
Multi-scale Positive Sample Refinement(MPSR)
基于 Faster Rcnn,增加了一个辅助分支来应对上述问题。该分支称为 object pyramid,总的结构包含 Faster Rcnn、FPN 和新增的分支,共享相同的权重:

具体做法是将只包含一个物体的裁剪后的图片 resize 成不同像素大小:
![]()
之后输入到该分支内,与 FPN 中 anchor matching 的方法不同,如果只有一个物体还使用 anchor matching 的话,还会产生 improper negative sample。为了增加正例的尺度同时减少 improper negative sample。该分支的方法是将图片中的物体单独地裁剪出来并 resize 成不同的形状,称作 object pyramid。
We propose an extra positive sample refinement branch to adaptively project the object pyramids into the standard detection network.
根据 object pyramid 中图像的大小激活 FPN 中相应的尺度的特征图和图像中物体的中心位置,之后就与传统的方法一样,输入到 RPN 中。

图片大小与对应的特征层如下:

在该中心点位置放上 {1:2, 1:1, 2:1} 三种不同长宽比的 anchor,这些 anchor 被视为 positive。
To simulate that each proposal is predicted by its center location in RPN, we select centric
features for object refinement.
We also select one feature map at a specific scale for each object to keep the scale consistency, as shown in Table 1.
但是在提取 RoI 特征时只用到了 FPN 的2、3、4、5层,微调了这几层的尺度范围。提取到的特征图再经过池化到统一的大小,之后送入 head。
MPSR 中 RPN 结构的损失函数与 Faster Rcnn 的损失函数差别不大:

Mobj 是输入 object pyramid 分支的 positive anchor 的数量。而 Detection Head 的损失函数如下:

将 Mroi 单独列出来是因为 Mroi 远小于 Nroi,并且需要一个超参数来调整这一项对损失函数的贡献,通常取0.1。
当完成训练后,object pyramid 分支会被去掉,而只留下原始的 Faster Rcnn 来完成推理。
Experiments
基类训练后得到预训练模型,之后再用小样本学习的方法来微调。最后的分类层替换,随机初始化,微调时不冻结网络的参数。Baseline 为 Faster Rcnn,Baseline-FPN 为 Faster Rcnn + FPN。
在 PASCAL VOC 上的结果:


MS COCO:

值得注意的是当跨域迁移时,MPSR 也取得了不错的效果。将 COCO 作为基类训练的模型,在 VOC 上进行 10-shot 微调后,上表所述模型的精度分别为:32.3%、37.4%、38.5%、39.3% 和 42.3%。
当尺度差别特别大时,比如将 Bus 和 Cow 两种类别中数据的尺度限制到 128*128 和 256*256(图中的 Limited)时,检验模型的精度:

同时对比了几种主流的应对多尺度问题的 Neck:

SNIPER 值得注意。对 MPSR 中的模块进行了消融实验:

Conclusions
看到的第一篇针对小样本检测中的多尺度问题,不同的尺度空间可能会导致模型精度的下降,感觉可以用来检测小目标物体。
附加
- FPN 中的 anchor matching,参考了 RPN(区域生成网络) - 珠峰上吹泡泡 - 博客园
一般认为 anchor matching 是在 RPN 中,RPN 的过程如下:
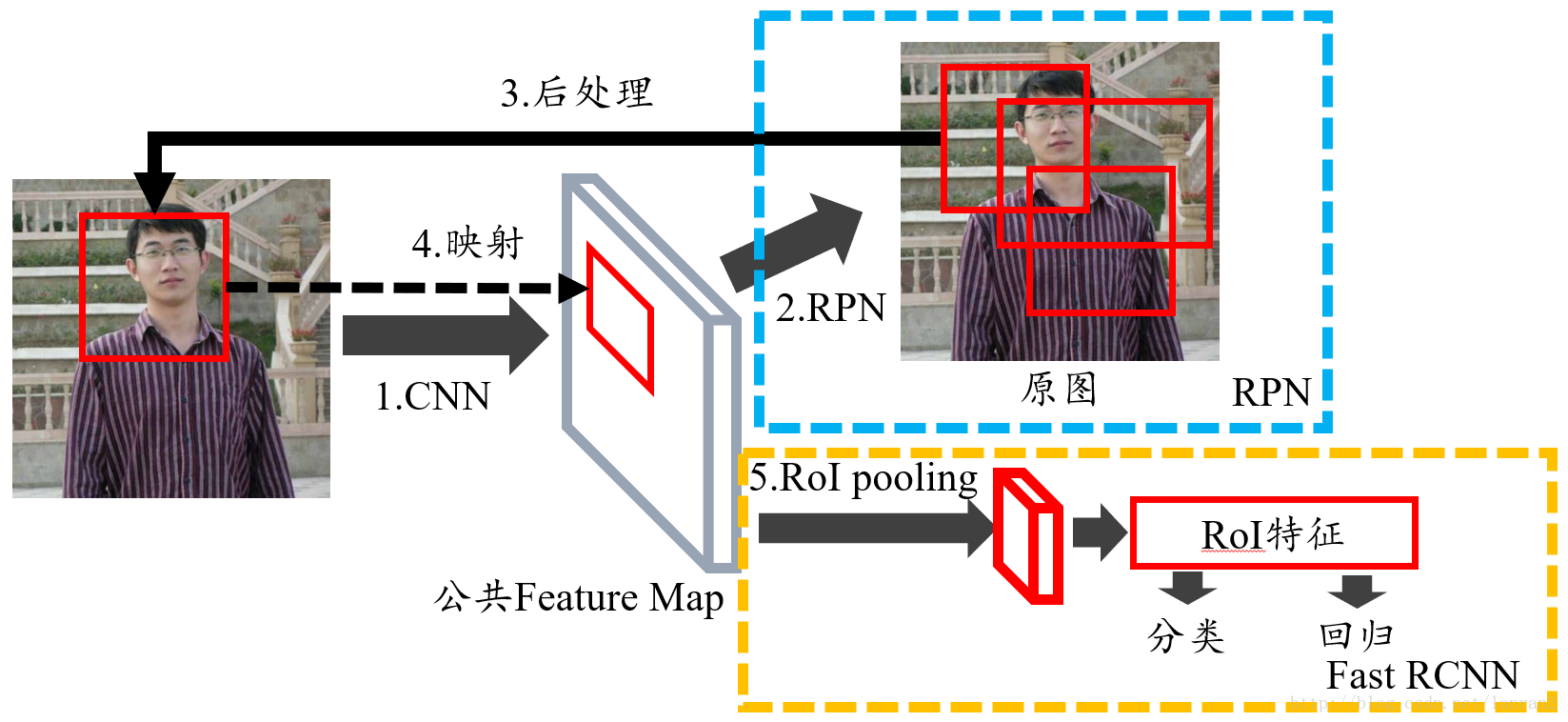
对于特征图上的每一点映射回原图,是一个(原图/特征图)固定比例的检测框,但这个框不是我们想要的。取这个框左上角的点作为 anchor,施加 K 个 anchor boxes,对 anchor boxes 与 ground truth 的 IoU 值超过阈值的 anchor boxes 做边框修正,即 matching:
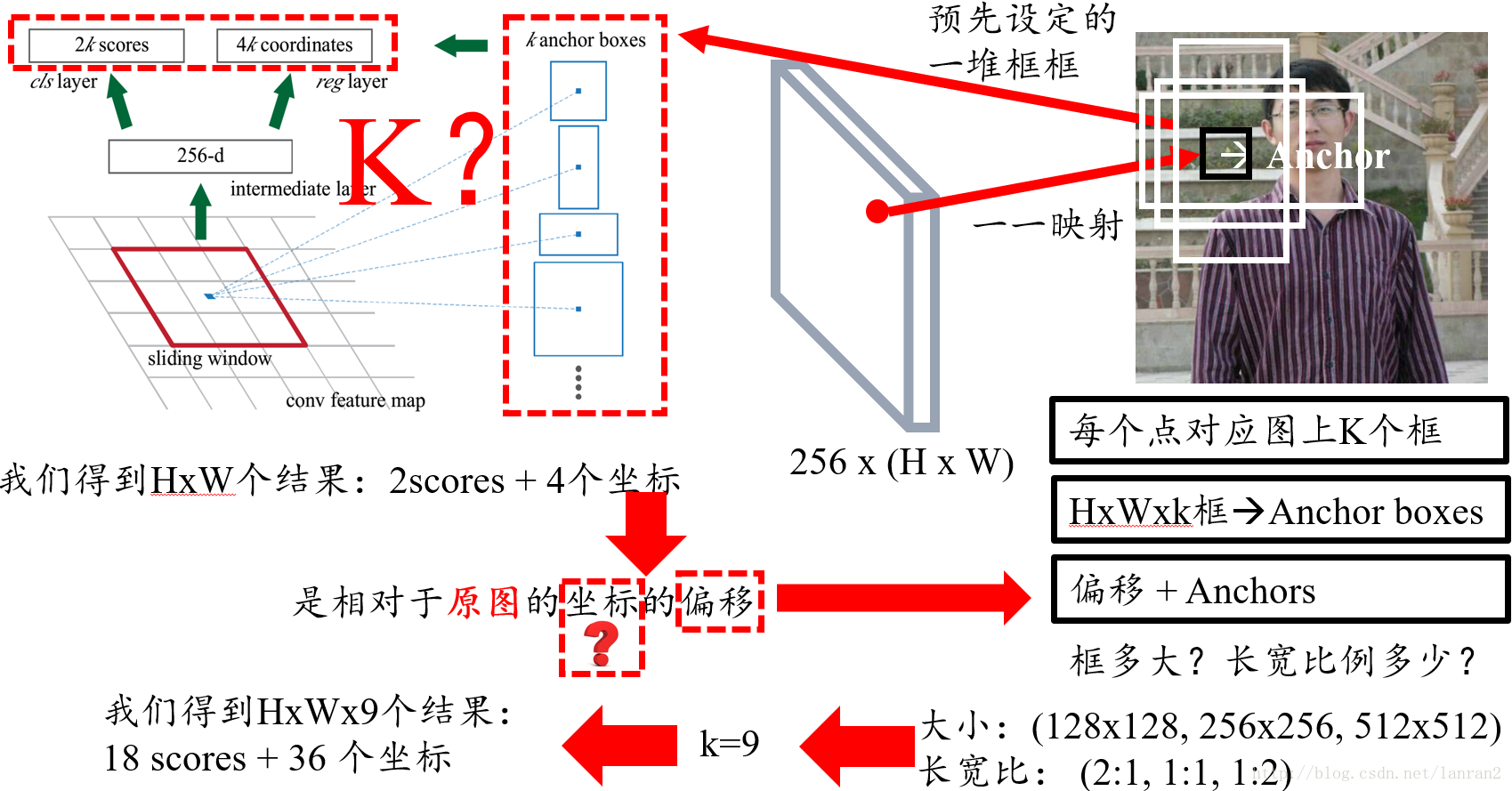
而之所以说 FPN 的 anchor matching 是因为 FPN 每一个升采样层都会施加 RPN 网络,这些 RPN 网络中包含了 anchor matching。 FPN 的网络结构大致如下:

- Faster Rcnn 中 NMS 的作用
第一个作用是将 Anchor 标记为 positive/foreground 和 negative/background,第二个作用是用阈值对 proposal 进行过滤。
- Faster Rcnn 中的两个阶段的 NMS
21.12.30
最新理解,这一段的表述有点错误。
这里第一阶段的两次和第二阶段第一次使用 IoU 阈值来过滤 proposal 不能算是 NMS 操作,只能说是用阈值卡掉了一定的 proposal,真正使用 NMS 是在 Fast Rcnn 中,完成了对检测结果的调整并输出。
第一阶段的 NMS 在 RPN 中,RPN 中的分类是二分类(包含/不包含物体)。用 cfg.RPN_NMS_IOU_THRESHOLD 作为阈值的 NMS 对前景 proposal(用 RPN 产生的回归预测 rpn_box_pred 对 Anchor 进行调整,即找到 rpn_box_pred 与 Anchor 算出的修正框,成为 proposal)过滤,留下2000个阈值最高的送入第二阶段(Fast Rcnn)。再用 cfg.RPN_IOU_NEGATIVE_THRESHOLD 和 cfg.RPN_IOU_POSITIVE_THRESHOLD 选出 positive 和 negative 的 anchor 各128个,用这些 [ Anchor 的类别和 gt 与 Anchor 算出的修正框 ] 来与 RPN 输出的预测分类得分和回归框 [ fpn_cls_score,rpn_box_pred ] 计算 RPN 的损失函数。
Anchor 的类别:将特征图上产生的 Anchor 与 gt 进行 NMS,大于0.7以及与每个 gt 的 IoU 值最大的 Anchor 为前景,小于0.3的为背景,0.3~0.7之间的舍弃。
128个的选法:从标记为前景的 Anchor 中随机抽取128个(原论文中拿来训练的有256个 proposal,其中前景128个背景128个),标记为背景的 Anchor 中随机抽取128个。
第二阶段的 NMS 发生在 Fast Rcnn 中,cls Head 是多分类(对应数据集中物体的类别)。对上一阶段送来的2000个 proposal 计算与 gt 的 IoU 值,大于 cfg.FAST_RCNN_IOU_POSITIVE_THRESHOLD 的 proposal 为 foreground,0.1~cfg.FAST_RCNN_IOU_POSITIVE_THRESHOLD 之间的为 background(第一次 NMS),同时保证每个 batch 中 foreground proposal 与 background proposal 的比值为1:3。用这一阶段第一次 NMS 标记为的 foreground/background 的 [ gt 的类别和这些 proposal 与 gt 的修正框 ] 与第二阶段 Fast Rcnn 的 [ 分类预测 cls_score,回归预测 bbox_pred ] 送入损失函数计算 Fast Rcnn 的损失。总的损失函数在这一阶段第二次 NMS 之前计算,再算出这些 Fast Rcnn 的回归预测 bbox_pred 与 proposal 的修正框即为检测的输出。分别对每个类别的修正框并用阈值为 cfgs.FAST_RCNN_NMS_IOU_THRESHOLD 的 NMS(第二次 NMS,神经网络——IoU & NMS_AmbitionalH的博客-CSDN博客)对每个 proposal 进行过滤,每个类别最多 cfgs.FAST_RCNN_NMS_MAX_BOXES_PER_CLASS 个,proposal 之间 pk 的过程发生第二次 NMS。
- NMS 的过程
非极大值抑制(Non-Maximum Suppression,NMS) - 康行天下 - 博客园
- 这篇文章的框架细节还没懂,需要结合 FPN 论文。















 1945
1945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









