







❤️ 专栏简介 :网络通信和Socket编程是Linux C/C++服务器开发的基础。本专栏从最基础的内容开始学习网络通信和socket编程的相关内容,循序渐进的掌握网络通信的和socket编程的相关知识。主要内容包括网络通信与socket编程概述、socket通信模型、套接字概述、socket通信交互流程以及Socket通信中各个函数的实现以及功能等。
☀️ 专栏适用人群 :适用于具备基础 Linux 知识的并想从零开始学习网络通信和Socket编程初学者;以及想学习Linux上c/c++服务器开发的朋友们。
🌙专栏特点:通俗易懂、图文并茂、非常详细;
🌴 专栏说明 :如果文章知识点有错误的地方,欢迎大家随时在文章下面评论,我会第一时间改正。让我们一起学习,一起进步。
🍄 专栏地址:https://blog.csdn.net/anchenliang_1002/category_11919076.html
本节我们来详细的对socket进行学习,主要包括套接字概念、socket通信流程、socket编程基础、网络字节序、sockaddr地址结构、IP地址转换函数等。
文章目录
一、套接字概念
1.1 套接字概念
Socket中文意思是“插座”,在Linux环境下,用于表示进程间网络通信的特殊文件类型。本质为内核借助缓冲区形成的伪文件。
在之前的服务端和客户端实战的代码中,我们声明一个socket都是用int类型声明的;因为socket的返回值是int,就跟操作文件的函数比如open等是一样的,其句柄都是int类型。
既然是文件,那么理所当然的,我们可以使用文件描述符引用套接字。Linux系统将其封装成文件的目的是为了统一接口,使得读写套接字和读写文件的操作一致。区别是文件主要应用于本地持久化数据的读写,而套接字多应用于网络进程间数据的传递。
在TCP/IP协议中,“IP地址+TCP或UDP端口号”唯一标识网络通讯中的一个进程。“IP地址+端口号”就对应一个socket。欲建立连接的两个进程各自有一个socket来标识,那么这两个socket组成的socket pair就唯一标识一个连接。因此可以用Socket来描述网络连接的一对一关系。
套接字通信原理如下图所示:
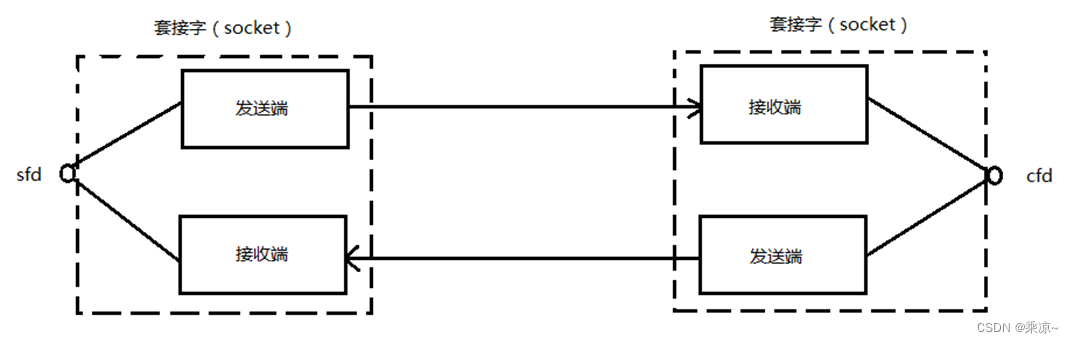
左边是客户端,右边是服务端,在网络通信中,套接字一定是成对出现的。一端的发送缓冲区对应对端的接收缓冲区。我们使用同一个文件描述符索发送缓冲区和接收缓冲区。
1.2 socket通信创建流程
socket通信中,客户端和服务端的整体流程如下图所示:
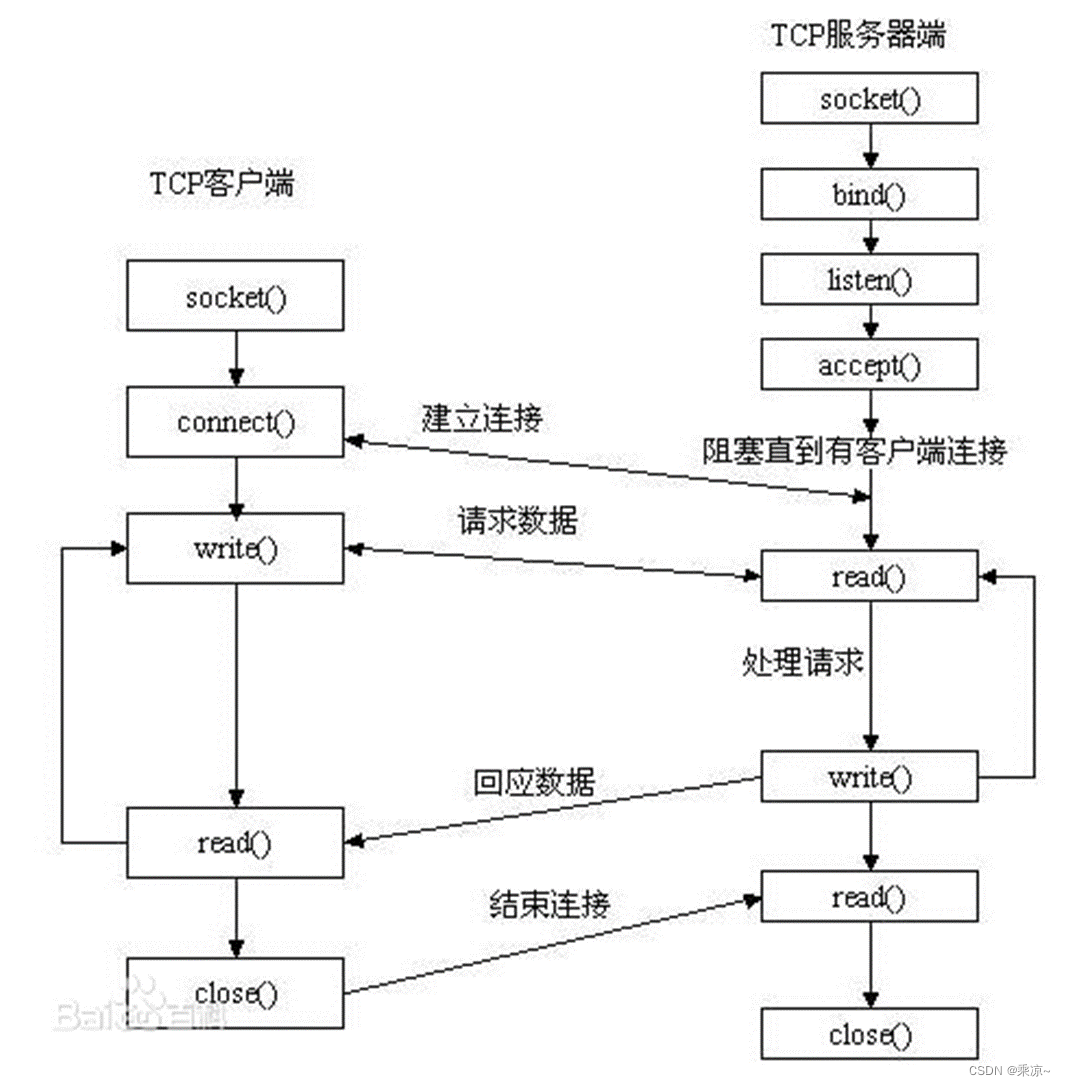
结合我们之前写的客户端和服务端的代码回顾一些:
客户端比较简单,需要先创建一个socket套接字,指明要请求的目标ip和端口号,然后利用connect()进行建立连接请求(可以理解为打电话过程中的“拨打”功能),建立连接后,就可以循环的进行读写信息了(类似于电话接通之后的沟通过程);最后,调用close关闭socket连接(类似于打电话过程中的挂断功能);其实是TCP通信过程中四次挥手的过程。
服务端就稍微复杂一些了,首先需要创建一个套接字,然后使用bind()函数将自己的ip和端口与刚刚创建的socket进行绑定,之后利用listen()对socket进行监听,因为服务器需要接受多个客户端的连接;如果有请求进来,使用accept()进行连接的建立(类似于打电话中的“接听”功能),建立连接之后就可以进行通信了,可以互相进行读写,比如收消息和发消息;最后最后,调用close关闭socket连接(类似于打电话过程中的挂断功能);其实是TCP通信过程中四次挥手的过程。
二、socket编程基础
2.1 网络字节序(htonl、htons、ntohl、ntohs函数)
在前面写服务端的代码中,指定服务端ip的时候,代码如下:
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
可以看到我们使用htonl对ip进行了转换,那为什么要进行转换呢?直接使用ip会有什么问题吗?这就是我们这小节要学习的内容:网络字节序。
什么是网络字节序?可以用我们写字的顺序作为例子,比如我们现在是从左往右写,而古代是从右往左写;如果有一句古代的字,要想读懂它的意思应该从右往左读,但我们偏偏从左往右读,那么最终得出的这句话的意思大概率是错的。
同样的,在计算机世界里,或者说在不同的系统里,有两种字节序:
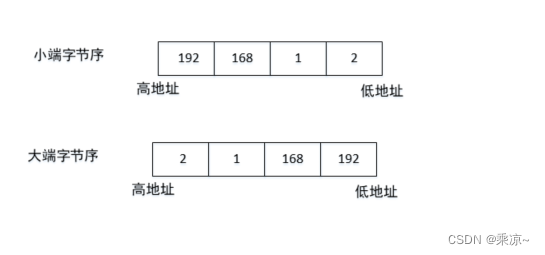
- 大端字节序: 低地址高字节,高地址低字节
- 小端字节序: 低地址低字节,高地址高字节
我们现在最常用的其实是小端字节序,何为小端字节序?如下图所示:
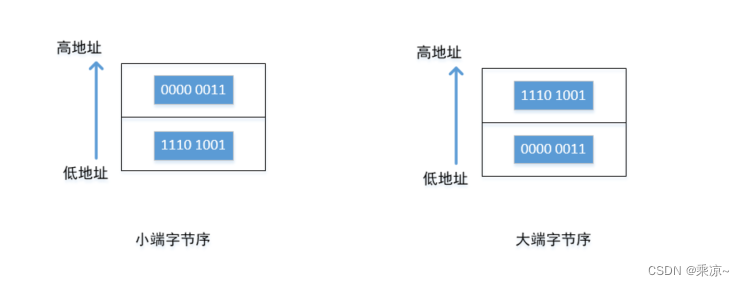
比如现在有一个数字,十进制为1001,对应的十六进制为0x03e9,对应的二进制为0000 0011 1110 1001,共十六位,我们每个字节是8位,其中0000 0011为高8位,1110 1001为低8位;如左图中,将低八位1110 1001放在低地址,将高八位0000 0011放在高地址,这就是小端字节序;反之,右图中,将高八位0000 0011放在低地址,低八位1110 1001放在高地址,这就是大端字节序;所以,如果内存中有一个数字0000 0011 1110 1001,他存放的顺序是固定的,即以小端字节序的方式存放,如果我们用小端的方式去取,则取出来的就是0000 0011 1110 1001,是正确的;但是如果我们按照大端的方式去取,则取出来的就是1110 1001 0000 0011,是错误的。
我们网络中发送数据的时候,也是先发低地址的数据,再发高地址的数据;即从低地址往高地址依次往外发的。
在计算机中,内存中的多字节数据相对于内存地址有大端和小端之分,磁盘文件中的多字节数据相对于文件中的偏移地址也有大端小端之分。网络数据流同样有大端小端之分,那么如何定义网络数据流的地址呢?发送主机通常将发送缓冲区中的数据按内存地址从低到高的顺序发出,接收主机把从网络上接到的字节依次保存在接收缓冲区中,也是按内存地址从低到高的顺序保存,因此,网络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是高地址。
TCP/IP协议规定,网络数据流应采用大端字节序,即低地址高字节。
例如端口号是1001(0x3e9),由两个字节保存,采用大端字节序,则低地址是0x03,高地址是0xe9,也就是先发0x03,再发0xe9,这16位在发送主机的缓冲区中也应该是低地址存0x03,高地址存0xe9。但是,如果发送主机是小端字节序的,这16位被解释成0xe903,而不是1001。因此,发送主机把1001填到发送缓冲区之前需要做字节序的转换。同样地,接收主机如果是小端字节序的,接到16位的源端口号也要做字节序的转换。如果主机是大端字节序的,发送和接收都不需要做转换。同理,32位的IP地址也要考虑网络字节序和主机字节序的问题。
举个例子,如果我们设置的ip是192.168.1.2;是按照大端的方式发送的,如果对方按照小端的方式进行解析,则对方得到的结果就是2.1.168.192;对方会以为我们发送的ip是2.1.168.192,完全弄错了;所以对方必须也得按照大端的方式进行解析,才能正确的解析到ip。
为使网络程序具有可移植性,使同样的C代码在大端和小端计算机上编译后都能正常运行,可以调用以下库函数做网络字节序和主机字节序的转换。
#include <arpa/inet.h>
uint32_t htonl(uint32_t hostlong);
uint16_t htons(uint16_t hostshort);
uint32_t ntohl(uint32_t netlong);
uint16_t ntohs(uint16_t netshort);
h表示host,n表示network,l表示32位长整数,s表示16位短整数。
如果主机是小端字节序,这些函数将参数做相应的大小端转换然后返回,如果主机是大端字节序,这些函数不做转换,将参数原封不动地返回。
我们在服务端的代码中,在设置ip的时候用到了htonl,在设置端口的时候用到了htons;即把host主机字节序转换成network网络字节序。
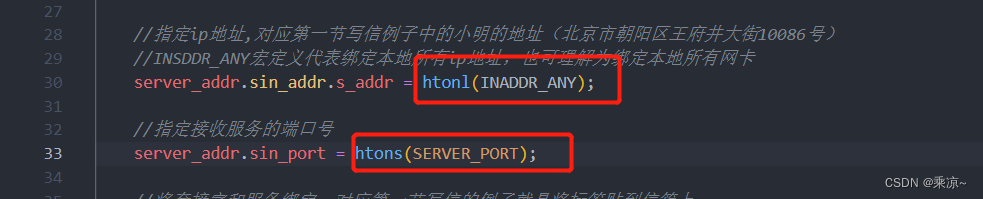
在客户端的代码中,在设置端口的时候用到了htons;即把host主机字节序转换成network网络字节序。

在服务端的代码中,在打印客户端ip和端口号时,使用了htons,即将网络字节序转换成主机字节序。

2.2 sockaddr地址结构
在服务端和客户端的代码中,我们用sockaddr来存放ip地址、端口等信息;如下
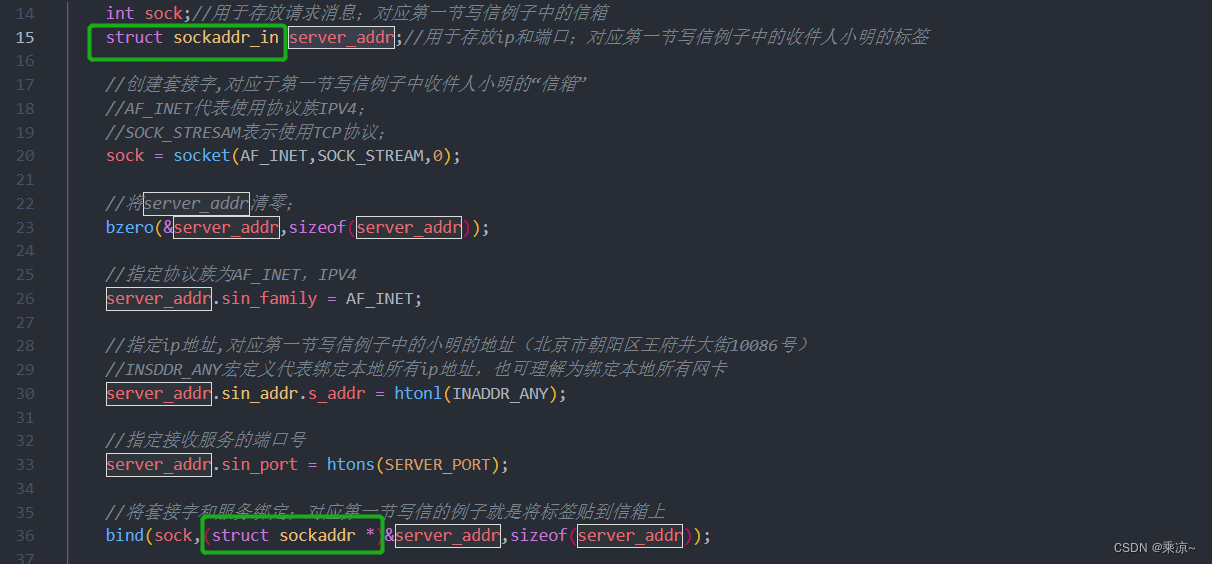
那这个sockaddr内部结构到底是怎样的?为什么赋值时使用的是sockaddrt_in,使用时要将其强转成sockaddr呢?下面我们就来详细看一下;
sockaddr与sockaddr_in
很多网络编程函数诞生早于IPv4协议,那时候都使用的是sockaddr结构体,为了向前兼容,现在sockaddr退化成了(void *)的作用,传递一个地址给函数,至于这个函数是sockaddr_in还是其他的,由地址族确定,然后函数内部再强制类型转化为所需的地址类型。
结构图如下所示:
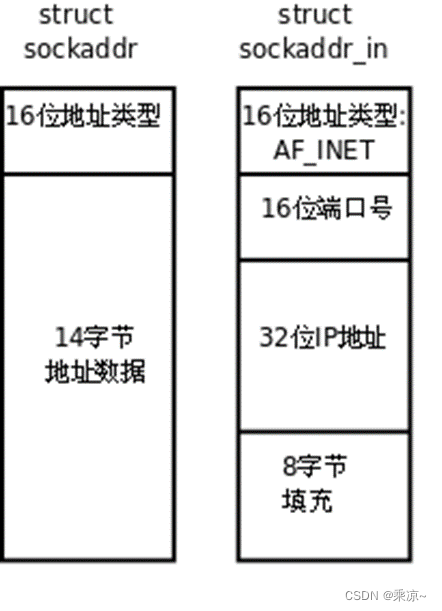
结构体定义如下所示:
#include <netinet/in.h> //头文件
struct sockaddr //早期的sockaddr
{
sa_family_t sa_family; /* adress family: AF_XXX */
char sa_data[14];/* 14 bytes of protocol */
};
struct sockaddr_in //IPv4的sockaddr
{
uint8_t sin_len; /* length of structure (16字节) */
sa_family_t sin_family; /* AF_INET */
in_port_t sin_port; /* 16-bit TCP or UDP port number; 网络字节序 */
struct in_addr sin_addr; /* 32-bit IPv4 address; 网络字节序 */
char sin_zero[8];/* unused */
};
struct in_addr //IPv4地址
{
in_addr_t s_addr; /* 32-bit IPv4 address; 网络字节序 */
};
//由于sock API的实现早于ANSI C标准化,那时还没有void*类型,因此像bind、accept函数
//的参数都用struct sockaddr* 类型表示, 在传递参数之前要强制转换一下,
如:
struct sockaddr_in servaddr;
bind(listen_fd, (struct sockaddr*)&servaddr, sizeof(servaddr));
sin_family指代协议族,可以是AF_INET,代表IPV4;AF_INET6代表IPV6协议。
sin_port存储端口号(使用网络字节顺序)
sin_addr存储IP地址,使用in_addr这个数据结构
sin_zero是为了让sockaddr与sockaddr_in两个数据结构保持大小相同而保留的空字节。
s_addr按照网络字节顺序存储IP地址
sockaddr_in和sockaddr是并列的结构,指向sockaddr_in的结构体的指针也可以指向sockadd的结构体,并代替它。也就是说,我们可以使用sockaddr_in建立我们所需要的信息,在最后用进行类型转换就可以了
我们只要记住,填值的时候使用sockaddr_in结构,而作为函数的参数传入的时候转换成sockaddr结构就行了,毕竟都是16个字符长。
2.3 IP地址转换函数(inet_pton和inet_ntop函数)
IP地址转换函数用以实现以下功能:
如,将字符串类型的ip地址转换成网络字节序(整数类型)的ip地址;或者将整数的网络字节序地址转换成字符串类型的IP地址。
地址转换函数主要有inet_pton和inet_ntop,他们的定义如下所示:
#include <arpa/inet.h>
int inet_pton(int af, const char *src, void *dst);//字符串ip转换成网络字节序ip
const char *inet_ntop(int af, const void *src, char *dst, socklen_t size);//网络字节序ip转换成字符串ip
inet_pton负责将字符串ip转换成网络字节序ip;入参是af和src;af 取值可选为 AF_INET 和 AF_INET6 ,即和 ipv4 和ipv6对应
支持IPv4和IPv6;src字符串指针表示我们要转换的字符串ip;转换以后的值(网络字节序IP地址)保存在dst指针指向的地址中。
inet_ntop负责将网络字节序ip转换成字符串IP地址;af 取值可选为 AF_INET 和 AF_INET6 ,即和 ipv4 和ipv6对应
支持IPv4和IPv6;src字符串指针表示我们要转换的网络字节序IP地址;转换以后的值(字符串IP地址)保存在dst指针指向的地址中。
一般情况下我们写IP地址时经常这么写:“192.168.1.1”,这是字符串类型的IP地址,但是在网络编程需要使用网络字节序(即整数类型)的IP地址;在网络中IP地址的是怎么保存的呢?如果是小端字节序,则如下所示。
我们用几个例子来演示ip地址的转换,首先是inet_pton函数的示例:
例1:将字符串IP地址转换成网络字节序IP地址
#include <stdio.h>
#include <string.h>
#include <arpa/inet.h>
int main(void)
{
char ip[]="192.168.1.2";
struct sockaddr_in server_addr;
inet_pton(AF_INET, ip, &server_addr.sin_addr.s_addr);
printf("s_addr : %x\n", server_addr.sin_addr.s_addr);
return 0;
}
代码解释:
在第8行我们定义了一个IP地址,即192.168.1.2;很明显它是字符串类型的IP地址;
第10行我们定义了一个sockaddr_in类型的结构体:server_addr,用于存放字符串IP地址转换后的网络字节序IP地址;
第12行我们使用inet_pton函数将字符串IP地址转换成网络字节序IP地址,存放在server_addr.sin_addr.s_addr中;
第14行我们将网络字节序IP地址用十六进制打印出来。因为TCP/IP协议规定,网络数据流应采用大端字节序,所以我们打印出来的地址正常来讲应该是大端字节序的情况,对应上图中大端字节序的情况。
第16行我们使用ntohl函数将网络字节序IP地址转换成本机地址,即从大端字节序转换成小端字节序打印出来看一下。
运行结果如下:

第一个打印,就是说我们的字符串IP地址192.168.1.2转换成网络字节序的IP地址后是201a8c0,每两位占一个字节,大端字节序是低地址保存高位,即右边是低位,左边是高位,即02 01 a8 c0,每个字节转换成十进制就是2 1 168 192,因为TCP/IP协议规定,网络数据流应采用大端字节序,所以可以看到打印出来的IP地址确实是大端字节序的形式。
第二个打印,可以看到从网络字节序转换成主机地址后,即从大端字节序转换成小端字节序后的结果是c0a80102,小端字节序是低地址保存低位,左边是低位,右边是高位,即c0 a8 01 02,每一位均转换成是十进制后就是192.168.1.2。
例2:将网络字节序IP地址转换成字符串IP地址
#include <stdio.h>
#include <string.h>
#include <arpa/inet.h>
int main(void)
{
char ip[]="192.168.1.2";
struct sockaddr_in server_addr;
inet_pton(AF_INET, ip, &server_addr.sin_addr.s_addr);
printf("s_addr : %x\n", server_addr.sin_addr.s_addr);
char server_ip[64];
inet_ntop(AF_INET, &server_addr.sin_addr.s_addr, server_ip, 64);
printf("server ip : %s\n", server_ip);
return 0;
}
第16行我们先定义一个字符数组来存放从网络字节序IP地址转化后的字符串IP地址;
第18行调用inet_ntop函数将网络字节序IP地址转换成字符串IP地址;
第20行打印从网络字节序IP地址转化后的字符串IP地址。
结果如下:

可以看到,转换成字符串IP地址后还是192.168.1.2。
















 8148
8148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











