







数据:https://www.csie.ntu.edu.tw/~htlin/course/ml15fall/hw1/hw1_15_train.dat
总共含有400条数据,其中前四个为特征,最后的是label,类别有两类,+1和-1.
对这样特征思维,类别两类的分类问题,并且我们已知这些数据是线性可分的,我们采用PLA来进行分类。
算法很简单:

来源台大林轩田的机器学习基石
1. 顺序调整
matlab实现:
load 'hw1_15_train.txt'
w = [0,0,0,0,0];
x0 = 1;
times = 0;
train_x = ones(400,1);
train_x = [train_x,hw1_15_train(:,1:4)];
train_y = hw1_15_train(:,5);
for i = 1:400
dotvalue = dot(w,train_x(i,:));
if(sign(dotvalue)~=train_y(i))
w = w + train_x(i,:)*train_y(i);
fprintf('%d %s\n',i,'makes mistake.');
times = times + 1;
end
end
最开始的权重初始化为0,并且0的符号设置为-1,x0=1.
总共迭代37次, 按顺序最后一次调整是在第234个数据。2.如果安装乱序,并且做2000次,统计迭代次数
matlab实现:
load 'hw1_15_train.txt'
w = [0,0,0,0,0];
x0 = 1;
times = 0;
train_x = ones(400,1);
train_x = [train_x,hw1_15_train(:,1:4)];
train_y = hw1_15_train(:,5);
alltimes = [];
for k = 1:2000
times = 0;
w = [0,0,0,0,0];
id = randperm(400);
rtrain_x = train_x(id,:);
rtrain_y = train_y(id);
for i = 1:400
dotvalue = dot(w,rtrain_x(i,:));
if(sign(dotvalue)~=rtrain_y(i))
w = w + rtrain_x(i,:)*rtrain_y(i);
fprintf('%d %s\n',i,'makes mistake.');
times = times + 1;
end
end
alltimes = [alltimes,times];
end
%tabulate(alltimes) 统计出现的频次和频率
hist(alltimes,unique(alltimes)); %直方图
统计直方图:
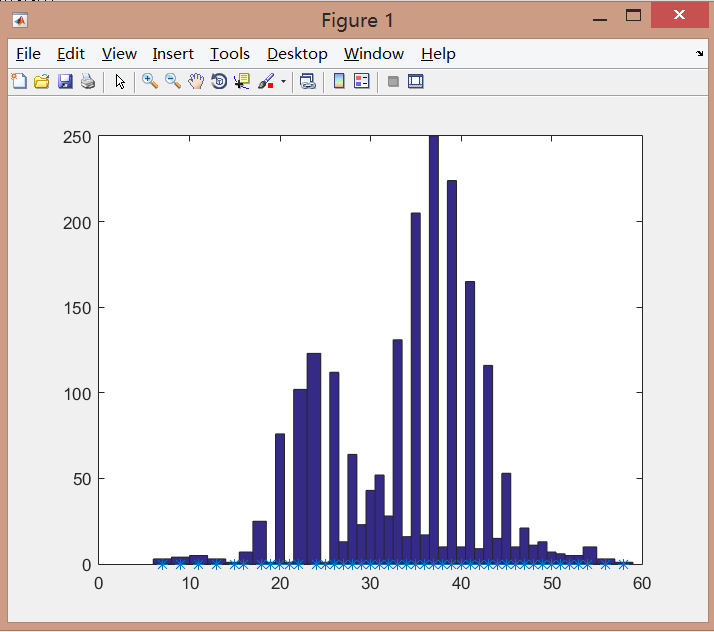
最好的情况是迭代次数只需要7次,最差的情况是58次迭代,平均迭代次数为34.09,由此可以看出数据的顺序对PLA算法具有很强烈的影响。
3. 调整权重更新公式

之前相当于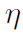
直接上结果,
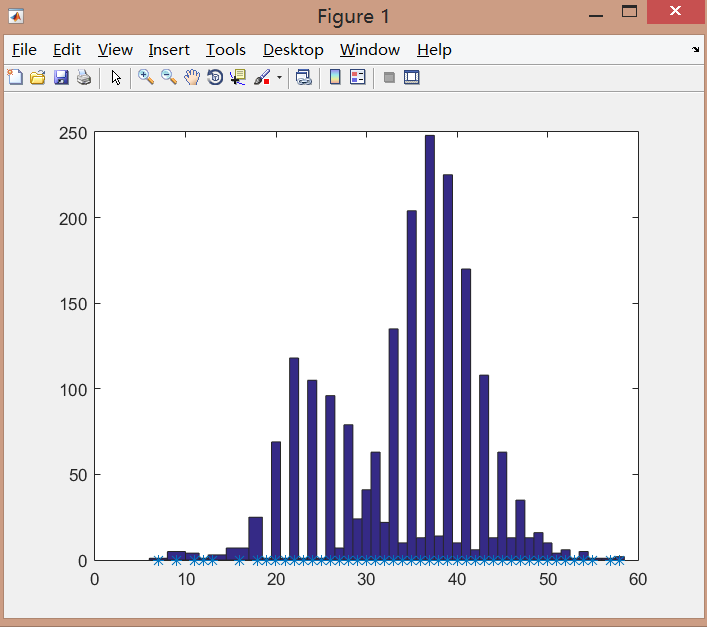
最小迭代次数是7,最大迭代次数是58,平均值是34.10,跟调整前的结果差别并不是很大。
最开始我们说了,我们已知数据是线性可分的,但是并不是所有的数据都有这么好的特性,那线性不可分的情况下,我们能够怎么利用PLA感知器算法,就是设置一个最大的迭代次数,然后保存最好的权重,这也被称为pocket algorithm,即口袋算法。
算法流程:

现在换一批数据,
训练数据:
https://www.csie.ntu.edu.tw/~htlin/course/ml15fall/hw1/hw1_18_train.dat
测试数据:
https://www.csie.ntu.edu.tw/~htlin/course/ml15fall/hw1/hw1_18_test.dat
先用训练数据训练PLA,每次调整权重时都用测试数据测试预测准确率,如果超过之前的准确率则保存这个权重为最好权重,也就是把这个权重放到口袋里。直到达到迭代次数达到50次,停止迭代。重复做2000次。
matlab实现:
load 'hw1_18_train.txt'
load 'hw1_18_test.txt'
w = [0,0,0,0,0];
x0 = 1;
times = 0;
one = ones(500,1);
train_x = [one,hw1_18_train(:,1:4)];
train_y = hw1_18_train(:,5);
test_x = [one,hw1_18_test(:,1:4)];
test_y = hw1_18_test(:,5);
alltimes = [];
allAcc = [];
bestacc = 0;
bestw = [];
for k = 1:2000
times = 0;
w = [0,0,0,0,0];
id = randperm(500);
rtrain_x = train_x(id,:);
rtrain_y = train_y(id);
for i = 1:500
dotvalue = dot(w,rtrain_x(i,:));
if(sign(dotvalue)~=rtrain_y(i))
w = w + rtrain_x(i,:)*rtrain_y(i);
fprintf('%d %s\n',i,'makes mistake.');
times = times + 1;
end
predict_y = sign(w*test_x');
acc = sum(predict_y==test_y')/size(test_y,1);
if(acc>bestacc)
bestw = w;
bestacc = acc;
end
if(times>50)
break;
end
end
allAcc = [allAcc,bestacc];
end
%tabulate(alltimes) %统计出现的频次和频率
hist(allAcc,unique(allAcc)); %直方图
结果:
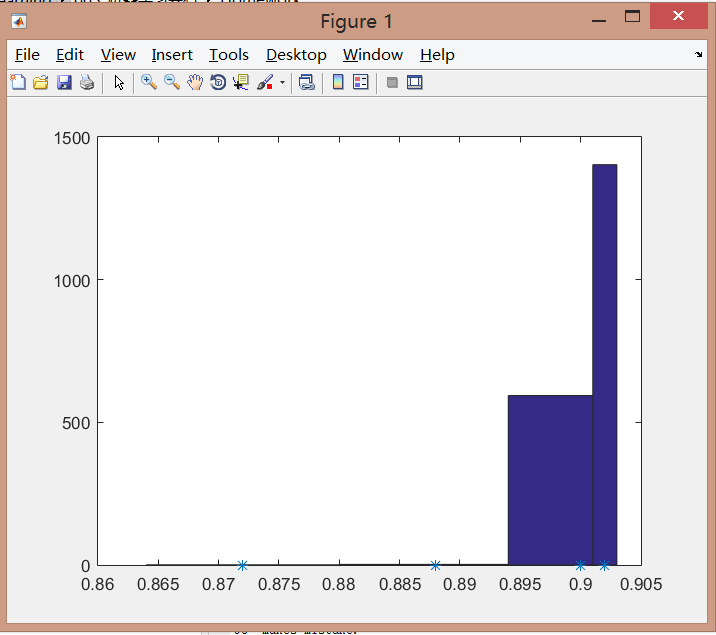
可以看到,准确率基本都有90%,如果不保存最好的权重,任由其调整,甚至会出现20%的准确率,因此这个算法在某种程度上保证了较好的识别率。
如果我们增加迭代次数,比说说改为100,结果如下:

还是有提升的,毕竟增加了50次权重的可能性。
PLA算法是机器学习的入门级算法,但是通过这个例子能够对机器学习的整个流程有个大致的了解,通过这个例子希望给正在入门的童鞋一些帮助!















 2601
2601











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









