






前言
很早之前我们就聊过ToolFormer,Gorilla这类API调用的Agent范式,这一章我们针对真实世界中工具调用的以下几个问题,介绍微调(ToolLLM)和prompt(AnyTool)两种方案。
- 真实世界的API数量庞大且多样:之前的多数工具调用论文,工具数量有限,工具相对简单具体,并且往往局限在某一个领域例如模型调用
- 多工具调用:解决一个问题往往需要使用多个工具,需要通过多轮迭代实现
- 当API数量多且涉及多工具时,如何更有效的规划工具调用,并召回相关工具用于推理
ToolLLM
ToolLLM是清华一系列工具调用文章中的其中一篇,通过构建工具调用样本训练LLaMA并开源了评估集ToolBench。既然是微调方案,如何构建微调样本是核心,所以我们重点说下样本构建,和评估部分
训练
1.API Pool
ToolLLM使用了RapidAPI Hub提供的真实世界各类API,通过初步的调用测试过滤了类似高延时,404调不通之类的工具后,总共保留了3451个工具,包含16464个API。
RapidAPI的工具有category和collection两种分类体系,其中每个工具包含1个或多个API。例如yahoo finance工具属于金融分类,该工具下面有get_market_news, get_stock_quotes等众多API。这里的分类体系后面被用于多工具调用的指令样本构建的分层采样的依据。
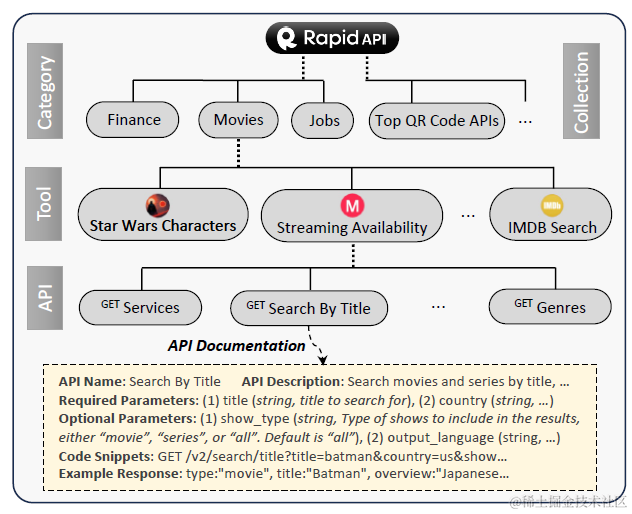
2.指令生成
为了保证指令样本的覆盖率和多样性,指令的构建会基于每个工具的所有API来进行,分成了单工具调用和多工具调用指令两部分。其中单工具就是遍历以上所有的Tool,每次使用一个工具的所有API,而多工具组合是每次采样同一个分类下2~5个工具,每个工具采样不超过3个API来构成, 这里论文分别使用上面RapidAPI的category分类,和collection分类作为分层采样的类别。单工具,category多工具,collection多工具分别对应了数据样例中的G1,G2,G3分类。
基于上面采样的API候选,指令构建使用Prompt让ChatGPT来同时生成相关的指令,以及该指令使用哪些API来完成,得到(Instruction,APIs)的样本对。prompt包含3个部分
- 任务描述:哈哈看到prompt的一刻我小脑都萎缩了怎么这么长…, 直接看吧

- few-shot: 这里论文人工构建了12个单工具,36个多工具的种子,每次随机采样3个,如下图

- API说明:包括API描述,参数描述,和codesnippet

针对生成的指令和APIs样本对,会进行简单的过滤,过滤生成的API列表出现输入API之外的幻觉样本。最终得到了200K的样本对
3.DFSDT答案生成
在构建多轮的工具调用回答时,论文在ReACT的基础上进行了改良,主要解决两个问题:Error Propogation, Limited Exploration。说白了就是ReACT是线性串联的,而论文借鉴了Tree of Thought,把线性改成了树形结构(DT),通过深度优先搜索(DFS),来提高正确路径生成的概率。整个遍历的过程如下图
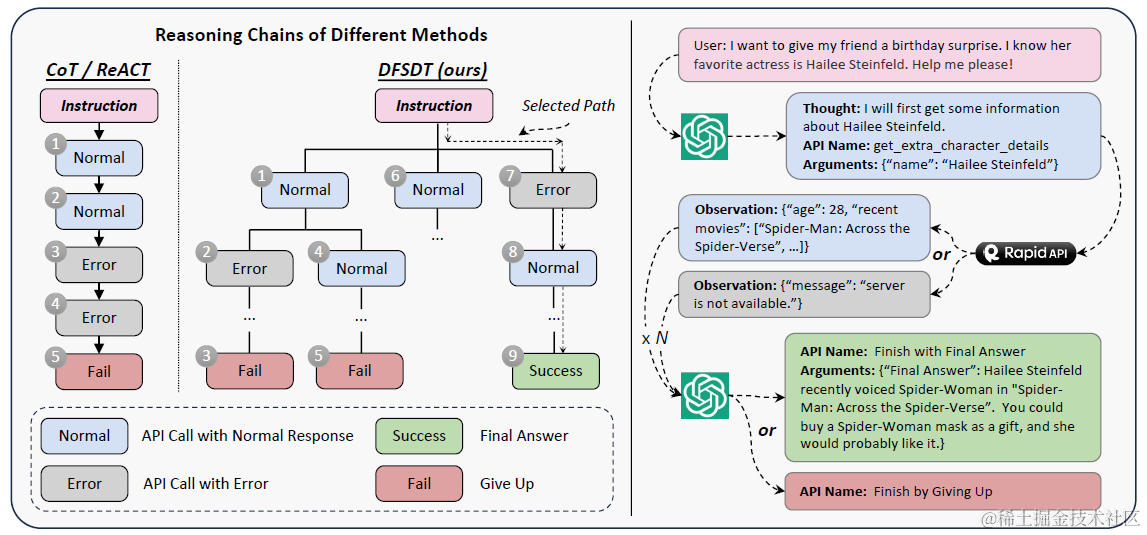
遍历的几个细节如下
- 构建顺序是DFS而非BFS,无他更经济实惠,如果第一条path走到Leaf Node就解决了,那其实就是ReACT。如果中间节点失败了,再回退到parent Node去生成新的child Node,也就是DFS的前序遍历。
- 以上判断一个Node是否失败或者是Leaf节点,论文增加了"Finish by Giving Up","Finish with Final Answer"两个API,前者DFS回退搜索,后者终止DFS。
- 在DFS过程中,为了增加子节点生成结果的多样性,论文采用了Diversity Prompt,会把之前Node生成的推理结果作为输入,让模型生成不一样的尝试步骤,prompt指令如下
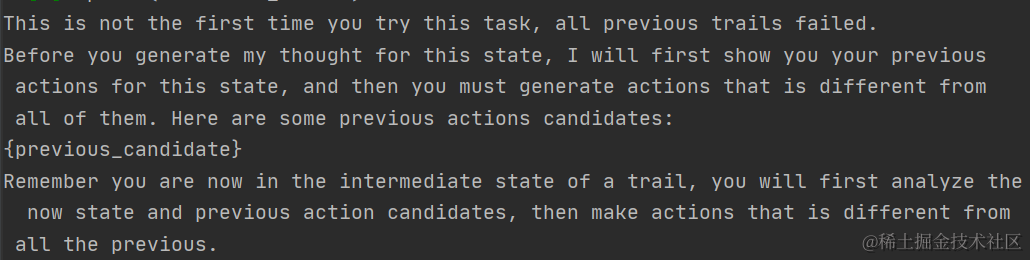
这一步最终只保留成功生成最终“Finish with Final Answer“的路径,总共得到了126,486个(指令,答案)样本对
4.微调
论文选择微调LLaMA-2 7B, 以上多轮工具调用,被构建成多轮对话的形式。训练超参:epoch=2, LR =5e-5, batch= 64, MAX_SEQ_LEN =8192, 这里考虑LLaMA是4096的长度论文使用了PI内插。
推理和评估
推理过程可说的不多,流程就是先使用API Retriever召回用户指令相关的多个工具,再进行一轮-多轮的工具调用路径生成。我们分别说下2个细节:API召回和评估。论文还使用了一些API返回内容压缩一类的技巧,不过这个感觉离专为大模型设计API返回的一天并不远,咱这里就不聊压缩了。
1. API Retriever
推理过程的第一步是如何根据用户的query召回可能用来回答的API候选。当然可以让用户自己选择工具(Oracle),但其实细想就会发现,要是得让用户自己从API海洋里面找自己想要的,那通用智能也就不通用了…
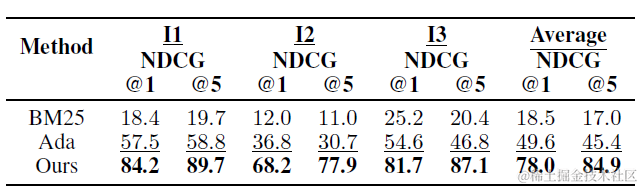
这里论文微调了Sentence-Bert,使用上面指令构建步骤得到的(query,APIs)作为正样本对,这里API使用API Document(包括API名称,描述,参数etc)来表征API,然后随机采样其他API作为负样本,进行对比学习。效果上,论文和BM25,OpenAI-Ada进行对比效果显著更好。
在很多垂直场景里,API Retriever这一步的重要性可能被低估,感觉给API生成更丰富全面的Description描述,来提升工具召回率是很有必要的。以及可以引入API相关工具,相关分类的其他信息,来进一步优化召回。
2. 评估
考虑整个工具调用路径的复杂程度,人工标注的成本极高。因此这里论文借鉴了AlpacaEval使用模型来进行评估,分别从以下两个角度进行评估。
- Pass Rate:评估单模型生成的回答路径是否回答指令问题
- Win Rate:评估两个模型生成的回答路径进行对比评估
以上评估均是使用ChatGPT3.5进行,取多次评估的平均值。具体指令详见toolbench/tooleval/evaluators/。论文对比了全机器的ToolEval和人工标注的一致性,一致率在80%左右。
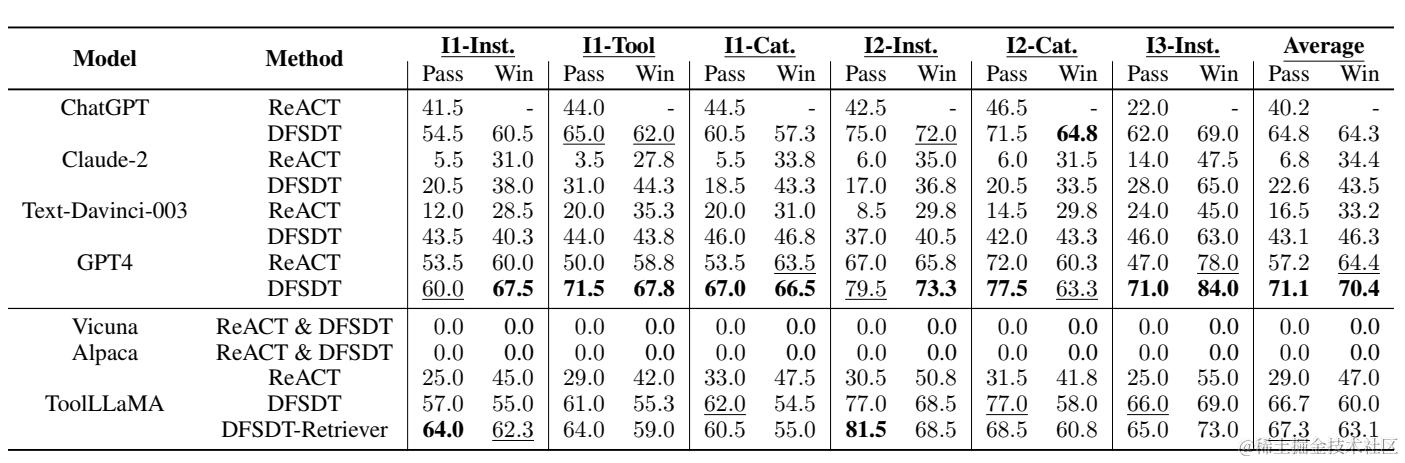
为了检验样本外泛化的效果,论文分别评估了样本外指令(Inst),相同分类样本外工具(Tool),不同分类样本外工具(Cat),整体上微调后的llama-7B基本能打平GPT4,并且DFSDT相比ReACT在L2,L3的复杂问题上有更明显的提升。
AnyTool
- AnyTool:Self-Reflective, Hierarchical Agents for Large-Scale API Calls
- https://github.com/dyabel/anytool
AnyTool在ToolLLM的基础上做了几点调整,这里只我们关注几个差异点。更多论文的细节,大家在有需要的时候再去看论文就好~
1. 分层召回
AnyTool更好的利用了RapidAPI的层次化结构进行API候选的召回。论文使用的是3类Agent交互的方案,分别是
- Meta Agent:就是基于用户Query,先联想相关的工具分类,并创建对应分类的Agent
- Category Agent:每个分类的Agent思考相关的工具,并初始化对应工具的Agent
- Tool Agent:每个工具的Agent召回相关的API,并合并进API候选池
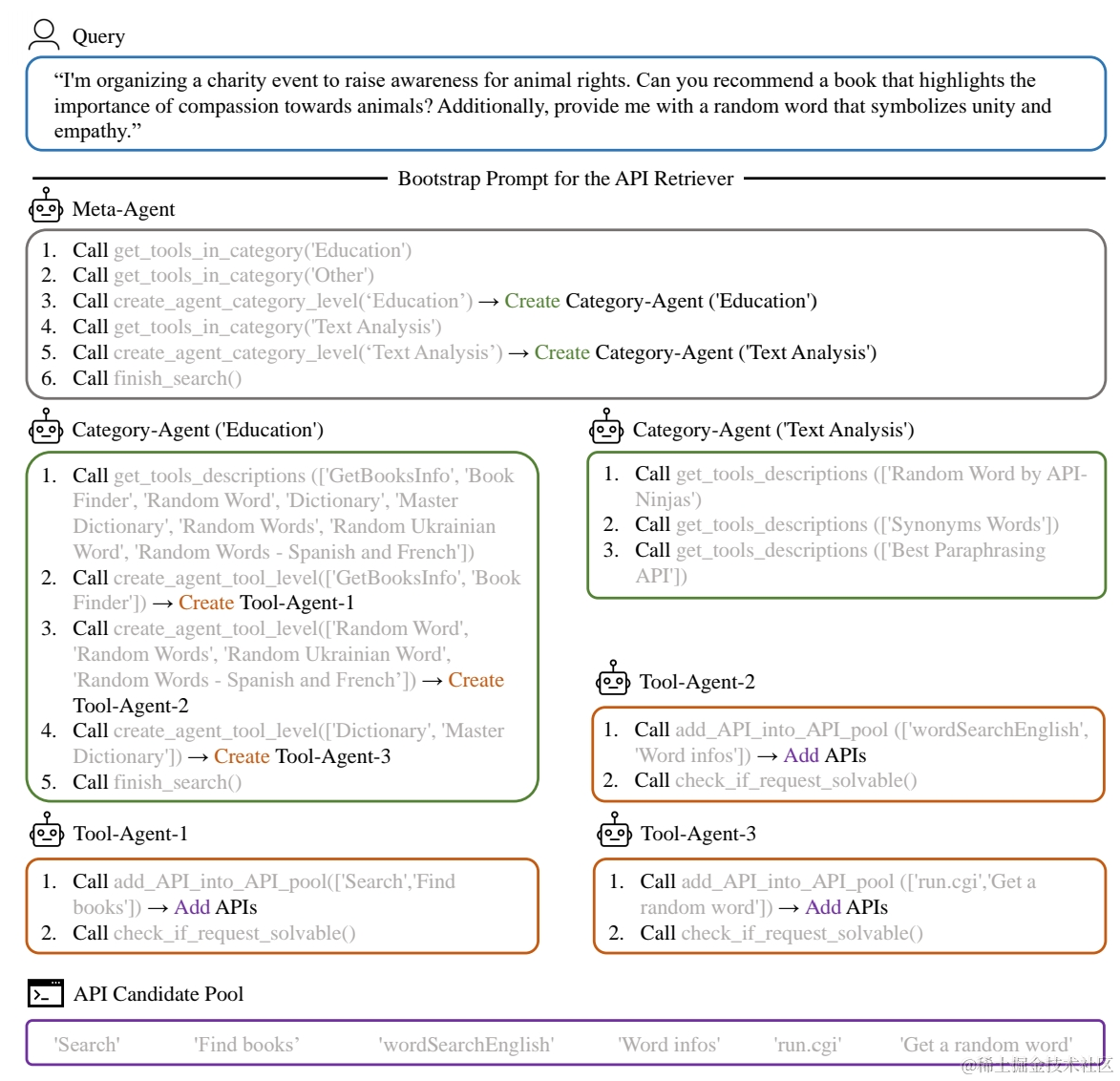
以上的3类Agent都是基于大模型Prompt实现,具体指令详见anytool/prompt_template。虽然大模型推理成本较高,但以上Divide-Conqure的方案,可以通过多层召回降低每一层的候选数量,并在同一层Agent推理进行并发,所以整体推理耗时相对可控。论文对比了把以上层次召回展平,以及Ada等Embedding的召回效果,整体上分层召回显著更优。不过这里其实有个前提,就是你的API全集要足够大,才需要考虑这种方案。

2. Self-Reflection
当一轮推理结束,如果模型给出了“Give UP”的结果,则使用模型自己的放弃理由作为Context触发反思模块;如果模型给出了结果,但GPT4判断结果错误,则使用GPT4的理由作为Context。反思涉及到API召回模块和规划推理模块。
API召回部分会分别使用以上Context,和下面的指令,按从底层到顶层的顺序重新激活上一轮使用的Tool,Category,Meta Agent,目标就是进一步扩展更多的API候选,来进行重新推理。

推理部分,如果模型上一轮给出了“Give UP”的结果,会先剔除上一轮使用过的API,再加入上面扩展的新API,进行一轮重新的尝试。
3. 评估
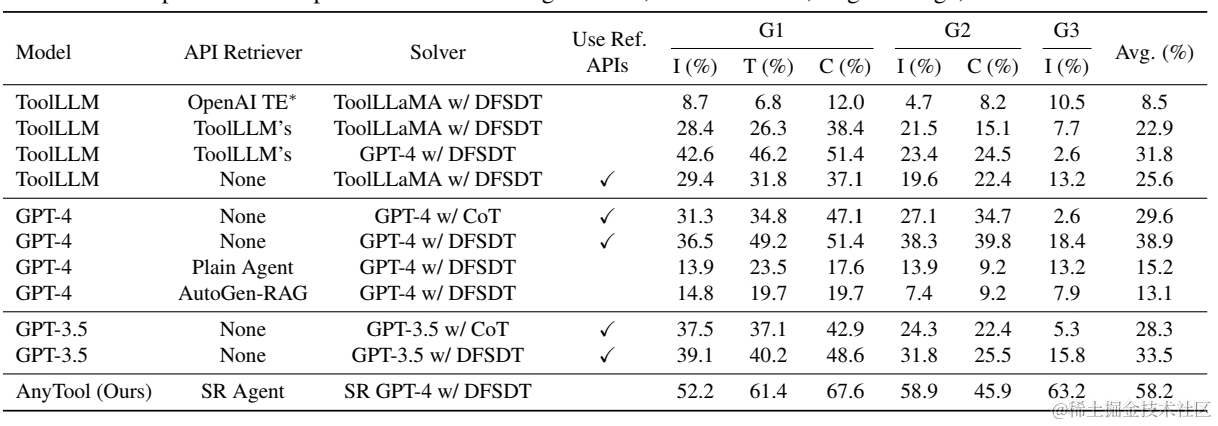
AnyTool针对以上ToolBench的评估标准中的Pass Rate进行了调整。ToolLLM在计算Pass Rate时分成了“可解决”和“不可解决”两个部分,其中“不可解决“是GPT4判断指令的候选API都和指令无关,或者指令本身不可解决。而这部分“不可解决”会大概率被算成通过。所以如果在构建指令的过程中,有相当量级的API候选和指令无关的话,就会拉高Pass Rate。而AnyTool在评估过程中,剔除了GPT4评估问题是否可解的步骤,直接评估模型的回答结果是否正确。并且对ToolBench集进行了人工过滤,剔除了无效的指令样本。 在过滤后的样本上,AnyTool只计算了Pass Rate结果如下,和以上ToolLLM一样分成了Inst-I, Category-C,Tool-T三种不同的样本外类型进行评估,AnyTool会有进一步的提升。
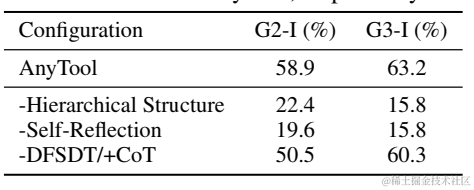
同时论文针对以上两个模块进行了消融实验,层次召回和反思模块对AnyTool的贡献都很大。个人对召回模块带来的提升更感兴趣,因为一切推理的前置模块的影响都更显著。也进一步印证了召回合理API这一步在整个工具调用链路中的重要性。
ToolLLM资源收藏
如果你也在开发工具相关服务,或者在设计Agent Pipeline,以下是一些可以学习借鉴的资源~
- Tool Server构建
- llama index tools:https://github.com/run-llama/llama_index/tree/main/llama-index-integrations/tools
- langchain tools: https://github.com/langchain-ai/langchain/tree/master/libs/community/langchain_community/tools
- phidata tools:https://github.com/phidatahq/phidata/tree/main/phi/tools
- BMTools:https://github.com/OpenBMB/BMTools
- MSAgent:https://github.com/modelscope/modelscope-agent
- 工作流搭建/中间层设计
- Coze: https://www.coze.com/store/bot
- Anakin: https://app.anakin.ai/discover
- Dify: https://cloud.dify.ai/tools
- langflow:https://www.langflow.org/
最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









