







GPT模型
GPT模型:生成式预训练模型(Generative Pre-Training)
总体结构:
无监督的预训练
有监督的下游任务精调
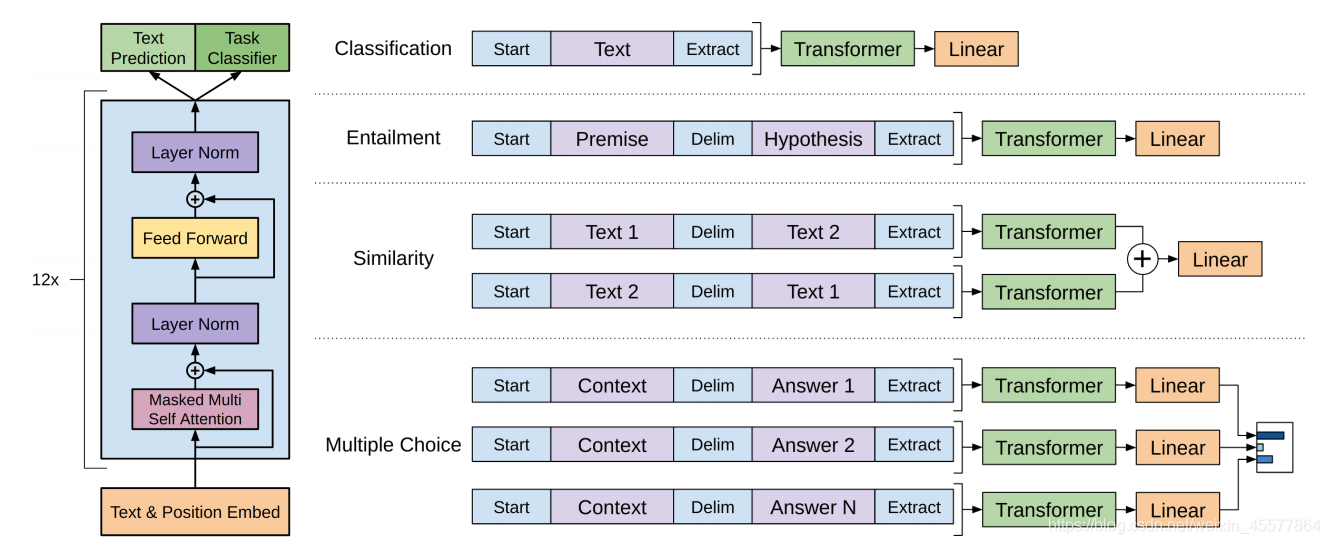
核心结构:中间部分主要由12个Transformer Decoder的block堆叠而成
下面这张图更直观地反映了模型的整体结构:
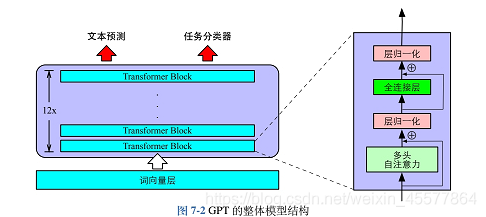
模型描述
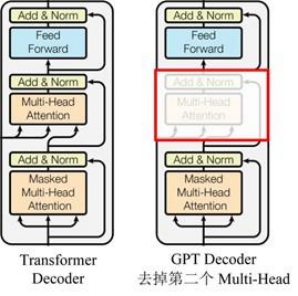
GPT 使用 Transformer的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
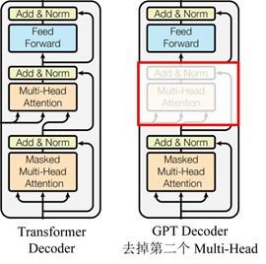
对比原有transformer的结构
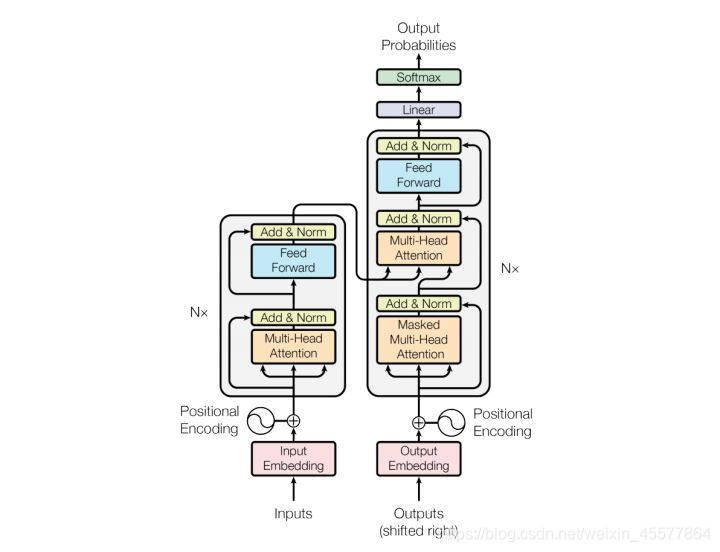
阶段描述
预训练阶段:



预训练阶段为文本预测,即根据已有的历史词预测当前时刻的词,7-2,7-3,7-4三个式子对应之前的GPT结构图,输出P(x)为输出,每个词被预测到的概率,再利用7-1式,计算最大似然函数,据此构造损失函数,即可以对该语言模型进行优化。
下游任务精调阶段

损失函数
下游任务与上游任务损失的线性组合

计算过程:
- 输入
- Embedding
- 多层transformer的block
- 拿到两个输出端结果
- 计算损失
- 反向传播
- 更新参数
一个具体的GPT实例代码:
可以看到GPT模型的forward函数中,首先进行Embedding操作,然后经过12层transformer的block中进行运算,然后分别经过两个线性变换得到最终计算值(一个用于文本预测,一个用于任务分类器),代码与最开始展示的模型结构图保持一致。
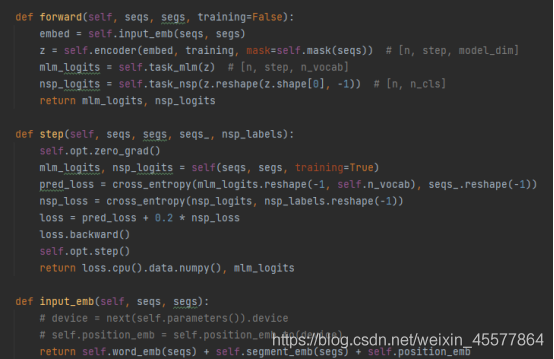
下面我们着重关注计算步骤2, 3
计算细节:
【Embedding层】:
查表操作
Embedding层就是以one hot为输入、中间层节点为字向量维数的全连接层。而这个全连接层的参数,就是一个“字向量表”。

one hot型的矩阵相乘,就像是相当于查表,于是它直接用查表作为操作,而不写成矩阵再运算,这大大降低了运算量。再次强调,降低了运算量不是因为词向量的出现,而是因为把one hot型的矩阵运算简化为了查表操作。
【GPT中类似transformer的decoder层】:
每个decoder层包含两个子层
- sublayer1: mask的多头注意力层
- sublayer2: ffn (feed-forward network)前馈网络(多层感知机)
sublayer1:mask的多头注意力层
输入: q, k, v, mask
计算注意力:Linear(矩阵乘法)→Scaled Dot-Product Attention→Concat(多个注意力的结果, reshape )→Linear(矩阵乘法)
残差连接和归一化操作:Dropout操作→残差连接→层归一化操作

计算过程:
下面这段内容介绍了计算注意力的整体过程:

分解说明:
Mask Multi-head Attention
1.矩阵乘法:
将输入的q,k,v进行变换

2.Scaled Dot-Product Attention
主要就是进行attention的计算以及mask的操作
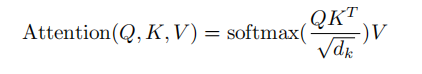

Mask操作:masked_fill_(mask, value)
掩码操作,用value填充tensor中与mask中值为1位置相对应的元素。mask的形状必须与要填充的tensor形状一致。(这里采用-inf填充,从而softmax之后变成0,相当于看不见后面的词)
transformer中的mask操作mask后可视化矩阵:
直观理解是每个词只能看到它之前的词(因为目的就是要预测未来的词嘛,要是看到了就不用预测了)

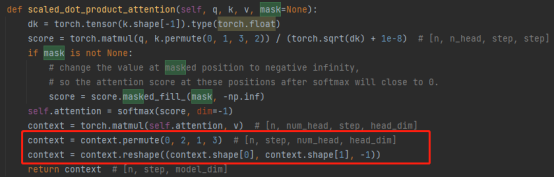
3.Concat操作:
综合多个注意力头的结果,实际上是对矩阵做变换:permute,reshape操作,降维。(如下图红框中所示)
4.矩阵乘法:一个Linear层,对注意力结果线性变换
整个mask多头注意力层的代码:
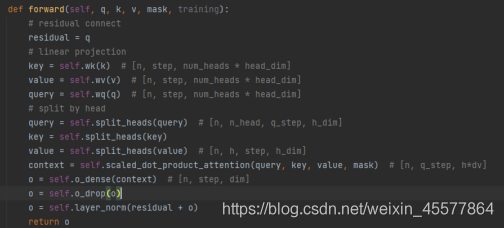
注意到:上述代码中后面几行是对注意力结果进行残差连接和归一化操作 下说明这一过程:
残差连接和归一化操作:
5.Dropout层
6.矩阵加法
7.层归一化
批量归一化是不同训练数据之间对单个神经元的归一化,层归一化是单个训练数据对某一层所有神经元之间的归一化。
输入归一化、批量归一化(BN)与层归一化(LN)
代码展示:

sublayer2: ffn (feed-forward network)前馈网络
1.线性层(矩阵乘法)
2.relu函数激活
3.线性层(矩阵乘法)
4.Dropout操作
5.层归一化

【线性层】:
多层block的输出结果放到两个线性层中进行变换,比较简单,不做赘述。
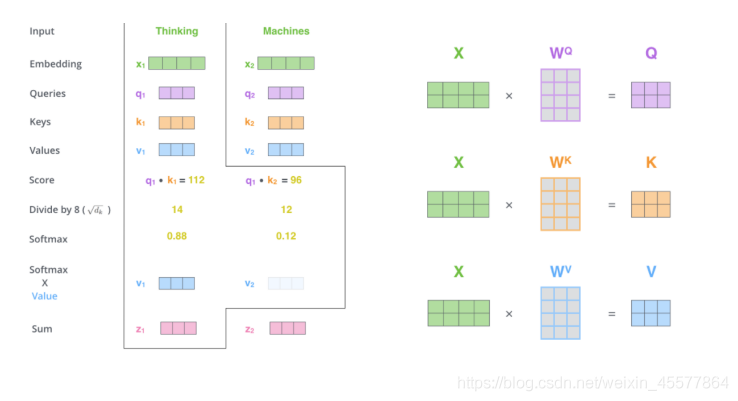
补充:注意力层流程图示
参考资料
1.参考论文:Radford et al. 《Improving Language Undersatnding by Generative Pre-Training"》
2.参考书籍:《自然语言处理 基于预训练模型的方法》车万翔,郭江,崔一鸣
3.本文中代码来源:莫烦Python GPT实现代码
最后
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频,免费分享!

一、大模型全套的学习路线
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署

达到L4级别也就意味着你具备了在大多数技术岗位上胜任的能力,想要达到顶尖水平,可能还需要更多的专业技能和实战经验。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人在大模型时代,需要不断提升自己的技术和认知水平,同时还需要具备责任感和伦理意识,为人工智能的健康发展贡献力量。
有需要全套的AI大模型学习资源的小伙伴,可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。















 808
808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









