






GPT的背景来源和发展简述
GPT(Generative Pre-Trained Transformer,生成式预训练Transformer模型),它是基于Transformer的Decoder解码器在海量文本上训练得到的预训练模型。GPT采用自回归的工作方式,能够查看句子的一部分并且预测下一个单词,不断重复这个过程来生成连贯且适当上下文文本。
GPT的诞生早于Bert,相比于Bert针对的任务通常是文本分类、实体识别、完型填空, GPT这种完全自行生成类似人类语言文本的任务更具挑战性,是强人工智能的体现,ChatGPT就是在GPT技术的基础之上开发的交互式对话版本。
GPT的自回归工作方式
给定一个前句,将它作为问题或者引导词输入给GPT,GPT基于这个句子预测一个单词,同时预测出的词会加入到原始句子的结尾合并成一个新的句子作为形成下一次的输入,这种工作方式被成为自回归性,如下图所示
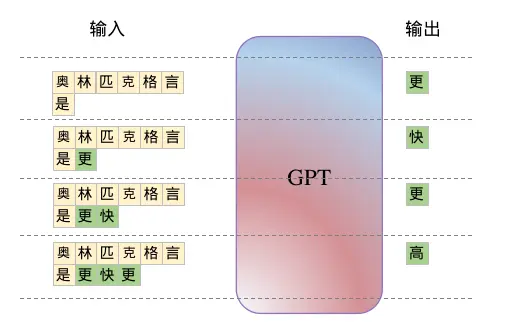
GPT的最回归工作方式
在训练阶段GPT采用对文本进行shifted-right右移一位的方式构造出输入和输出,在预测推理阶段采用自回归的方式通过持续地更新上下文窗口中的输入来源源不断的预测下去。
图解GPT-2的网络结构
GPT系列自OpenAI在2018年发布的第一代GPT-1开始,以及后的GPT-2,GPT-3,他们的区别主要在于预训练数据和模型参数的规模在不断扩大,以及训练策略优化等等,而模型网络结构并没有大的改变,都是以堆叠Transformer的解码器Decoder作为基座。
| 模型 | 发布时间 | 层数 | 头数 | 词向量长度 | 参数量 | 预训练数据量 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018年6月 | 12 | 12 | 768 | 1.17亿 | 5GB |
| GPT-2 | 2019年2月 | 48 | 25 | 1600 | 15亿 | 40GB |
| GPT-3 | 2020年5月 | 96 | 96 | 12888 | 1750亿 | 45TB |
本篇采用GPT-2作为GPT系列网路结构的说明。
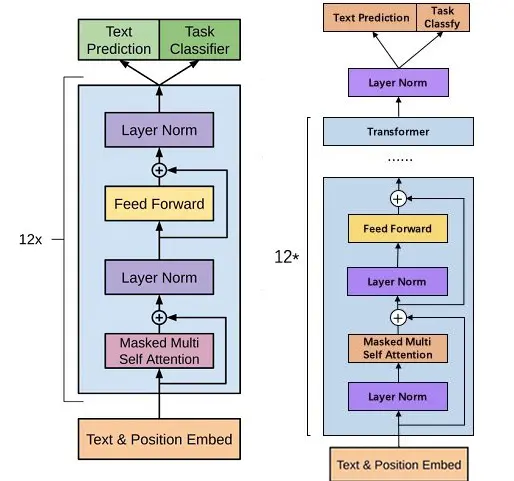
GPT-1,GPT-2网络结构
上图所示左侧为GPT-1结构,右侧为GPT-2结构,堆叠了12层Transformer的Decoder解码器,GPT-2略微修改了Layer Norm层归一化的位置,输入层对上下文窗口长度大小(block size)的文本做建模,使用token embedding+位置编码,输出层获取解码向量信息,最后一个block对应的向量为下一个词的信息表征,可以对该向量做分类任务完成序列的生成。
GPT-2本质上沿用了Transformer的解码器Self Attention机制,在堆叠的每一层,当前时刻信息的表征,只能使用当前词和当前词之前的信息,不能像Bert那样既能看到左侧的词又能看到右侧的词,因为GPT是文本生成任务,而Bert是给定了全文的基础上进行语意理解,两者区别如下图所示
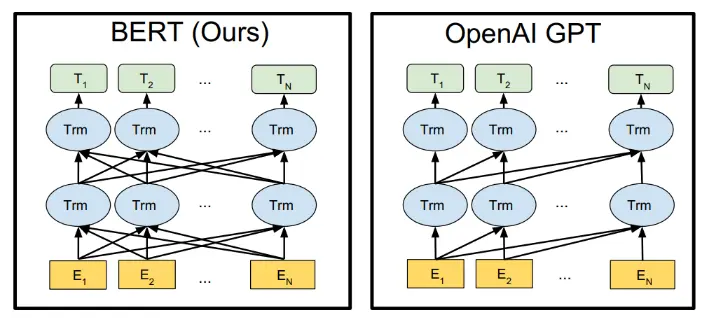
GPT和Bert的区别
GPT的解码采样策略
GPT的堆叠Decoder结构输出的最后一个block的embedding,再结合Linear线性层和Softmax层映射到全部词表,即可获得下一个单词的概率分布,GPT的解码过程就是基于概率分布来确定下一个单词是谁,显然得分高的更应该被作为预测结果。GPT常用的解码策略有贪婪采样和多项式采样
- 贪婪采样:在每一步选择概率最高的单词作为结果。这种方法简单高效,但是可能会导致生成的文本过于单调和重复
- 多项式采样:在每一步根据概率分布作为权重,随机选择单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义,出现比较离谱的生成结果
用PyTorch模拟一个基于多项式采样的例子如下
>>> import torch
>>> weights = torch.Tensor([0, 1, 2, 3, 4, 5])
>>> cnt = {}
>>> for i in range(10000):
>>> res = torch.multinomial(weights, 1).item()
>>> cnt[res] = cnt.get(aaa, 0) + 1
>>> cnt
{5: 3302, 2: 1307, 3: 1994, 1: 707, 4: 2690}
采用torch.multinomial模拟10000次采样,记录下最终采样的结果,结论是被采样到的概率基本等于该单词的权重占全部权重的比例。
通常GPT采用多项式采样结合Temperature温度系数,Top-K,Top-P来一起完成联合采样。
Temperature温度系数
温度系数是一个大于0的值,温度系数会对概率得分分布做统一的缩放,具体做法是在softmax之前对原始得分除以温度系数,公式如下
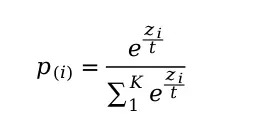
温度系数公式
当温度系数大于1时,高得分单词和低得分单词的差距被缩小,导致多项式采样的倾向更加均匀化,结果是生成的内容多样性更高。当温度系数小于1时,高得分单词和低得分单词的差距被放大,导致多项式采样的更加倾向于选择得分高的单词,生成的内容确定性更高。默认温度系数等于1,此时等同于使用原始的概率分布不做任何缩放。。
使用PyTorch模拟温度系数分别为2和0.5,结果如下
>>> torch.softmax(torch.tensor([1.0, 2.0, 3.0, 4.0]), -1)
tensor([0.0321, 0.0871, 0.2369, 0.6439])
>>> # 温度系数为2
>>> torch.softmax(torch.tensor([1.0, 2.0, 3.0, 4.0]) / 2, -1)
tensor([0.1015, 0.1674, 0.2760, 0.4551])
>>> # 温度系数为0.5
>>> torch.softmax(torch.tensor([1.0, 2.0, 3.0, 4.0]) / 0.5, -1)
tensor([0.0021, 0.0158, 0.1171, 0.8650])
显然温度系数越高为2时抽样概率越平均,温度系数越低为0.5时抽样概率越极端,对高分的顶部词更加强化。
Top-K
Top-K指的是将词表中所有单词根据概率分布从高到低排序,选取前K个作为采样候选,剩下的其他单词永远不会被采样到,这样做是可以将过于离谱的单词直接排除在外,一定程度上提高了多项式采样策略的准确性。同样的k越大,生成的多样性越高,k 越小,生成的质量一般越高。
Top-P
Top-P和Top-K类似,选取头部单词概率累加到阈值P截止,剩余的长尾单词全部丢弃,例如P=95%,单词A的概率为0.85,单词B的概率为0.11,头部的两个词概率相加已经达到95%,因此该步的采样候选只有单词A和单词B,其他词不会被采样到。对位概率分布长尾的情况,Top-P相比于Top-K更加可以避免抽样到一些概率过低的不相关的词。
minGPT源码分析和文本生成实战
minGPT项目是基于PyTorch实现的GPT-2,它包含GPT-2的训练和推理,本篇以minGPT的chargpt例子作源码分析。chargpt是训练用户自定义的语料,训练完成后基于用户给到的文本可以实现自动续先,本例采用电视剧《狂飙》的部分章节作为语料灌给GPT-2进行训练。
模型参数概览
定位到chargpt.py,首先作者定义了数据和模型相关的参数配置,部分关键配置信息如下
data:
block_size: 128
model:
model_type: gpt-mini
n_layer: 6
n_head: 6
n_embd: 192
vocab_size: 2121
block_size: 128
embd_pdrop: 0.1
resid_pdrop: 0.1
attn_pdrop: 0.1
trainer:
num_workers: 4
max_iters: None
batch_size: 64
learning_rate: 0.0005
betas: (0.9, 0.95)
weight_decay: 0.1
grad_norm_clip: 1.0
- block_size:上下文窗口长度,也是输入的最大文本长度为128
- model_type:gpt模型类型,这里采用gpt-mini,一个小规模参数的gpt,它包含6层Decoder,6个自注意力头,词向量的embedding维度为192
- num_workers:DataLoader加载数据的子进程数量,可以加快训练速度,对模型结果没有影响
训练数据构造
需要用户自己指定一个input.txt,其内容为合并了所有文本而成的一行字符串
text = open('input.txt', 'r').read()
train_dataset = CharDataset(config.data, text)
CharDataset基于PyTorch的Dataset构造,len和getitem实现如下
def __len__(self):
return len(self.data) - self.config.block_size
def __getitem__(self, idx):
# grab a chunk of (block_size + 1) characters from the data
chunk = self.data[idx:idx + self.config.block_size + 1]
# encode every character to an integer
dix = [self.stoi[s] for s in chunk]
# return as tensors
x = torch.tensor(dix[:-1], dtype=torch.long)
y = torch.tensor(dix[1:], dtype=torch.long)
return x, y
采用上下文窗口在原文本上从前滑动到最后,生成文本长度减去上下文窗口大小的实例作为len,getitem部分实现训练的输入x和目标y,每次选取129个连续的字符作为一个块,然后以前128个作为x,后128个作为y,实现shifted right。
gpt模型构建
作者将配置参数传递给GPT类实例化一个GPT网络
model = GPT(config.model)
在GPT类中实现了网路的各个元素,包括token embedding,位置编码,Decoder,Decoder结束后的层归一化,以及最后的概率分布线性映射层
self.transformer = nn.ModuleDict(dict(
# TODO 输入的embedding [10, 48]
wte=nn.Embedding(config.vocab_size, config.n_embd),
# TODO 位置编码,block_size是上下文窗口 [6, 48]
wpe=nn.Embedding(config.block_size, config.n_embd),
drop=nn.Dropout(config.embd_pdrop), # 0.1
# TODO 隐藏层,6层transformer
h=nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f=nn.LayerNorm(config.n_embd),
))
# TODO 线性层输出概率分布
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
其中定义h为一个包含6层的堆叠Decoder,Block实现了其中每一个Decoder单元,内部包括点积注意力层,层归一化,前馈传播层和残差连接,实现如下
class Block(nn.Module):
def __init__(self, config):
super().__init__()
self.ln_1 = nn.LayerNorm(config.n_embd)
# TODO 自回归模型中的自注意力层
self.attn = CausalSelfAttention(config)
self.ln_2 = nn.LayerNorm(config.n_embd)
self.mlp = nn.ModuleDict(dict(
c_fc=nn.Linear(config.n_embd, 4 * config.n_embd),
c_proj=nn.Linear(4 * config.n_embd, config.n_embd),
act=NewGELU(),
dropout=nn.Dropout(config.resid_pdrop),
))
m = self.mlp
# TODO feed forward层
self.mlpf = lambda x: m.dropout(m.c_proj(m.act(m.c_fc(x)))) # MLP forward
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlpf(self.ln_2(x))
return x
forward中顺序有所不同,GPT-2中将层归一化提前到了注意力操作之前。
核心的点积注意力在CausalSelfAttention中实现,该类自己维护了下三角矩阵用于对后面的词进行mask。
class CausalSelfAttention(nn.Module):
def __init__(self, config):
...
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
B, T, C = x.size()
...
att = att.masked_fill(self.bias[:, :, :T, :T] == 0, float('-inf'))
作者先定义了一个基于block_size全局最大128×128的下三角矩阵bias,而实际在使用时,根据输入文本的实际长度T从左上角开始取对应T×T形状,无论T多长bias始终是下三角矩阵,接着将注意力矩阵上三角部分全部置为-inf,从而使得所有后词信息被隔离。这个下三角掩码不论输入句子长度多长,并且在每一层堆叠的Decoder上都会生效。
在网络搭建好后,作者构建输入层,它是由token embedding和位置编码相加而成
b, t = idx.size()
pos = torch.arange(0, t, dtype=torch.long, device=device).unsqueeze(0)
tok_emb = self.transformer.wte(idx) # token embeddings
pos_emb = self.transformer.wpe(pos) # position embeddings
x = self.transformer.drop(tok_emb + pos_emb)
紧接着输入到由6层Decode组成的隐层h,GPT-2在Decoder结束之后又加了层归一化ln_f,最终到线性映射层lm_head输出预测到词表的得分分布
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
logits = self.lm_head(x)
损失函数
损失采用每个预测位置的多分类交叉熵,一个批次下将所有样本合并拉直,最终所有位置的交叉熵取平均值作为最终损失
loss = None
if targets is not None:
# TODO logits => [batch_size * seq_len, 10], target => [batch_size * seq_len, ]
# TODO 该批次下 每条样本,每个位置下预测的多分类交叉熵损失 的平均值
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
模型推理
在模型推理阶段使用generate类方法,该方法定义了最大推理步长,温度系数等参数。作者给了个例子,输入一句话,对其进行自回归预测下一个单词,其中最大预测100步,温度系数为1.0,采用多项式采样,限制Top-K为10
with torch.no_grad():
context = "高启强被捕之后"
# TODO [seq_len, ] => [batch_size, seq_len]
x = torch.tensor([train_dataset.stoi[s] for s in context], dtype=torch.long)[None, ...].to(trainer.device)
y = model.generate(x, 100, temperature=1.0, do_sample=True, top_k=10)[0]
completion = ''.join([train_dataset.itos[int(i)] for i in y])
跟进generate方法查看源码实现
def generate(self, idx, max_new_tokens, temperature=1.0, do_sample=False, top_k=None):
# TODO idx => [batch_size, 4]
for _ in range(max_new_tokens):
# TODO idx_cond不定长,只要低于最大上下文窗口即可, 如果文本超过block上下文窗口(输入序列最大长度),向前截取,取最后和block等长的
idx_cond = idx if idx.size(1) <= self.block_size else idx[:, -self.block_size:]
# TODO [batch_size, seq_len, 10]
logits, _ = self(idx_cond)
# TODO [batch_size, 10] 拿到最后一个block位置的作为下一个单词的概率得分分布
# TODO temperature 温度系数, 默认为1,不对分数做任何缩放
# TODO 温度系数越大,得分差距缩短,多样性更大,温度系数越小,得分差距加大,多样性更低
logits = logits[:, -1, :] / temperature
# TODO 只选取得分最大的topk个
if top_k is not None:
# TODO 输出最大值和最大值的索引
# TODO v => [batch_size, topk]
v, _ = torch.topk(logits, top_k)
# TODO v[:, [-1]] => [batch_size, 1], topk的最小值, 将没有进入topk的全部改为-inf
logits[logits < v[:, [-1]]] = -float('Inf')
# TODO [batch_size, 10] 经过温度系数和topk压缩之后使用softmax转化为概率
probs = F.softmax(logits, dim=-1)
if do_sample:
# TODO 根据概率作为权重采样其中一个,概率越大被采样到的概率越大
# TODO 温度系数的大小会直接影响这个地方的采样权重,温度系数决定了在topk范围内的采样多样性
# TODO topK会把没有进入topk的softmax概率转化为0,使得永远不能被采样到, topk决定了哪些会被采样到
# TODO idx_next => [batch_size, 1]
idx_next = torch.multinomial(probs, num_samples=1)
else:
# TODO 贪婪搜索 [batch_size, 1]
_, idx_next = torch.topk(probs, k=1, dim=-1)
# TODO 将预测的新单词拼接到原始输入上作为新的输入
idx = torch.cat((idx, idx_next), dim=1)
return idx
其中idx为自回归维护的输入,每次预测完下一个单词拼接到结尾覆盖更新idx
idx = torch.cat((idx, idx_next), dim=1)
在每次推理过程中只使用上下文窗口中最后一个block的输出作为下个单词的推理依据
logits = logits[:, -1, :] / temperature
在采样策略顺序上,先进行温度系数缩放,再进行top_k筛选,最后通过softmax压缩为概率,最终采用torch.multinomial进行多项式采样,top_k的实现是将所有非top_k的位置得分置为-inf,使得softmax压缩为0,只要存在其他非0权重,多项式采样永远不会将0采样出来,通过这种方法将非top_k在解码中剔除。
模型训练
基于《狂飙》语料灌入定义好的gpt-mini,每迭代500词打印一次模型推理的结果,我们给到例句“高启强被捕之后”,查看随着损失的收敛,模型预测接下来50个词的结果
| 迭代次数 | 损失 | 生成结果 |
|---|---|---|
| 0 | 7.696 | 高启强被捕之后操”徐”,姓”,越,尬””越上”越徐噎曲噎噎的猫上建验建,姓”越拼越津噎,”建,,的,,,上”上”越 |
| 1000 | 0.671 | 高启强被捕之后,高启强看着安静地洗得很好的摊子。音在顺道我们送礼物就去躲到了解决。门诊大夫都准备,你再帮忙!”“不 |
| 2000 | 0.288 | 高启强被捕之后的遗照片的下医院常车牌,刑警队员礼貌似乎跑断。耳机里的现场馆情不伦次,虽然快地想立即决定:将自己在将 |
| 3000 | 0.200 | 高启强被捕之后,安欣也十分爽快地答应帮忙——只要高家兄弟拿出三万元。正在高启强一筹莫展的时候,唐小龙介绍了一个门道 |
| 7500 | 0.107 | 高启强被捕之后,高启强终于弄明白了是怎么回事。原来唐家兄弟自从上次见到安欣和李响之后,便四处打听安欣的身份,确定了 |
| 8500 | 0.095 | 高启强被捕之后随即打开怀里的包,点出一本厚的法医学专著摆在桌上,得意地指了指,“看看。”安欣一怔:“你怎么看这个? |
随着损失的收敛,生成结果逐渐变得连贯,尤其最后一句从语法和语义上基本挑不出什么问题,也预测出了训练集中的部分原文。此处只是一个例子在给定文本上从头训练一个简单的小规模gpt网络,如果期望更好的效果需要基于更大规模数据的预训练gpt模型。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









