






前言
高性能计算HPC、人工智能AI技术的发展,带来了不断激增的计算量,必须通过大规模集群算力才能充分发挥优势,例如,ChatGPT模型参数总量已经达到千亿级别,高性能计算也已经迈向百亿亿级计算时代。所谓的大规模训练就是使用大规模的数据或大规模参数量的模型来做训练。
相对于单卡训练,大规模的分布式训练常在训练数据量较大或模型参数规模太大导致单卡不可训练的场景下使用。如当训练数据量较大时,单卡训练耗时过长,需要分布式训练技术提高训练效率;或者当单卡无法支持训练时,即单卡显存无法放下全量模型参数时,可使用分布式训练技术将模型参数等模型信息切分到多张卡或多台设备上,以保证模型可训练。集合通信训练模式和参数服务器训练模式是两种最主要的分布式训练模式。
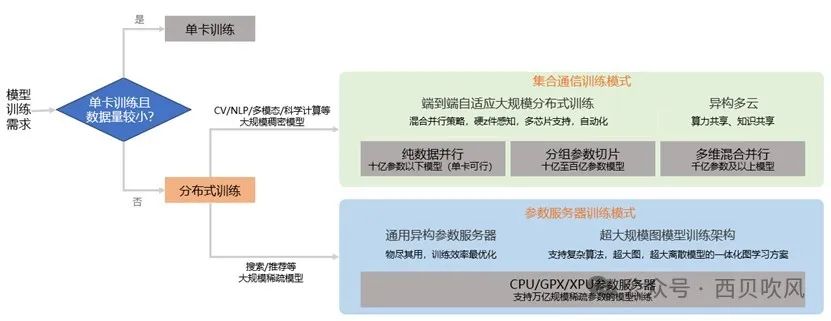
其中,集合通信(Collective communication)广泛运用在并行计算和分布式深度学习中,每台主机计算或训练好的参数通过集合通信进行全局更新和同步,随着数据量和集群规模增大,集合通信将成为性能瓶颈。
关于AllReduce集合通信原语
AllReduce是深度学习领域最常用的集合通信原语–归约操作,主要用于多机/多卡之间的梯度同步。提到AllReduce,就不得不说一下MPI(Message Passing Interface),MPI是一个定义了多个原语的消息传递接口,主要被用于多进程间的通信,OpenMPI是MPI的常用实现之一,在MPI中实现了多种AllReduce算法。以下我们先来看一下,AllReduce算法及其实现。
AllReduce通信从所有主机收集向量,以元素级方式“集合”向量,并将集合结果广播给它们(所谓“集合”主要包括求和、求最大、最小值等)。
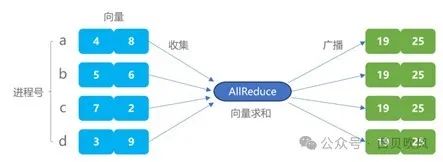
近年来涌现了非常多的AllReduce算法,其中,比较经典的算法有:PS算法(Parameter server)、经典树形算法(Recursive halving and doubling)、Butterfly算法、Ring算法、Rabenseifner算法等。
PS算法(Parameter server),这是最直观的一种实现方式,Reduce + Broadcast,Parameter server作为中心节点,先全局Reduce接收所有其他节点的数据,经过本地计算后,再Broadcast回所有其他节点。该算法优点是简单、低时延;最大的缺点就是Parameter server节点会成为带宽瓶颈,存在N:1的incast问题。
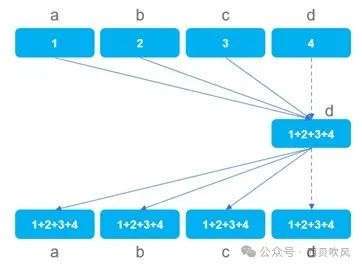
经典树形算法,如果节点数是2的幂,所需通信步数是2*log2N。相比PS算法,最大的改进是规避了单节点的带宽瓶颈。该算法优点是简单、无单点瓶颈;缺点是时延高,不能同时利用发送和接收带宽。
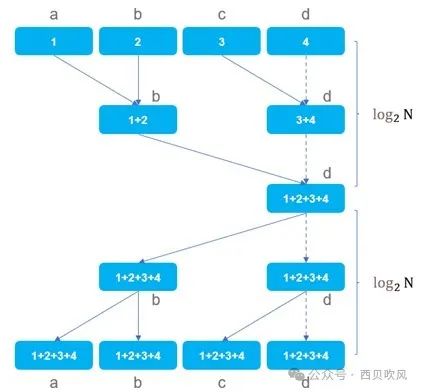
如果节点数不是2的幂,则会先调整至符合2的幂后,再进行上述经典树形算法的操作。
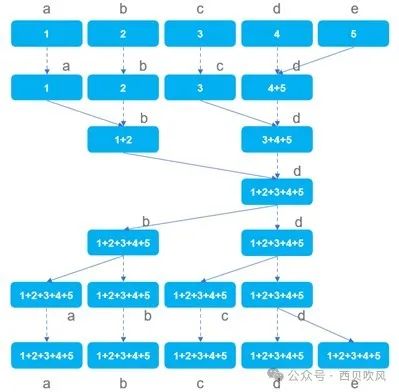
Butterfly算法,通信的每步中,所有节点的发送和接收带宽都被利用起来了,如果节点数是2的幂,所需通信步数只有log2N。优点是所有节点的发送和接收带宽充分利用;缺点是大数据块时性能不理想,容易出现时延抖动。
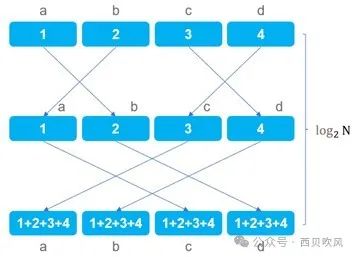
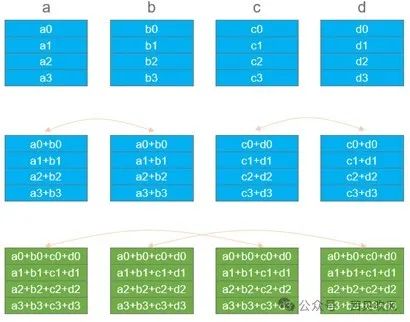
Ring算法默认把每个节点的数据切分成N份,可以充分利用所有节点的发送和接收带宽,同时也改善了大数据块时的性能和时延抖动问题。Ring算法更容易实现高带宽,发送的数量量少,集合大数据的性能更好,但时延也更高。
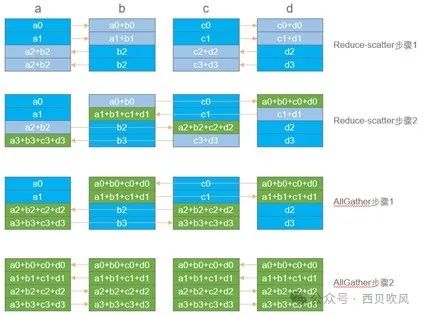
Ring算法在做AllReduce算法时,分两个环节,分别是Reduce-scatter和AllGather。
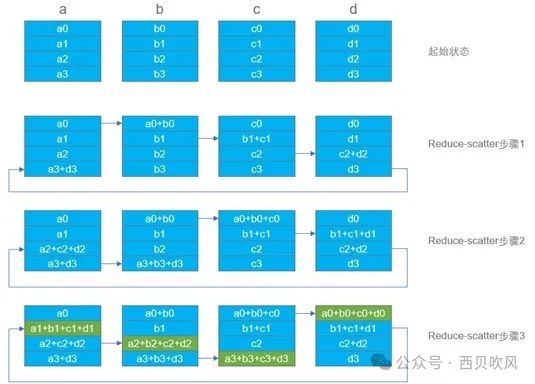
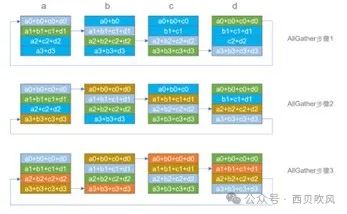
递归加倍算法,步骤少,整合小数据时性能好,整合大数据块时性能不理想,容易出现时延抖动。
Rabenseifner算法,步骤数相对较少,发送数量量少,聚合大数据的性能较好。
上面简单总结了一下各种AllReduce算法实现,由于AllReduce算法的优化空间越来越少,业内逐渐转移到了拓扑感知的AllReduce算法,即在特定的拓扑上优化Allreduce算法,如2D-Torus算法、2D-Mesh算法、3D-Torus算法、Double binary tree算法等。
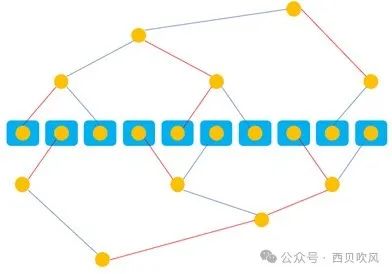
其中,Double binary tree(双二叉树)算法在多层CLOS架构组网中也有比较多的应用,前面提到经典树形组网优点是简单、无单点瓶颈,缺点是时延高,不能同时利用发送和接收带宽,为了充分利用带宽,提出了Double binary tree算法。
假设一共有N个节点,MPI会构建两个大小为N的树T1和T2,T1的中间节点在T2中是叶节点,T1和T2同时运行,各自负责消息M的一半,这样每个节点的双向带宽可以都被利用到。以十台机器为例,构建出的结构如下:
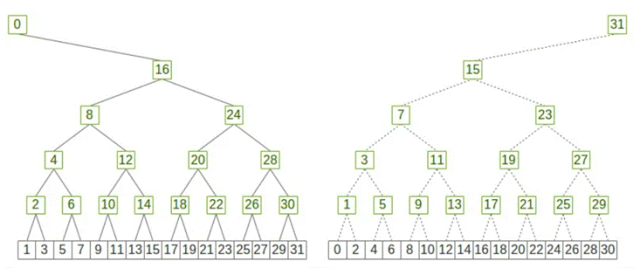
下面是一个32节点的双二叉树结构:
最后
学习AI大模型是一个系统的过程,需要从基础开始,逐步深入到更高级的技术。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频,免费分享!

一、大模型全套的学习路线
L1级别:AI大模型时代的华丽登场
L2级别:AI大模型API应用开发工程
L3级别:大模型应用架构进阶实践
L4级别:大模型微调与私有化部署

达到L4级别也就意味着你具备了在大多数技术岗位上胜任的能力,想要达到顶尖水平,可能还需要更多的专业技能和实战经验。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人在大模型时代,需要不断提升自己的技术和认知水平,同时还需要具备责任感和伦理意识,为人工智能的健康发展贡献力量。
有需要全套的AI大模型学习资源的小伙伴,可以微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

如有侵权,请联系删除。

















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









