







算法介绍
KD树的全称为k-Dimension Tree的简称,是一种分割K维空间的数据结构,主要应用于关键信息的搜索。为什么说是K维的呢,因为这时候的空间不仅仅是2维度的,他可能是3维,4维度的或者是更多。我们举个例子,如果是二维的空间,对于其中的空间进行分割的就是一条条的分割线,比如说下面这个样子。
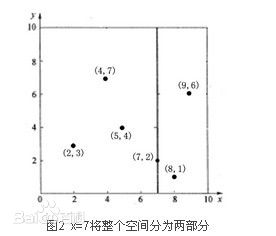
如果是3维的呢,那么分割的媒介就是一个平面了,下面是3维空间的分割
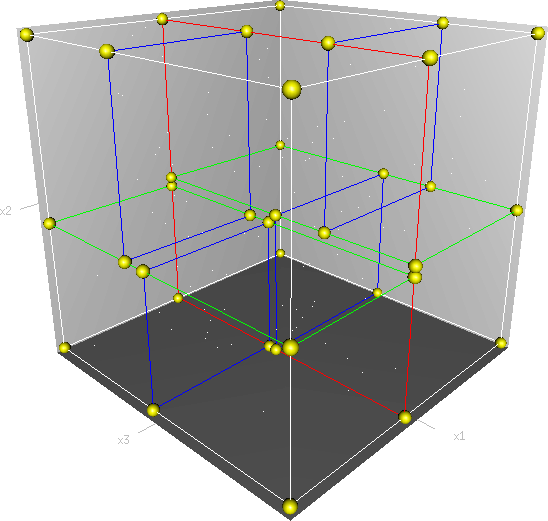
这就稍稍有点抽象了,如果是3维以上,我们把这样的分割媒介可以统统叫做超平面 。那么KD树算法有什么特别之处呢,还有他与K-NN算法之间又有什么关系呢,这将是下面所将要描述的。
KNN
KNN就是K最近邻算法,他是一个分类算法,因为算法简单,分类效果也还不错,也被许多人使用着,算法的原理就是选出与给定数据最近的k个数据,然后根据k个数据中占比最多的分类作为测试数据的最终分类。图示如下:
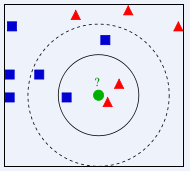
算法固然简单,但是其中通过逐个去比较的办法求得最近的k个数据点,效率太低,时间复杂度会随着训练数据数量的增多而线性增长。于是就需要一种更加高效快速的办法来找到所给查询点的最近邻,而KD树就是其中的一种行之有效的办法。但是不管是KNN算法还是KD树算法,他们都属于相似性查询中的K近邻查询的范畴。在相似性查询算法中还有一类查询是范围查询,就是给定距离阈值和查询点,dbscan算法可以说是一种范围查询,基于给定点进行局部密度范围的搜索。想要了解KNN算法或者是Dbscan算法的可以点击我的K-最近邻算法和Dbscan基于密度的聚类算法。
KD-Tree
在KNN算法中,针对查询点数据的查找采用的是线性扫描的方法,说白了就是暴力比较,KD树在这方面用了二分划分的思想,将数据进行逐层空间上的划分,大大的提高了查询的速度,可以理解为一个变形的二分搜索时间,只不过这个适用到了多维空间的层次上。下面是二维空间的情况下,数据的划分结果:
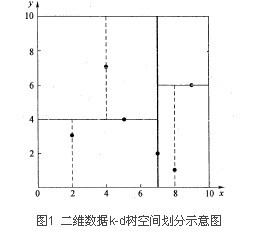
现在看到的图在逻辑上的意思就是一棵完整的二叉树,虚线上的点是叶子节点。
KD树的算法原理
KD树的算法的实现原理并不是那么好理解,主要分为树的构建和基于KD树进行最近邻的查询2个过程,后者比前者更加复杂。当然,要想实现最近点的查询,首先我们得先理解KD树的构建过程。下面是KD树节点的定义,摘自百度百科:
|
域名
|
数据类型
|
描述
|
|
Node-data
|
数据矢量
|
数据集中某个数据点,是n维矢量(这里也就是k维)
|
|
Range
|
空间矢量
|
该节点所代表的空间范围
|
|
|
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









