







前言
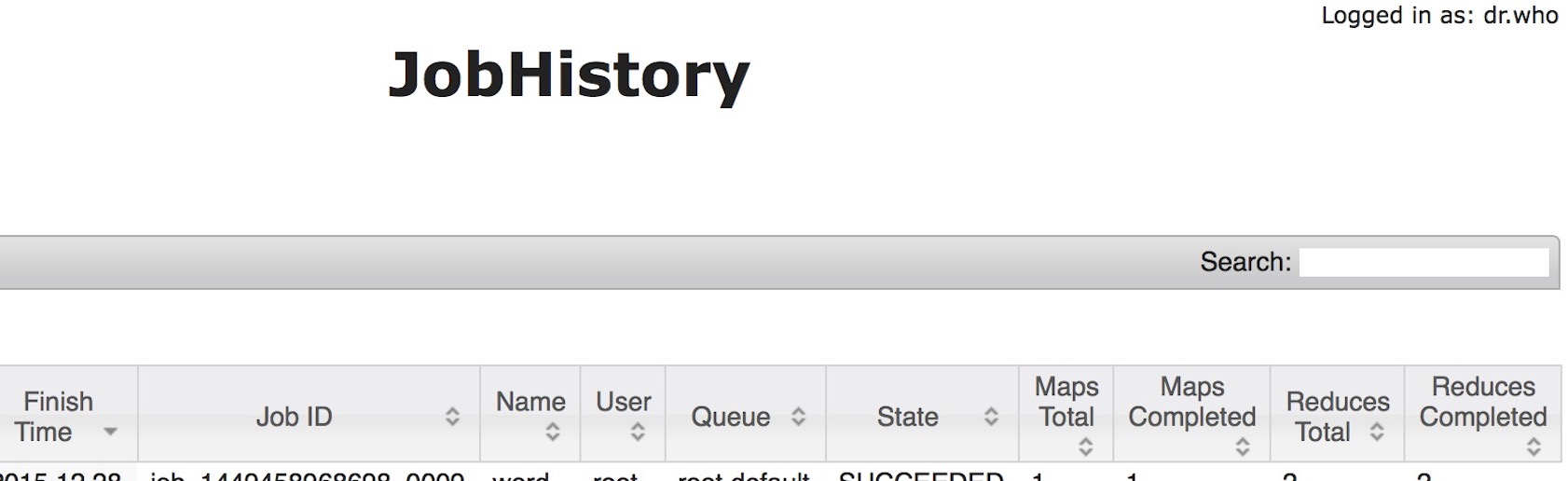
做过hadoop集群问题排查工作的同学一定用过JobHistory,这是一个很好用的"利器",为什么这么说呢?正如这个工具的名称所叫的那样,这个工具能帮你找到历史Job跑过的信息,而信息的记录非常的详细,从Job到Task再到TaskAttempt.假如这时候,1个Job突然执行失败了,你想查明原因,在JobHistory的web界面上依次点击详情链接,基本上都可以找到原因.但是看似非常完美的Job分析工具,也有许多使用起来不是很方便的地方,于是乎,我们想对此进行一些改进,使其更加易用,同时相信能给同样在使用jobHistory的人提供帮助.
现有JobHistory的不足之处
从开始使用这个分析工具到现在,1个让我一直用着特别不爽的地方是,很难迅速查到历史时间稍稍远一些的Job信息,因为有的时候我要做同时段的Job运行情况对比,包括运行时长,Task失败次数等等指标.所以你需要把昨天,前天的数据拉出来.然后很多人的正常反应就是把Jobhistory页面上默认显示的Job条数加大,以此显示更长时间的Job.这个方法既简单又方便,通过更改下面这个配置项,并重启JobHistory就可以立马做到:
<property>
<name>mapreduce.jobhistory.joblist.cache.size</name>
<value>20000</value>
<description>Size of the job list cache</description>
</property>这个默认值是显示2w条,大家千万不要以为这个值很大,当你的集群1天能跑上万个job的时候,这个值显然是偏小的,你只能显示到近2,3天的数据,如果突然我想看上周的数据,发现没法看了,这简直就是恶梦.当时我们也遇到了这种情况,然后我们把这个配置项调大到10w,这样就可以保留近一段时间的数据了.但是另外一个问题暴露出来了,页面加载太慢,JobHistory的主页面在1分钟之内是别想显示出来了,大家如果读过jobHistory页面的渲染代码,你可以看到,他的页面是直接全部渲染好之后显示的,并没有说所谓的每页只加载一部分,你要加载10w
条记录,我立即返回10w条记录,构成超级大的html页面,返回到浏览器上,所以我们后来发现很多的时间开销都花在下载页面的时间上,而非后端返回Job列表信息的时间上.但是没有办法,为了能看到更多的历史数据,只能牺牲一下用户体验了.相信博友们当中肯定有一部分人也遇到了这样的问题.描述了这么多,其实我们最终想要达到的1个目标就是,我既想不用显示那么多的Job数据,保留最近1天的即可,使得页面能迅速打开,其次我又能够查到历史数据.显然,这在原本的jobHistory中是无法兼顾的,所以我们可以改造一下他,使得这个工具能够更加"智能化"一些.
JobHistory使用现状
下面来看看,目前一般hadoop开发者是如何使用jobHistory,一般都会用到下面这个按钮:
这个一个非常广的搜索按钮,Job页面信息加载完成之后,你可以输入你想要的目标Job名称,过滤结果马上就会出现,当你把查询字符串进行清除,Job列表记录又会恢复到原样.很显然,这是1个非常简单直接化的搜索功能.我就这么多的信息,有就显示,没有就不显示.所以要想达到上小节中提到的优化目标,我们必须在搜索功能上进行优化改造.当然,我们会保留目前的搜索按钮,保持其不变.
JobHistory搜索优化目标
从上文中我们知道要做到JobHistory"智能化",需要在搜索功能方面进行改造.那么具体什么样的搜索场景是我们比较容易碰到的呢?
第一个,根据Job名称,我们知道失败的Job名称,然后,进行查询.
第二个,根据Jobid,我们从日志中或其他途径得到失败的Job,直接进行Job搜索,跳转至详情页.
而且还有最关键的1个前提,上述搜索功能的实现是不依赖前端页面显示的Job信息列表,比如我Job显示数量配成10条,我依然可以查到1周前某某失败Job的信息.下面是几个要点:
1.这里就需要做到jobHistory前后端cache-job数的配置分离,目前用的都是同一个配置,所以会导致上述这样的问题.
2.完成第二个需求点比第一个容易,因为第二个有jobid,直接进行链接的拼装,直接进行一个重定向就可以解决,所有的Job详情页信息链接都是一个模板,不用实现得过于复杂.
3.第一个需求需要后端通过传进来的Job名称做一些过滤处理,然后再返给前端展示,过滤掉绝大多数无用的Job信息.像类似于这样的需求,如果在普通的业务系统开发中,一定是再简单不过了,那么在hadoop中要如何改造呢,人家的这一套逻辑实现可没这么简单直接.
JobHistory具体代码改造
前面讲述完目标和方法之后,最后需要真正的从代码层面去实现了,所以需要了解一下目前JobHistory主页面是如何得到的,数据哪里来,页面前端代码哪里写的,是直接有现成的.html文件?光凭空猜想是没有用的,只有深入源代码的研究分析才能有答案.其实页面的代码实现在HsJobsBlock.java这个类中.页面渲染的逻辑实现就是在render方法中实现的
/*
* (non-Javadoc)
* @see org.apache.hadoop.yarn.webapp.view.HtmlBlock#render(org.apache.hadoop.yarn.webapp.view.HtmlBlock.Block)
*/
@Override protected void render(Block html) {
TBODY<TABLE<Hamlet 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 573
573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









