






论文信息
REF:https://blog.csdn.net/c9Yv2cf9I06K2A9E/article/details/130550415
论文标题:
PDFormer: Propagation Delay-aware Dynamic Long-range Transformer for Traffic Flow Prediction
论文链接:
https://arxiv.org/abs/2301.07945
代码链接:
https://github.com/BUAABIGSCity/PDFormer
论文作者:
姜佳伟(共一),韩程凯(共一),赵鑫教授,王静远教授
通讯作者:
王静远教授
作者单位:
北京航空航天大学,中国人民大学
课题组:
北航智慧城市课题组 BIGSCity(https://www.bigscity.com/)
一、 问题
1.Dynamic动态
2.Long-range长距离
3.Time Delay传播时间延迟感知
二、创新点
- Spatial Self-Attention(SSA) :捕获动态空间依赖关系
- Delay-aware Feature Transformation(DFT):捕获短期历史数据的传播时延
- Temporal Self-Attention(TSA):捕获动态的、长程的时间模式
三、模型结构
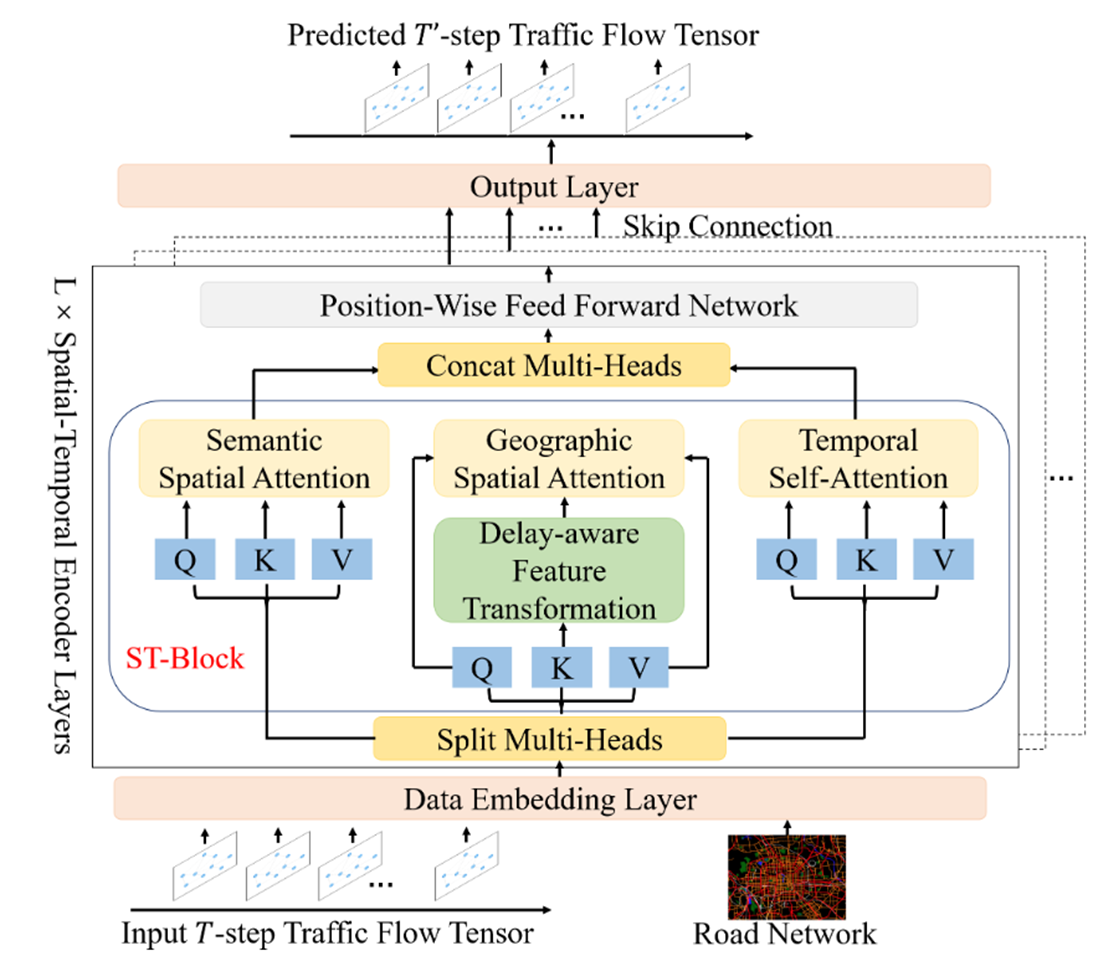
1. 模型输入
Data Embedding Layer:5个部分
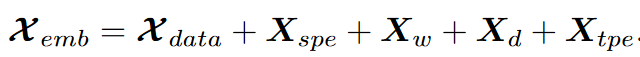
-
Weekly and Daily Periodicity
- w ( t ) : ( 1 t o 7 ) 7 d a y s = 1 w e e k w(t):(1 to 7)7days=1week w(t):(1to7)7days=1week
- d ( t ) : ( 1 t o 1440 ) 1440 m i n s = 24 h d(t):(1 to 1440) 1440mins=24h d(t):(1to1440)1440mins=24h
🟠: DataEmbedding
if self.add_time_in_day:
self.minute_size = 1440 # 一天是1440分钟(24小时)
self.daytime_embedding = nn.Embedding(self.minute_size, embed_dim)
if self.add_day_in_week:
weekday_size = 7
self.weekday_embedding = nn.Embedding(weekday_size, embed_dim)
- Temporal Position Encoding(经典的sin,cos)
🟠: PositionalEncoding
class PositionalEncoding(nn.Module):
def __init__(self, embed_dim, max_len=100):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, embed_dim).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, embed_dim, 2).float() * -(math.log(10000.0) / embed_dim)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)].unsqueeze(2).expand_as(x).detach()
🟡code:libcity/model/traffic_flow_prediction/PDFormer.py
🟠: DataEmbedding
def forward(self, x, lap_mx):
origin_x = x
x = self.value_embedding(origin_x[:, :, :, :self.feature_dim])
x += self.position_encoding(x)
if self.add_time_in_day:
x += self.daytime_embedding((origin_x[:, :, :, self.feature_dim] * self.minute_size).round().long())
if self.add_day_in_week:
x += self.weekday_embedding(origin_x[:, :, :, self.feature_dim + 1: self.feature_dim + 8].argmax(dim=3))
x += self.spatial_embedding(lap_mx)
x = self.dropout(x)
return x
2. 时空编码层
时空编码层主要包含三部分:
-
Self-Attention (SSA)
第一个是空间自注意模块,由地理空间自注意模块和语义空间自注意模块组成,同时捕捉短程和长程动态空间依赖。
-
Delay-aware Feature Transformation (DFT)
第二个是延迟感知特征转换模块,它扩展了地理空间自注意模块,以显式建模空间信息传播中的时间延迟。
-
Temporal Self-Attention (TSA)
第三个是时间自注意模块,捕捉动态和长期的时间模式。
a. SSA 空间自注意

如果计算所有节点的注意力,相当于将空间图视为全连通图,但实际上是只有附近的节点对和距离较远但功能相似的节点对之间的注意力交互才是必要的
在注意力计算中加入两种掩码
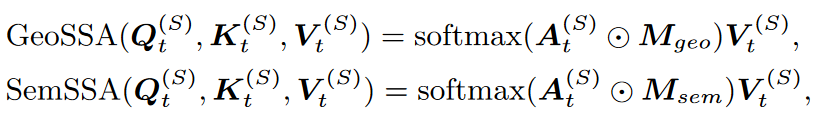
• geographic masking matrix
M
g
e
o
M_{geo}
Mgeo :根据距离的远近,设置阈值λ
• semantic masking matrix
M
s
e
m
M_{sem}
Msem : 使DTW算法计算不同位置节点相似度, 前K个相似度最高的节点作为其语义邻居
b. DFT 延迟感知
相似的交通模式可能对邻近交通状况产生相似的影响,尤其是拥堵等异常交通模式。
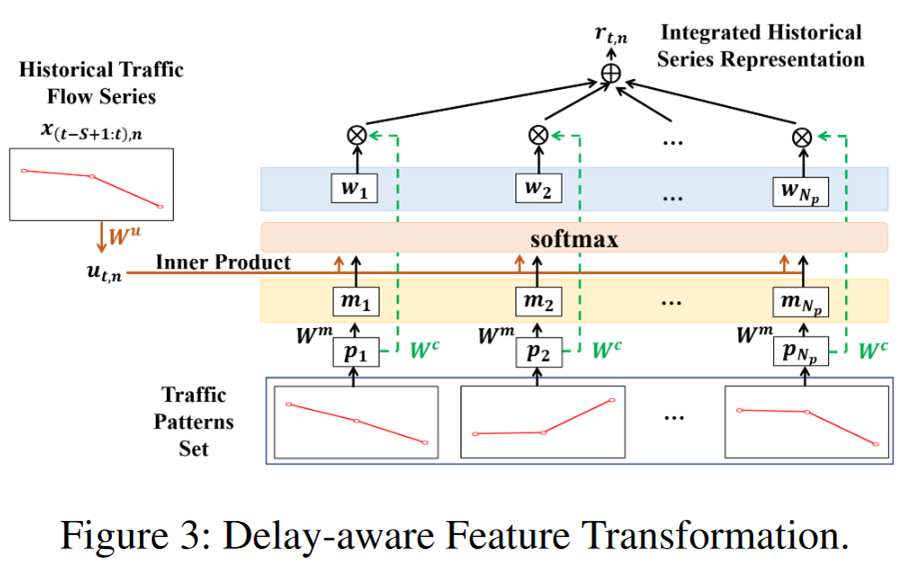
将每个节点的历史交通流序列与提取的交通模式集(聚类簇)进行比较,以将相似模式的信息融合到每个节点的历史交通流序列表示中:
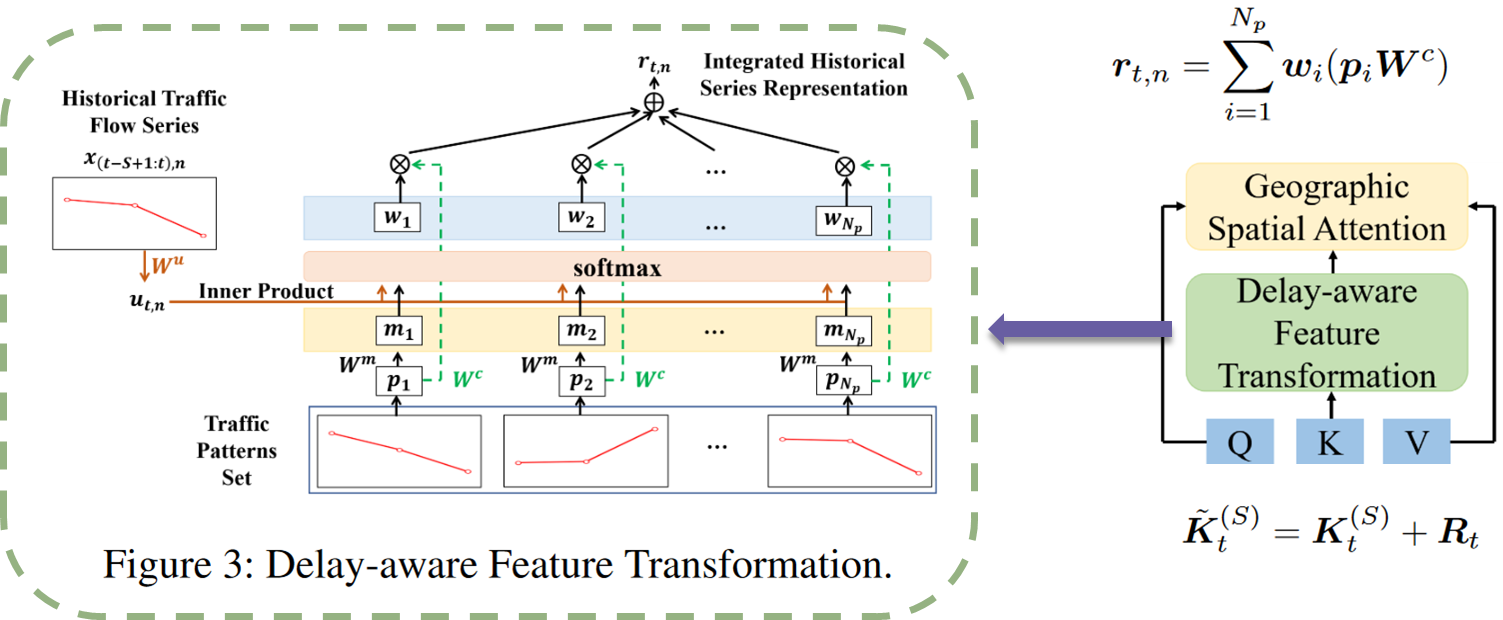
使用k-shape聚类 得到一个具有代表性的交通模式集,在训练过程中通过将每次训练序列与聚类结果计算。
DFT模块计算出的结果添加到Geo_SSA中的K中,没有将这个模块添加到语义空间自注意模块中,因为远处节点的短期交通流量对当前节点的影响很小。
geo_mask + sem_mask + DFT
🟡: PDFormer.py
# 空间自注意力模块
if self.type_short_path == "dist":
distances = sd_mx[~np.isinf(sd_mx)].flatten()
std = distances.std()
sd_mx = np.exp(-np.square(sd_mx / std))
self.far_mask = torch.zeros(self.num_nodes, self.num_nodes).to(self.device)
self.far_mask[sd_mx < self.far_mask_delta] = 1
self.far_mask = self.far_mask.bool()
else:
sh_mx = sh_mx.T
# geo_mask: 地理注意力
self.geo_mask = torch.zeros(self.num_nodes, self.num_nodes).to(self.device)
self.geo_mask[sh_mx >= self.far_mask_delta] = 1
self.geo_mask = self.geo_mask.bool()
# sem_mask: 语义注意力
self.sem_mask = torch.ones(self.num_nodes, self.num_nodes).to(self.device)
# dtw 计算相似度
sem_mask = self.dtw_matrix.argsort(axis=1)[:, :self.dtw_delta]
for i in range(self.sem_mask.shape[0]):
self.sem_mask[i][sem_mask[i]] = 0
self.sem_mask = self.sem_mask.bool()
# k-shape聚类的结果
self.pattern_keys = torch.from_numpy(data_feature.get('pattern_keys')).float().to(self.device)
self.pattern_embeddings = nn.ModuleList([
TokenEmbedding(self.s_attn_size, self.embed_dim) for _ in range(self.output_dim)
])
🟣pdformer_dataset.py (libcity/data/dataset/pdformer_dataset.py)
🔵sh_mx的计算
def _load_rel(self):
self.sd_mx = None
super()._load_rel()
self._logger.info('Max adj_mx value = {}'.format(self.adj_mx.max()))
# sh_mx: shortest hop matrix
self.sh_mx = self.adj_mx.copy()
# 'hop' 可能表示跳数或者跳跃次数
if self.type_short_path == 'hop':
self.sh_mx[self.sh_mx > 0] = 1
self.sh_mx[self.sh_mx == 0] = 511
for i in range(self.num_nodes):
self.sh_mx[i, i] = 0
# 以下部分是 Floyd-Warshall 算法的实现
for k in range(self.num_nodes):
for i in range(self.num_nodes):
for j in range(self.num_nodes):
self.sh_mx[i, j] = min(self.sh_mx[i, j], self.sh_mx[i, k] + self.sh_mx[k, j], 511)
'''
这行代码是 Floyd-Warshall 算法的核心部分。
它的作用是更新从顶点 i 到顶点 j 的最短路径长度,
通过比较当前的最短路径长度 self.sh_mx[i, j] 和
经过顶点 k 的路径长度之和 self.sh_mx[i, k] + self.sh_mx[k, j],
取二者的较小值作为新的最短路径长度。
同时,限制最短路径长度不超过 511。
'''
np.save('{}.npy'.format(self.dataset), self.sh_mx)
🔵sd_mx的计算
def _calculate_adjacency_matrix(self):
self._logger.info("Start Calculate the weight by Gauss kernel!")
# sd_mx: shortest dist matrix
self.sd_mx = self.adj_mx.copy()
# 用高斯核函数计算权重
distances = self.adj_mx[~np.isinf(self.adj_mx)].flatten()
std = distances.std()
self.adj_mx = np.exp(-np.square(self.adj_mx / std))
# 根据权重调整邻接矩阵
self.adj_mx[self.adj_mx < self.weight_adj_epsilon] = 0
# 'dist' 可能表示距离或者路径长度
if self.type_short_path == 'dist':
self.sd_mx[self.adj_mx == 0] = np.inf
# 以下部分是 Floyd-Warshall 算法的实现
for k in range(self.num_nodes):
for i in range(self.num_nodes):
for j in range(self.num_nodes):
self.sd_mx[i, j] = min(self.sd_mx[i, j], self.sd_mx[i, k] + self.sd_mx[k, j])
dtw和k-shape计算
from fastdtw import fastdtw
from tslearn.clustering import TimeSeriesKMeans, KShape
🟢function: get_dtw:
dtw时间规整计算相似度
if not os.path.exists(cache_path):
data_mean = np.mean(
[df[24 * self.points_per_hour * i: 24 * self.points_per_hour * (i + 1)]
for i in range(df.shape[0] // (24 * self.points_per_hour))], axis=0)
dtw_distance = np.zeros((self.num_nodes, self.num_nodes))
for i in tqdm(range(self.num_nodes)):
for j in range(i, self.num_nodes):
# fastdtw计算相似度:得到语义邻居
dtw_distance[i][j], _ = fastdtw(data_mean[:, i, :], data_mean[:, j, :], radius=6)
for i in range(self.num_nodes):
for j in range(i):
dtw_distance[i][j] = dtw_distance[j][i]
np.save(cache_path, dtw_distance)
dtw_matrix = np.load(cache_path)
🟢function :get_data
k-shape聚类计算:
if not os.path.exists(self.pattern_key_file + '.npy'):
cand_key_time_steps = self.cand_key_days * self.points_per_day
pattern_cand_keys = x_train[:cand_key_time_steps, :self.s_attn_size, :, :self.output_dim].swapaxes(1, 2).reshape(-1, self.s_attn_size, self.output_dim)
self._logger.info("Clustering...")
if self.cluster_method == "kshape":
km = KShape(n_clusters=self.n_cluster, max_iter=self.cluster_max_iter).fit(pattern_cand_keys)
else:
km = TimeSeriesKMeans(n_clusters=self.n_cluster, metric="softdtw", max_iter=self.cluster_max_iter).fit(pattern_cand_keys)
self.pattern_keys = km.cluster_centers_
np.save(self.pattern_key_file, self.pattern_keys)
时空编码层
🟢STEncoderBlock
def forward(self, x, x_patterns, pattern_keys, geo_mask=None, sem_mask=None):
if self.type_ln == 'pre':
# 时空注意力编码层
x = x + self.drop_path(self.st_attn(self.norm1(x), x_patterns, pattern_keys, geo_mask=geo_mask, sem_mask=sem_mask))
x = x + self.drop_path(self.mlp(self.norm2(x)))
elif self.type_ln == 'post':
x = self.norm1(x + self.drop_path(self.st_attn(x, x_patterns, pattern_keys, geo_mask=geo_mask, sem_mask=sem_mask)))
x = self.norm2(x + self.drop_path(self.mlp(x)))
return x
掩码设计 drop_path
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
c. TSA 时间自注意力
🟡: PDFormer.py
class: TemporalSelfAttention
四、运行调试
run
python run_model.py --task traffic_state_pred --model PDFormer --dataset PeMS08 --config_file PeMS08 --train false --exp_id $ID
python run_model.py --task traffic_state_pred --model PDFormer --dataset PeMS04 --config_file PeMS04
python run_model.py --task traffic_state_pred --model PDFormer --dataset PeMS08 --config_file PeMS08
python run_model.py --task traffic_state_pred --model PDFormer --dataset PeMS07 --config_file PeMS07
python run_model.py --task traffic_state_pred --model PDFormer --dataset NYCTaxi --config_file NYCTaxi --evaluator TrafficStateGridEvaluator
python run_model.py --task traffic_state_pred --model PDFormer --dataset CHIBike --config_file CHIBike --evaluator TrafficStateGridEvaluator
python run_model.py --task traffic_state_pred --model PDFormer --dataset T-Drive --config_file T-Drive --evaluator TrafficStateGridEvaluator
本地运行报错:
TypeError: ufunc ‘isnan’ not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting rule ‘‘safe’’
完整版:
Traceback (most recent call last):
File “run_model.py”, line 54, in
train=args.train, other_args=other_args)
File “G:\我的云端硬盘\Models\PDFormer-master\libcity\pipeline\pipeline.py”, line 39, in run_model train_data, valid_data, test_data = dataset.get_data()
File “G:\我的云端硬盘\Models\PDFormer-master\libcity\data\dataset\pdformer_dataset.py”, line 86, in get_data
x_train, y_train, x_val, y_val, x_test, y_test = self._generate_train_val_test()
File “G:\我的云端硬盘\Models\PDFormer-master\libcity\data\dataset\traffic_state_datatset.py”, line 585, in _generate_train_val_test
x, y = self._generate_data()
File “G:\我的云端硬盘\Models\PDFormer-master\libcity\data\dataset\traffic_state_datatset.py”, line 546, in _generate_data
df = self._add_external_information(df, ext_data)
File “G:\我的云端硬盘\Models\PDFormer-master\libcity\data\dataset\traffic_state_point_dataset.py”, line 23, in _add_external_information
return super()._add_external_information_3d(df, ext_data)
File “G:\我的云端硬盘\Models\PDFormer-master\libcity\data\dataset\traffic_state_datatset.py”, line 407, in _add_external_information_3d
is_time_nan = np.isnan(self.timesolts).any()
TypeError: ufunc ‘isnan’ not supported for the input types, and the inputs could not be safely coerced to any supported types according to the casting r
ule ‘‘safe’’
报错:数据处理问题
is_time_nan:时间出现空值
🐱: 版本问题,先调整了colab的Pdformer 中numpy的版本,和已测试的本地numpy同步
numpy 换成了19.4版本,is_nan消失了
新的报错
python run_model.py --task traffic_state_pred --model PDFormer --dataset PeMS04 --config_file PeMS04
MemoryError: Unable to allocate 259. KiB for an array with shape (12, 307, 9) and data type float64
🐱: cpu干爆了
ERROR 1 : cuda
-
colab报错:
ImportError: C extension: numpy.core.multiarray failed to import not built. If you want to import pandas from the source directory, you may need to run ‘python setup.py build_ext --inplace --force’ to build the C extensions first.
解决AttributeError: module ‘torch._C’ has no attribute ‘_cuda_setDevice’
问题分析:
pip install requirements 里面安装的pytorch版本是默认的CPU版本,导致没有cuda
首先查看本地cuda版本:11.0
到Pytorch官网,找到previous version里面,cuda 11.0对应的pytorch安装命令
# CUDA 11.0
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 cudatoolkit=11.0 -c pytorch
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 451.67 Driver Version: 451.67 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce 940MX WDDM | 00000000:01:00.0 Off | N/A |
| N/A 58C P8 N/A / N/A | 255MiB / 2048MiB | 34% Default |
+-------------------------------+----------------------+----------------------+
Successfully installed torch-1.7.1+cu110 torchaudio-0.7.2 torchvision-0.8.2+cu110
ERROR 2: ray.suggest
No module named 'ray.tune.suggest'
Traceback (most recent call last): File "/content/drive/MyDrive/Models/PDFormer-master/run_model.py", line 4, in from libcity.pipeline import run_model File "/content/drive/MyDrive/Models/PDFormer-master/libcity/pipeline/__init__.py", line 1, in from libcity.pipeline.pipeline import run_model, hyper_parameter, finetune, objective_function File "/content/drive/MyDrive/Models/PDFormer-master/libcity/pipeline/pipeline.py", line 3, in from ray.tune.suggest .hyperopt import HyperOptSearch ModuleNotFoundError: No module named 'ray.tune.suggest'
🐱: 这一切的一切都是环境的问题,包版本没有配好!
ray.tune.suggest模块是 Ray Tune 中用于超参数优化的模块,它在 Ray Tune 1.6.0 版本中发生了变化。在该版本之前(例如 Ray Tune 1.5.0),
ray.tune.suggest模块被拆分成了多个子模块,因此无法直接使用ray.tune.suggest。相反,你需要根据使用的优化算法选择相应的模块,例如:
- 例如,对于基于贝叶斯优化的算法(例如 HyperOpt 和 Nevergrad),你需要导入
ray.tune.suggest.hyperopt或ray.tune.suggest.nevergrad。- 对于随机搜索算法,你可以导入
ray.tune.suggest.basic。如果你正在使用较新版本的 Ray Tune,请确保使用该版本的文档和示例代码来查看有关
ray.tune.suggest模块的详细信息和用法。
🐱:意思是ray1.5.0版本才有suggest, 同样的,在本地使用的也是ray==1.4.1<1.6.0,没有报错
然而,在colab安装ray1.5.0显示
ERROR: Could not find a version that satisfies the requirement ray==1.5.0 (from versions: 1.13.0, 2.0.0rc0, 2.0.0rc1, 2.0.0, 2.0.1, 2.1.0, 2.2.0, 2.3.0rc0, 2.3.0, 2.3.1, 2.4.0, 2.5.0, 2.5.1, 2.6.0, 2.6.1, 2.6.2) ERROR: No matching distribution found for ray==1.5.0
try:
把suggest改成search
/content/drive/MyDrive/Models/PDFormer-master/libcity/pipeline/pipeline.py
from ray import tune
from ray.tune.search .hyperopt import HyperOptSearch
from ray.tune.search .bayesopt import BayesOptSearch
from ray.tune.search .basic_variant import BasicVariantGenerator
from ray.tune.schedulers import FIFOScheduler, ASHAScheduler, MedianStoppingRule
from ray.tune.search import ConcurrencyLimiter
🐱: 成功解决
ERROR 3: ^C
colab内存不足
如果在 Google Colab 中运行代码时出现
^C,这表示你的代码正在运行一个被中断的操作。这通常发生在代码块执行时间过长或资源占用过高时。一种常见的情况是,在代码中使用了无限循环或耗时较长的操作,导致 Colab 在等待时超过了预设的超时时间。
要解决这个问题,你可以尝试以下几种方法:
- 检查代码:检查你的代码是否存在死循环,或者某些部分可能会导致长时间的执行。
- 优化代码:如果你的代码运行时间较长,可以尝试进行代码优化以提高执行效率。
- 减少输入数据规模:如果你正在处理大量的数据,可以减少输入数据的规模,以缩短代码的执行时间。
- 手动停止执行:如果代码已经在执行并且你希望手动停止它,可以按住
Ctrl + M并同时按下I键两次(按下两次 “I”,不是 “L”),这将中断代码的执行。如果以上方法仍然无法解决问题,你可以尝试重启 Colab 运行时,或者考虑使用其他方法来执行你的代码,例如在本地的 Jupyter Notebook 或其他 Python 环境中运行。
请注意,如果是因为代码运行时间太长而导致的超时,你可能需要重新评估代码的逻辑和效率,以确保在合理的时间范围内完成运行。
try:
config下面所有json配置文件的batch size
batch: 2
🐱:还是不行
换了3090 24G
batch_size调到16运行成功了
log
- INFO - {
- 'task': 'traffic_state_pred',
- 'model': 'PDFormer',
- 'dataset': 'PeMS08',
- 'saved_model': True,
- 'train': True,
- 'local_rank': 0,
- 'initial_ckpt': None,
- 'dataset_class': 'PDFormerDataset',
- 'input_window': 12,
- 'output_window': 12,
- 'train_rate': 0.6,
- 'eval_rate': 0.2,
- 'batch_size': 16,
- 'add_time_in_day': True,
- 'add_day_in_week': True,
- 'step_size': 2776,
- 'max_epoch': 200,
- 'bidir': True,
- 'num_workers': 0,
- 'pad_with_last_sample': True,
- 'lape_dim': 8,
- 'gpu': True,
- 'gpu_id': 3,
}
PDformer 跑代码参数修改
- epoch 、batch size
项目一级目录下对应的几个以数据集名称命名的json文件对应“max_epoch”字段和"batch_size"字段PEMS07 epoch 200 batch size : 4时, 在3090 24G上调试,GPU占用大小约1G
Libcity运行时参数修改
-
改batch_size, 6:2:2 ratio
Bigscity-LibCity/libcity/config/data/TrafficStatePointDataset.json
-
改max_epoch, learning_rate
在具体模型的.json文件里面
Bigscity-LibCity/libcity/config/model/traffic_state_pred/STGCN.json
-
改gpu_id
Bigscity-LibCity/libcity/config/executor/TrafficStateExecutor.json
Libcity和PDFormer结果差别很大的问题(12.4)
ref: https://github.com/BUAABIGSCity/PDFormer/issues/16
- 在issues里面找到了问题原因所在,是数据集的特征数量不一致
- 同时还指出来两个项目里数据集划分的比例也不一致
🐱: MAPE结果是inf不用看,看masked_MAPE
五、网上评论
Ref: https://zhuanlan.zhihu.com/p/601361695
- sem_mask的kshape聚类
Delay-aware Feature Transformation应该是文章一个很重要的创新点,其中pattern keys具体的实现过程在代码中有吗?
“首先从历史交通数据中识别出一组具有代表性的短期交通模式。”这样的操作不会带来数据泄漏吗?
ablation study中可以明显看出 spatial attention内的两个mask去除以后效果大幅下降,效果劣于大部分较新baselines,geo mask与DCRNN等文章类似,请问sem mask的计算代码在github中有给出吗?
接上个问题,是否说明这种mask的方式才是模型准确的核心,而不是delay-aware methods?
作者在issue里回应了信息泄露的问题,说是对结果没有影响。 不过PDFormer的节结果比论文报告里差多了,我对04和08两个数据集都跑了10次,基本上没几次结果能达到论文里报告的结果,还说这是十次的平均结果
我最近也在研究PDFormer,尝试把masked attention抠出来单独运行,发现mask带来的改进不大,特别是geo_mask是副作用,sem_mask有一些提升,但是不像文中的消融实验那样显得mask极其重要。我不懂PDFormer性能这么好的原因在哪里,delay模块在我看来就是一个凑创新点的东西。
- 数据集
有人知道为什么近两年的paper普遍不喜欢用PEMS03数据集吗 基本都只用04 07 08这三个?
因为这个数据集Graph WaveNet太强了,基本没有模型能刷过它,干脆不做这个数据集的实验。
- data embedding
我调试了PeMS04数据集,输入维度也是9。作者在 libcity/data/dataset/traffic_state_point_dataset.py 这个文件中的_add_external_information方法里加了额外的时间信息,一共加了8个维度,一个是time_in_day(1维,但计算过程没太明白),还有一个是add_day_in_week(7维,就是one-hot编码)
一维那个是用nn.embedding 做的,可以去看看torch的文档,有解释。大意就是one-hot 维度太大,转化为embedding就可以实现低维表示,这在NLP很常见,一般是通过这种方式来编码单词

















 924
924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









