







原文:
http://blog.csdn.net/hujingshuang/article/details/47060677
简介
FREAK算法是2012年CVPR上《FREAK: Fast Retina Keypoint》文章中,提出来的一种特征提取算法,也是一种二进制的特征描述算子。
它与BRISK算法非常相似,个人觉得就是在BRISK算法上的改进,关于BRISK算法详见上一篇博文:BRISK特征提取算法。FREAK依然具有尺度不变性、旋转不变性、对噪声的鲁棒性等。
FREAK算法
采样模式
在BRISK算法中,采样模式是均匀采样模式(在同一圆上等间隔的进行采样);FREAK算法中,采样模式发生了改变,它采取了更为接近于人眼视网膜接收图像信息的采样模型。图中展示了人眼视网膜拓扑结构,Fovea区域主要是对高进度的图像信息进行处理,Para主要是对低精度的图像信息进行处理。采样点为:6、6、6、6、6、6、6、1,那个1是特征点。
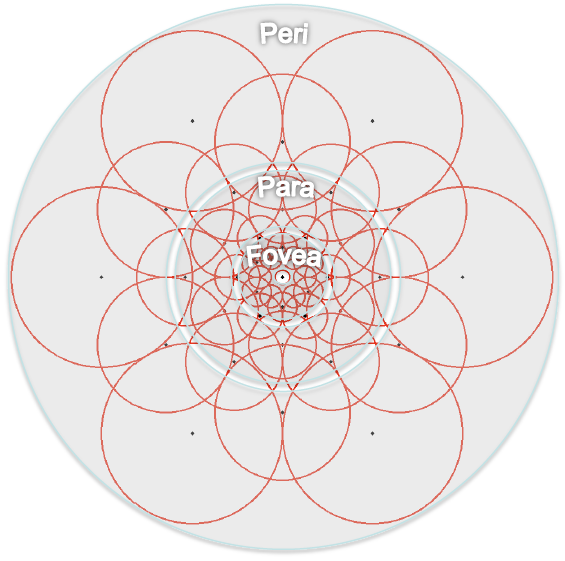
从图中可以看出,该结构是由很多大小不同并有重叠的圆构成,最中心的点是特征点,其它圆心是采样点,采样点离特征点的距离越远,采样点圆的半径越大,也表示该圆内的高斯函数半径越大
特征描述
F表示二进制描述子,Pa是采样点对(与BRISK同理),N表示期望的二进制编码长度。
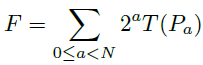
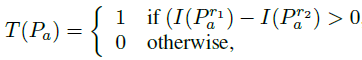
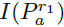
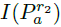
当然得到特征点的二进制描述符后,也就算完成了特征提取。但是FREAK还提出,将得到的Nbit二进制描述子进行筛选,希望得到更好的,更具有辨识度的描述子,也就是说要从中去粗取精。(也就是降维)
1、建立矩阵D,D的每一行是一个FREAK二进制描述符,即每一行有N个元素;在上图的采样模式中公有43个采样点,可以产生N=43*(43-1)/2=903个采样点对,也就是说矩阵D有903行列(修改于:2015-11-15);
2、对矩阵D的每一列计算其均值,由于D中元素都是0/1分布的,均值在0.5附近说明该列具有高的方差;
3、每一列都有一个均值,以均值最接近0.5的排在第一位,均值离0.5越远的排在越靠后,对列进行排序;
4、选取前512列作为最终的二进制描述符。(也可以是256、128、64、32等)
小结:最原始的二进制长度为903,当然这包含了许多冗余或粗糙的信息,所以根据一定的方法取N个二进制长度,方法是建立矩阵D。假如提取到228个特征点,那么矩阵D应该是228行*903列,然后经过计算均值,将每个列重新排序,选取前N列,这个矩阵D就是228*N的矩阵了。当然这个N我在文中写得是512,你也可以是256、128、64、32这些都是可以的。 最终D的每一行仍然是一个特征点的描述符,只是更短小精悍而已,即降低了维度。(添加于:2016-01-11)
由于FREAK描述符自身的圆形对称采样结构使其具有旋转不变性,采样的位置好半径随着尺度的变化使其具有尺度不变性,对每个采样点进行高斯模糊,也具有一定的抗噪性能,像素点的强度对比生成二进制描述子使其具有光照不变性。因此由上述产生的二进制描述子可以用来进行特征匹配。在匹配之前,再补充一下特征点的方向信息。
特征方向
由于特征点周围有43个采样点,可产生43*(43-1)/2=903个采样点对,FREAK算法选取其中45个长的、对称的采样点对来提取特征点的方向,采样点对如下:
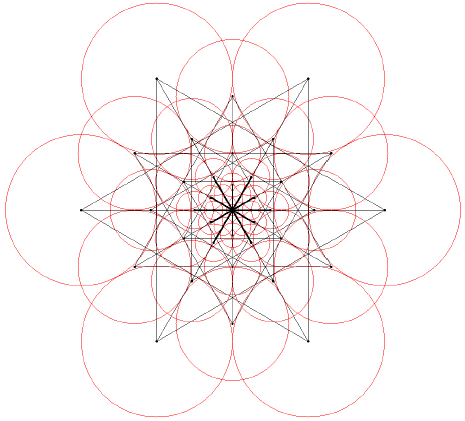
用O表示局部梯度信息,M表示采样点对个数,G表示采样点对集合,Po表示采样点对的位置,则:
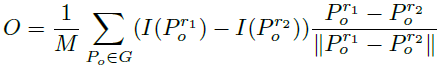
同BRISK算法,可得到特征点的方向。
特征匹配
在特征描述中,我们得到了512bit的二进制描述符,该描述符的列是高方差——>低方差的排列,而高方差表征了模糊信息,低方差表征了细节信息,与人眼视网膜相似,人眼先处理的是模糊信息,再处理细节信息。因此,选取前128bit即16bytes进行匹配(异或),若两个待匹配的特征点前16bytes距离小于设定的阈值,则再用剩余的位信息进行匹配。这种方法可以剔除掉90%的不相关匹配点。注意:这里的16bytes的选取是建立在并行处理技术(SIMD)上的,并行处理技术处理16bytes与处理1bytes的时间相同;也就是说,16bytes并不是固定的,如果你的并行处理技术能处理32bytes与处理1bytes的时间相同的话,那么你也可以选取前32bytes。
#include <opencv2/core/core.hpp>
#include <opencv2/features2d/features2d.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/nonfree/features2d.hpp>
#include <opencv2/legacy/legacy.hpp>
#include <iostream>
#include <vector>
using namespace cv;
using namespace std;
int main(void)
{
string filename1 = "beaver1.png";
string filename2 = "beaver2.png";
// FREAK
Mat imgA_Freak = imread(filename1);
Mat imgB_Freak = imread(filename2);
vector<KeyPoint> keypointsA_Freak, keypointsB_Freak;
Mat descriptorsA_Freak, descriptorsB_Freak;
vector<DMatch> matches_Freak;
// DETECTION
// Any openCV detector such as
SurfFeatureDetector detector_Freak(200, 4);
// DESCRIPTOR
// Our proposed FREAK descriptor
// (roation invariance, scale invariance, pattern radius corresponding to SMALLEST_KP_SIZE,
// number of octaves, optional vector containing the selected pairs)
// FREAK extractor(true, true, 22, 4, std::vector<int>());
FREAK freak;
// MATCHER
// The standard Hamming distance can be used such as
// BruteForceMatcher<Hamming> matcher;
// or the proposed cascade of hamming distance using SSSE3
BruteForceMatcher<HammingLUT> matcher_Freak;
// detect
double t = (double)getTickCount();
detector_Freak.detect(imgA_Freak, keypointsA_Freak);
detector_Freak.detect(imgB_Freak, keypointsB_Freak);
t = ((double)getTickCount() - t)/getTickFrequency();
cout << "FREAK detection time [s]: " << t/1.0 << endl;
// extract
t = (double)getTickCount();
freak.compute(imgA_Freak, keypointsA_Freak, descriptorsA_Freak);
freak.compute(imgB_Freak, keypointsB_Freak, descriptorsB_Freak);
t = ((double)getTickCount() - t)/getTickFrequency();
cout << "FREAK extraction time [s]: " << t << endl;
// match
// t = (double)getTickCount();
matcher_Freak.match(descriptorsA_Freak, descriptorsB_Freak, matches_Freak);
// t = ((double)getTickCount() - t)/getTickFrequency();
// std::cout << "matching time [s]: " << t << std::endl;
double max_dist = 0;
double min_dist = 100;
//-- Quick calculation of max and min distances between keypoints
for (int i=0; i<descriptorsA_Freak.rows; i++)
{
double dist = matches_Freak[i].distance;
if (dist < min_dist) min_dist = dist;
if(dist > max_dist) max_dist = dist;
}
printf("-- Max dist : %f \n", max_dist);
printf("-- Min dist : %f \n", min_dist);
//-- Draw only "good" matches (i.e. whose distance is less than 0.7*max_dist )
//-- PS.- radiusMatch can also be used here.
vector<DMatch> good_matches_Freak;
for (int i=0; i<descriptorsA_Freak.rows; i++)
{
if(matches_Freak[i].distance < 0.7*max_dist)
{
good_matches_Freak.push_back(matches_Freak[i]);
}
}
// Draw matches
Mat imgMatch_Freak;
drawMatches(imgA_Freak, keypointsA_Freak, imgB_Freak, keypointsB_Freak, good_matches_Freak, imgMatch_Freak,
Scalar::all(-1), Scalar::all(-1),
vector<char>(), DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
// display
imshow("matchFREAK", imgMatch_Freak);
waitKey(0);
return 0;
}














 3504
3504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









