











1.关于自然语言处理NLP
自然语言处理NLP是人工智能和计算机科学的一个子领域,专注于计算机与人类(自然)语言之间的互动。其目的是使计算机能够理解、解释和生成人类语言。NLP 涉及语言学、计算机科学和人工智能的多学科交叉,通过统计、机器学习和深度学习等方法处理和分析大量的自然语言数据。
核心任务和应用
NLP 包括多种任务和应用,主要分为以下几类:
1. 文本处理
-
分词:将文本分割成独立的单词或短语。
-
词性标注:标识每个单词在句子中的词性(如名词、动词、形容词等)。
-
句法分析:解析句子的语法结构,包括依存关系和短语结构分析。
2. 文本分类
-
情感分析:检测文本中的情感倾向,如积极、中立或消极。
-
主题建模:识别文本中的主题或隐藏的语义结构。
-
垃圾邮件过滤:检测并过滤电子邮件中的垃圾内容。
3. 信息提取
-
命名实体识别(NER):识别文本中的实体,如人名、地名、组织等。
-
关系抽取:从文本中提取实体之间的关系。
-
事件抽取:识别和分类文本中的事件信息。
4. 机器翻译
-
自动翻译:将文本从一种语言翻译成另一种语言,如 Google 翻译。
5. 文本生成
-
语言生成:生成与输入语义相关的自然语言文本。
-
摘要生成:从长文本中提取关键内容生成摘要。
6. 对话系统
-
聊天机器人:与用户进行自然语言对话,如客服机器人。
-
智能助理:提供信息查询、任务管理等服务,如 Siri、Alexa。
主要技术和方法
1. 统计方法
早期的 NLP 方法主要依赖于统计模型,如 n-gram 模型、隐马尔可夫模型(HMM)和条件随机场(CRF),用于各种语言处理任务。
2. 机器学习
传统机器学习方法,如支持向量机(SVM)、朴素贝叶斯、决策树等被广泛应用于文本分类、情感分析等任务。
3. 深度学习
近年来,深度学习技术在 NLP 中取得了显著进展,主要包括:
-
循环神经网络(RNN):特别是长短期记忆(LSTM)和门控循环单元(GRU)被用于处理序列数据,如文本生成和机器翻译。
-
卷积神经网络(CNN):用于文本分类和句子建模。
-
Transformer:由 Google 提出的 Transformer 结构及其衍生模型(如 BERT、GPT)在多种 NLP 任务中表现优异。
工具和库
-
NLTK:Python 的自然语言处理库,提供丰富的工具和资源。
-
spaCy:高效的 NLP 库,适用于工业应用。
-
Gensim:用于主题建模和文档相似性计算的库。
-
Transformers:Hugging Face 提供的库,包含多种预训练模型,如 BERT、GPT 等。
2.NTLK库
NLTK(Natural Language Toolkit)是一个广泛使用的开源 Python 库,专门用于处理自然语言文本。它提供了丰富的工具和资源,用于完成各种自然语言处理(NLP)任务,包括文本预处理、词性标注、句法分析、语义分析、机器翻译等。NLTK 适用于教育和研究领域,同时也是入门 NLP 的理想工具。
核心组件和功能
NLTK 包含多个模块和子包,提供了各种 NLP 功能。以下是一些核心组件和功能:
1. 文本预处理
-
分词(Tokenization):将文本分割成独立的单词或句子。
# 导入 NLTK 库 import nltk # 下载 punkt 数据包,用于分句和分词 nltk.download('punkt') # 定义一个句子 sentence = "Natural language processing is fun." # 使用 NLTK 的 word_tokenize 函数对句子进行分词 # word_tokenize 函数将输入的字符串按单词进行分割,生成一个单词列表 words = nltk.word_tokenize(sentence) # 打印分词后的结果 # 结果是一个包含句子中每个单词的列表 print(words) # 输出: ''' ['Natural', 'language', 'processing', 'is', 'fun', '.'] ''' -
去除停用词(Stopword Removal):去除无意义的常见词(如 "the", "is")。
# 从 NLTK 的语料库模块中导入 stopwords from nltk.corpus import stopwords # 下载 stopwords 数据包,包含各种语言的常见停用词 nltk.download('stopwords') # 获取英语的停用词集合 stop_words = set(stopwords.words('english')) # 过滤掉分词结果中的停用词 # 对于每个单词 w,如果该单词(转换为小写后)不在停用词集合中,则保留该单词 filtered_words = [w for w in words if not w.lower() in stop_words] # 打印过滤后的单词列表 # 结果是一个去除了停用词的单词列表 print(filtered_words) # 输出: ''' ['Natural', 'language', 'processing', 'fun', '.'] ''' -
词干提取(Stemming):将单词还原为词干形式。
# 从 NLTK 的 stem 模块中导入 PorterStemmer from nltk.stem import PorterStemmer # 初始化 PorterStemmer 对象 stemmer = PorterStemmer() # 对分词结果中的每个单词进行词干提取 # stemmer.stem(w) 方法会提取单词的词干 stemmed_words = [stemmer.stem(w) for w in words] # 打印词干提取后的单词列表 # 结果是一个包含每个单词词干形式的列表 print(stemmed_words) # 输出: ''' ['natur', 'languag', 'process', 'is', 'fun', '.'] ''' -
词形还原(Lemmatization):将单词还原为其基本形式。
# 从 NLTK 的 stem 模块中导入 WordNetLemmatizer from nltk.stem import WordNetLemmatizer # 下载 wordnet 数据包,包含用于词形还原的词典 nltk.download('wordnet') # 初始化 WordNetLemmatizer 对象 lemmatizer = WordNetLemmatizer() # 对分词结果中的每个单词进行词形还原 # lemmatizer.lemmatize(w) 方法会将单词还原为其基本形式 lemmatized_words = [lemmatizer.lemmatize(w) for w in words] # 打印词形还原后的单词列表 # 结果是一个包含每个单词基本形式的列表 print(lemmatized_words) # 输出: ''' ['Natural', 'language', 'processing', 'is', 'fun', '.'] '''
2. 词性标注(Part-of-Speech Tagging)
-
标注句子中的每个单词的词性:
# 下载词性标注器的模型数据包 nltk.download('averaged_perceptron_tagger') # 对分词结果进行词性标注 # nltk.pos_tag(words) 方法会为每个单词分配词性标签 tagged_words = nltk.pos_tag(words) # 打印词性标注后的单词列表 # 结果是一个包含单词及其词性标签的元组列表 print(tagged_words) # 输出: ''' [('Natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('is', 'VBZ'), ('fun', 'NN'), ('.', '.')] '''
3. 命名实体识别(Named Entity Recognition)
-
识别句子中的命名实体:
# 下载用于命名实体识别的模型数据包 nltk.download('maxent_ne_chunker') # 下载 words 数据包,包含用于命名实体识别的词典 nltk.download('words') # 使用词性标注后的单词列表进行命名实体识别 # nltk.chunk.ne_chunk(tagged_words) 方法会识别句子中的命名实体 entities = nltk.chunk.ne_chunk(tagged_words) # 打印命名实体识别后的结果 # 结果是一个包含标记的命名实体的树结构 print(entities) # 输出: ''' (S Natural/JJ language/NN processing/NN is/VBZ fun/NN ./.) '''
4. 句法分析(Syntactic Parsing)
-
解析句子的语法结构:
# 从 NLTK 导入上下文无关文法(CFG)模块 from nltk import CFG # 定义上下文无关文法(CFG) grammar = CFG.fromstring(""" S -> NP VP # 句子 S 由名词短语 NP 和动词短语 VP 组成 VP -> V NP # 动词短语 VP 由动词 V 和名词短语 NP 组成 NP -> 'John' | 'Mary' | 'Bob' # 名词短语 NP 由三个名字中的一个组成 V -> 'loves' | 'hates' # 动词 V 包含 'loves' 和 'hates' """) # 使用定义的语法创建一个 ChartParser parser = nltk.ChartParser(grammar) # 将句子分词 sentence = "John loves Mary".split() # 使用解析器解析句子 for tree in parser.parse(sentence): # 打印解析得到的树结构 print(tree) # 输出: ''' (S (NP John) (VP (V loves) (NP Mary))) '''
5. 语料库和词典资源
-
NLTK 提供了丰富的语料库和词典资源,涵盖了各种语言和应用领域。主要语料库包括:Gutenberg Corpus(经典文学作品,如《白鲸》)、Brown Corpus(平衡的英语语料库)、Reuters Corpus(新闻文档)、Inaugural Address Corpus(美国总统就职演说)、Movie Reviews Corpus(影评文本)、Web Text Corpus(互联网文本)、Shakespeare Corpus(莎士比亚戏剧文本)和 Treebank Corpus(句法树和词性标注的文本)。主要词典资源包括:WordNet(大型英语词典数据库)、Names Corpus(常见男性和女性名字)、Stopwords Corpus(多种语言的停用词列表)、Swadesh Corpus(基本词汇列表)、CMU Pronouncing Dictionary(英语发音词典)和 Opinion Lexicon(正面和负面情感词汇列表)。这些资源为各种自然语言处理任务提供了基础数据支持。:
# 从 NLTK 的语料库模块中导入 gutenberg 语料库 from nltk.corpus import gutenberg # 下载 gutenberg 语料库 nltk.download('gutenberg') # 获取 'melville-moby_dick.txt' 文件的原始文本内容 sample = gutenberg.raw('melville-moby_dick.txt') # 打印前 500 个字符的文本内容 print(sample[:500]) # 输出是从 NLTK 的 Gutenberg 语料库中提取并打印了《白鲸》(Moby Dick)前 500 个字符的内容。: ''' [Moby Dick by Herman Melville 1851] ETYMOLOGY. (Supplied by a Late Consumptive Usher to a Grammar School) The pale Usher--threadbare in coat, heart, body, and brain; I see him now. He was ever dusting his old lexicons and grammars, with a queer handkerchief, mockingly embellished with all the gay flags of all the known nations of the world. He loved to dust his old grammars; it somehow mildly reminded him of his mortality. "While you take in hand to school others, and to teac '''
3.代码示例
①文本预处理和词性标注
以下是一个完整的示例,展示了如何使用 NLTK 进行文本预处理和词性标注:
import nltk
import re
from nltk.corpus import stopwords
from nltk.stem import PorterStemmer, WordNetLemmatizer
# 下载必要的 NLTK 数据包
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('averaged_perceptron_tagger')
nltk.download('wordnet')
# 加载文本
text = "NLTK is a leading platform for building Python programs to work with human language data."
# 分词
words = nltk.word_tokenize(text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_words = [w for w in words if not w.lower() in stop_words]
# 词干提取
stemmer = PorterStemmer()
stemmed_words = [stemmer.stem(w) for w in filtered_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
lemmatized_words = [lemmatizer.lemmatize(w) for w in filtered_words]
# 词性标注
tagged_words = nltk.pos_tag(lemmatized_words)
print("分词:", words)
print("去除停用词:", filtered_words)
print("词干提取:", stemmed_words)
print("词形还原:", lemmatized_words)
print("词性标注:", tagged_words)

②使用 NLTK 和 Matplotlib 可视化文本词汇分布与频率分析
import nltk
from nltk.book import * # 导入 NLTK 书中的所有内容
import matplotlib.pyplot as plt
# 下载所需的资源包
nltk.download('genesis')
nltk.download('book')
nltk.download('inaugural')
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')
nltk.download('words')
nltk.download('stopwords')
nltk.download('wordnet')
# 搜索文本
text1.concordance("monstrous")
text2.concordance("affection")
text3.concordance("lived")
text5.concordance("lol") # 聊天记录
# 搜索相似词
text1.similar("monstrous")
print("-----分割线----")
text2.similar("monstrous") # 不同文本中的相似词
# 搜索共同上下文
text2.common_contexts(["monstrous","very"])
# 词汇分布图
text4.dispersion_plot(["citizens","democracy","freedom","duties","America"]) # 救济演说语料
# 随着时间发展,单词出现的频率
# 使用 text1 生成文本(需要 text1 已经导入)
generated_text = text1.generate(50) # 生成 50 个单词的文本
print(generated_text)
# 计数词汇
len(text3)
print(len(text3))
sorted(set(text3)) # 排序
len(set(text3)) # 去重
#重复词密度
print(len(text3)/len(set(text3))) # 平均每个标识符出现16次
# 关键词密度
print(text3.count("smote"))
print(100* text4.count("a")/len(text4))
def lexical_diversity(text):
return len(text)/len(set(text))
def percentage(count,total):
return 100*count/total
print(lexical_diversity(text3))
print("text5 diversity is {}".format(lexical_diversity(text5)))
print("in text4,a percentage {}%".format(percentage(text4.count("a"),len(text4))))
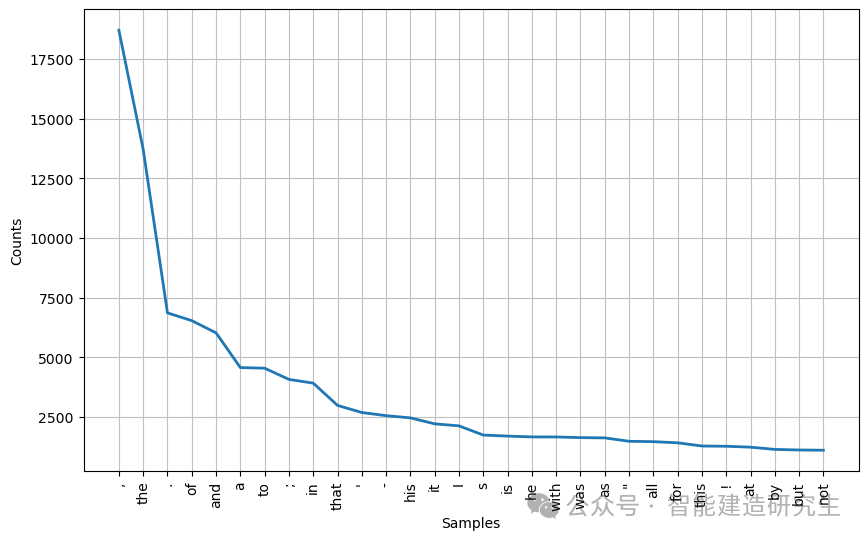
# 创建词汇频率分布
fdist1 = FreqDist(text1)
# 打印词汇频率分布的摘要
print(fdist1)
# 获取词汇表
vocabulary1 = fdist1.keys()
# 可视化频率分布
plt.figure(figsize=(10, 6))
fdist1.plot(30, cumulative=False) # 绘制前30个词汇的频率分布
plt.show()
# 输出:
'''
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
Displaying 25 of 79 matches:
, however , and , as a mark of his affection for the three girls , he left them
t . It was very well known that no affection was ever supposed to exist between
deration of politeness or maternal affection on the side of the former , the tw
d the suspicion -- the hope of his affection for me may warrant , without impru
hich forbade the indulgence of his affection . She knew that his mother neither
rd she gave one with still greater affection . Though her late conversation wit
can never hope to feel or inspire affection again , and if her home be uncomfo
m of the sense , elegance , mutual affection , and domestic comfort of the fami
, and which recommended him to her affection beyond every thing else . His soci
ween the parties might forward the affection of Mr . Willoughby , an equally st
the most pointed assurance of her affection . Elinor could not be surprised at
he natural consequence of a strong affection in a young and ardent mind . This
opinion . But by an appeal to her affection for her mother , by representing t
every alteration of a place which affection had established as perfect with hi
e will always have one claim of my affection , which no other can possibly shar
f the evening declared at once his affection and happiness . " Shall we see you
ause he took leave of us with less affection than his usual behaviour has shewn
ness ." " I want no proof of their affection ," said Elinor ; " but of their en
onths , without telling her of his affection ;-- that they should part without
ould be the natural result of your affection for her . She used to be all unres
distinguished Elinor by no mark of affection . Marianne saw and listened with i
th no inclination for expense , no affection for strangers , no profession , an
till distinguished her by the same affection which once she had felt no doubt o
al of her confidence in Edward ' s affection , to the remembrance of every mark
was made ? Had he never owned his affection to yourself ?" " Oh , no ; but if
Displaying 25 of 38 matches:
ay when they were created . And Adam lived an hundred and thirty years , and be
ughters : And all the days that Adam lived were nine hundred and thirty yea and
nd thirty yea and he died . And Seth lived an hundred and five years , and bega
ve years , and begat Enos : And Seth lived after he begat Enos eight hundred an
welve years : and he died . And Enos lived ninety years , and begat Cainan : An
years , and begat Cainan : And Enos lived after he begat Cainan eight hundred
ive years : and he died . And Cainan lived seventy years and begat Mahalaleel :
rs and begat Mahalaleel : And Cainan lived after he begat Mahalaleel eight hund
years : and he died . And Mahalaleel lived sixty and five years , and begat Jar
s , and begat Jared : And Mahalaleel lived after he begat Jared eight hundred a
and five yea and he died . And Jared lived an hundred sixty and two years , and
o years , and he begat Eno And Jared lived after he begat Enoch eight hundred y
and two yea and he died . And Enoch lived sixty and five years , and begat Met
; for God took him . And Methuselah lived an hundred eighty and seven years ,
, and begat Lamech . And Methuselah lived after he begat Lamech seven hundred
nd nine yea and he died . And Lamech lived an hundred eighty and two years , an
ch the LORD hath cursed . And Lamech lived after he begat Noah five hundred nin
naan shall be his servant . And Noah lived after the flood three hundred and fi
xad two years after the flo And Shem lived after he begat Arphaxad five hundred
at sons and daughters . And Arphaxad lived five and thirty years , and begat Sa
ars , and begat Salah : And Arphaxad lived after he begat Salah four hundred an
begat sons and daughters . And Salah lived thirty years , and begat Eber : And
y years , and begat Eber : And Salah lived after he begat Eber four hundred and
begat sons and daughters . And Eber lived four and thirty years , and begat Pe
y years , and begat Peleg : And Eber lived after he begat Peleg four hundred an
Displaying 25 of 822 matches:
ast PART 24 / m boo . 26 / m and sexy lol U115 boo . JOIN PART he drew a girl w
ope he didnt draw a penis PART ewwwww lol & a head between her legs JOIN JOIN s
a bowl i got a blunt an a bong ...... lol JOIN well , glad it worked out my cha
e " PART Hi U121 in ny . ACTION would lol @ U121 . . . but appearently she does
30 make sure u buy a nice ring for U6 lol U7 Hi U115 . ACTION isnt falling for
didnt ya hear !!!! PART JOIN geeshhh lol U6 PART hes deaf ppl here dont get it
es nobody here i wanna misbeahve with lol JOIN so read it . thanks U7 .. Im hap
ies want to chat can i talk to him !! lol U121 !!! forwards too lol JOIN ALL PE
k to him !! lol U121 !!! forwards too lol JOIN ALL PErvs ... redirect to U121 '
loves ME the most i love myself JOIN lol U44 how do u know that what ? jerkett
ng wrong ... i can see it in his eyes lol U20 = fiance Jerketts lmao wtf yah I
cooler by the minute what 'd I miss ? lol noo there too much work ! why not ??
that mean I want you ? U6 hello room lol U83 and this .. has been the grammar
the rule he 's in PM land now though lol ah ok i wont bug em then someone wann
flight to hell :) lmao bbl maybe PART LOL lol U7 it was me , U83 hahah U83 ! 80
ht to hell :) lmao bbl maybe PART LOL lol U7 it was me , U83 hahah U83 ! 808265
082653953 K-Fed got his ass kicked .. Lol . ACTION laughs . i got a first class
. i got a first class ticket to hell lol U7 JOIN any texas girls in here ? any
. whats up U155 i was only kidding . lol he 's a douchebag . Poor U121 i 'm bo
??? sits with U30 Cum to my shower . lol U121 . ACTION U1370 watches his nads
ur nad with a stick . ca u U23 ewwww lol *sniffs* ewwwwww PART U115 ! owww spl
ACTION is resisting . ur female right lol U115 beeeeehave Remember the LAst tim
pm's me . charge that is 1.99 / min . lol @ innocent hahah lol .... yeah LOLOLO
is 1.99 / min . lol @ innocent hahah lol .... yeah LOLOLOLLL U12 thats not nic
s . lmao no U115 Check my record . :) Lol lick em U7 U23 how old r u lol Way to
true contemptible christian abundant few part mean careful puzzled
mystifying passing curious loving wise doleful gamesome singular
delightfully perilous fearless
-----分割线----
very so exceedingly heartily a as good great extremely remarkably
sweet vast amazingly
am_glad a_pretty a_lucky is_pretty be_glad
long , from one to the top - mast , and no coffin and went out a sea
captain -- this peaking of the whales . , so as to preserve all his
might had in former years abounding with them , they toil with their
lances , strange tales
long , from one to the top - mast , and no coffin and went out a sea
captain -- this peaking of the whales . , so as to preserve all his
might had in former years abounding with them , they toil with their
lances , strange tales
44764
16.050197203298673
5
1.457806031353621
16.050197203298673
text5 diversity is 7.420046158918563
in text4,a percentage 1.457806031353621%
<FreqDist with 19317 samples and 260819 outcomes>
<Figure size 640x480 with 1 Axes>
<Figure size 1000x600 with 1 Axes>
'''
可视化输出:
词汇分布图 显示了特定单词在文本中的出现位置,便于分析这些单词在不同部分的分布情况。
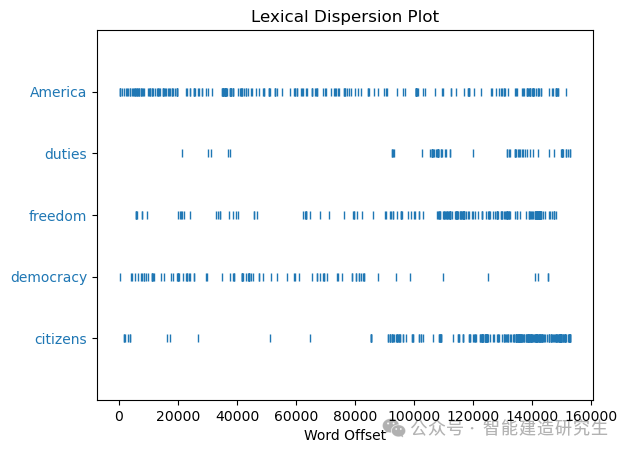
词频分布图 则展示了文本中高频词汇的出现次数,帮助识别和分析文本中的重要词汇和常用词汇的使用频率。
NLTK 是一个强大且灵活的自然语言处理工具包,适用于学术研究和教育。它提供了丰富的工具和资源,可以完成从文本预处理到高级语言分析的各种任务。通过结合使用 NLTK 的各种功能,我们可以构建复杂的自然语言处理应用程序,并深入理解语言数据。
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!















 509
509











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









