







1.均方误差:MSE
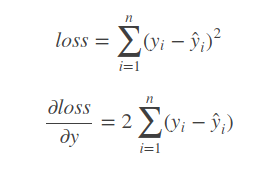
是最经典也是最简单的损失函数,几乎万能,但是不太准确。
2.binary_crossentropy交叉熵损失函数,一般用于二分类:

3.categorical_crossentropy分类交叉熵函数:
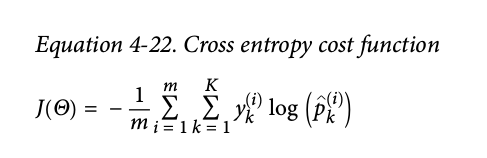
n是样本数,m是分类数。
一般来说,如果最后一层接上softmax作为分类概率输出时,都会用categorical_crossentropy作为损失函数,所以框架中会进行优化,对这两条公式的梯度合起来计算
softmax激活函数:

softmax激活函数,就是将输入数据取指数,然后归一化后,谁的数值较大谁的概率就越大。这解决了输出数据中概率和必需为1。而且输出概率值与输入值之间成正相关的问题。
题外话:好多博客写的多多少少都有些错误,我觉得学习到现在深受一些博客错误点的毒害。有能力的话,最好还是看官方的文档和英文著作和论文比较靠谱。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









