






数据仓库
数据仓库(Data Warehouse),可简写为DW或DWH,数仓等。它仅适用于查询和分析,通常涉及大量的历史数据。数据仓库中的数据一般来自应用日志文件(数据埋点)和事务应用(实际发生的业务记录的数据)等广泛来源。
一个数据仓库通常包含以下要素:
- 一个用于存储和管理数据的关系数据库(最主要作用);
- 一个用于分析前数据准备的提取、加载和转换 (ELT) 解决方案(必备方案);
- 统计分析、报告和数据挖掘功能;
- 用于数据可视化和展现的客户端分析工具;
- 其他更复杂的分析应用通过应用数据科学和人工智能 (AI) 算法或图形和空间功能来生成切实可行的信息,从而支持对数据进行更多类型的大规模分析。
前两点最重要,是一个数据仓库必须具备的要素,后三点实际看公司的数据人员如何使用。总结就是:储存+ETL+分析。
一、数据埋点
数据埋点是什么
数据埋点是一种数据采集方法,主要采集用户在网站或APP等的使用情况、行为习惯等。埋点方案的设计需要考虑以下几个方面:
业务需求:根据业务需求确定需要采集哪些数据。
埋点类型:根据业务需求选择合适的埋点类型,如代码埋点、可视化埋点、无埋点等。
埋点位置:根据业务需求确定需要在哪些位置进行埋点。
数据格式:根据业务需求确定数据的格式。
数据采集:根据业务需求选择合适的数据采集工具。
对于实际的业务方来说,只关心业务需要什么数据;开发人员会在此基础上关心后四点,以最好的获得数据;对于数仓加工人员来说,关心的是数据在哪个表的哪个字段中,以及考虑怎么把业务的实际需要加工到表里。
怎么设计数据埋点
通常是产品经理、运营或者数据分析师提前做好埋点规划(也就是想要采集什么数据),然后由开发工程师来根据规划去实施埋点。当然,有的公司职责划分没这么清楚,会使用第三方工具完成。
每个人对埋点设计的理解不尽相同,对于开发来说,只要我的产品可以正常运行,系统后台可以获得对应统计数据,就可以是一个合格的埋点设计;但对于实际看数和分析数据的人员来说(也就是产品、运营、数据岗),可能所需要的数据不仅仅是维持产品运行的数据,也需要其他数据。开发一般会在保证产品正常使用和效率不受影响的情况下,尽可能考虑业务人员的数据需求,把数据储存。
二、数仓设计
数据源进入数仓
一般,开发系统侧的数据储存在Mysql等关系数据库管理系统中(RDBMS,Relational Database Management System,还有DB2、SQLServer、Mango DB等),而离线数据一般储存在HDFS(Hadoop Distributed File System)中,所以需要把RDBMS的数据转换并保存到HDFS中,一般使用sqoop(SQL-to-Hadoop)来完成这个操作。
HDFS会对文件分块,一般一个分块的大小默认为128M。
(补充:但是实际由于sql特性,可能导致并不一定严格按照这个来分块,例如sparksql,很容易生成大量的小文件块,优化方法包括:distribute by partition,SELECT /*+ REPARTITION(partition) */ 等)
数仓分层设计
数据进入数仓,到最终的实际业务使用、查询、分析,需要数据开发人员一步步加工:
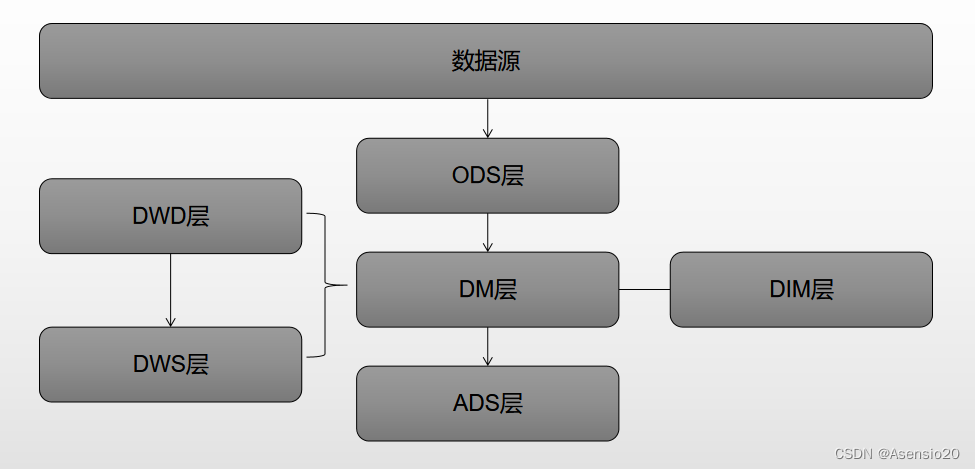
1.ODS(Operational Data Store)数据源层
把数据源的数据完整不动的储存下来
2.DM(Data Warehouse)数据仓库层
DW 层又细分为 DWD(Data Warehouse Detail)层、DWM(Data WareHouse Middle)层和 DWS(Data WareHouse Servce) 层。
(1)DWD(Data Warehouse Detail)数据明细层
DWD层的数据来源其实就是数据源的数据,在这里,数据会进行最基本的加工处理,比如数据清洗、规范化重命名、字段类型统一等;同时,DWD层也会做一些数据的聚合计算处理,以获得更方便下游使用的数据。
(2)DWM(Data WareHouse Middle)数据中间层
数据中间层会在DWD层的基础上,再进行轻度的聚合计算等加工,生成中间表目的是生成一系列需要使用的指标维度等数据,避免数据的重复加工。当然,有些企业的数据框架中,并没有这一层,会直接吧DWD的数据加工到DWS中去,DWM层的实际作用是为了方便DWS层选择需要的数据加工计算,因此没有DWM层,理论上DWS的数据也可以直接通过DWD层加工得到。
DWD层的划分比较模糊,可以按照数据来源系统的不同来划分(按上游来源划分),也可以按照业务需求或业务线的不同分类来划分(按下游实际使用划分):前者数据产出会更稳定,一个系统故障不影响其他系统数据正常产出;后者更贴近实际使用,使用起来很多时候一两个表就可以得到所需的数据进行加工。
(3)DWS(Data WareHouse Summary)数据汇总层
DWS也被称为轻度汇总层,这是在DWD(以及DWM)已经对ODS层数据进行简单的清洗、分类、规范化和轻度加工后,进行的轻度聚合汇总计算,得到的数据表。这层的数据一般比较少,更多的都是计算好的数据表,或者很容易计算的大宽表。
3.ADS(Application Data Store)数据应用层
这里数据的存储方式和加工方法,更为多种多样。一般来说,还是会有存储在HDFS中的Hive表供查数、数据分析和数据挖掘使用,也会有存储在PostgreSql、VerticaSql等数据库的供线上系统使用。而各种BI报表的数据,一般都是在这里加工出来的。
4.DIM(Dimension)维表层
不同企业对于维表层数据的划分有一些差异,有的企业会认为DIM层是与DM层并行的,而有的企业划分时认为DIM层是与DM和ADS层并行的。
维表一般记录的是维度数据,比如用户的各个特征标签维表、某个产品的配置信息维表等,需要注意的是,这两个例子,前者的数据量一般较大,有几千万上亿甚至更多,而后者一般很少,几十几百都是有可能的。
离线数仓的整体分层示意图如下:
参考资料:
《数据仓库篇》——离线数仓数据链路和组件
最强最全面的数仓建设规范指南 (一)
表设计
1.分区表
当表未分区,我们查询这张表的时候,无论我们想查询的数据量是多还是少,MapRuduce程序都会扫描读取整张表,然后再按sql语句的条件计算我么需要的数据,实际上这种做法会带来大量的不必要计算。例如如果我们只需要查询最近一天的数据,我们实际上可以想办法把数据文件按照日期来区分开,让程序先识别我们需要在哪个日期文件上查询数据,再在这个较小的数据表里查询我们所需的数据,这种做法效率明显更高,特别对于大表来说,其效率和速度都会明显更优。
而这种思想就是表的分区设计,表被分区之后,每一个分区都会对应一个目录,这个表在查询的过程中,会率先读取分区有关条件,把所需要的分区目录查找出来,再在这个目录范围内查询数据,这样,实际计算花费的开销就会小很多。
一般分区表在建表时中需要加入partitioned by ‘分区字段’ 这样的语句,不同sql引擎对应的建表语法可能略有差别,一般表按照业务日期来进行分区。
2.分桶表
除了可以把表分区外,也可以把表分桶处理,分桶直接把数据表分为多个文件。sql语句为clustered by ‘分桶字段’。
分桶与分区的区别在于:
(1)分区的每个分区是一个子目录,而分桶是直接按照规则把表划分成多个文件;
(2)分区表的分区列是一个伪列,可以为原本表不包含的列,比如全量表的日期,实际只是为了方便查询数据而存在的;分桶表的分桶字段为表中必须要有真实字段;
(3)分区表的分区数可以增加,也可以删除,但分桶表的分桶数必须是固定的;
(4)分区一般是按照自己定义的规则来进行划分,而分桶一般是按照hash结果来划分,无法自己定义。
3.索引
虽然Hive表没有主键的概念,但是有索引的概念,当查询条件正好是索引列时,查询会先按照索引选取部分数据,再进行查询。这种做法也会加快查询速度,但不会像分区分桶一样切分数据表。
4.文件储存格式
(1)TextFile
Hive的默认储存方式,按行存储,不对数据进行处理的存储方式。
(2)SequenceFile
以二进制的KV格式存储数据,但是消耗存储空间大。
(3)Parquet
列式存储文件格式,但不支持update、delete等操作(也有说也不支持insert操作,但我在企业实际使用时是可以insert的,可能是二次开发),支持嵌套式结构,适应多种。
(4)OCR
列式存储,压缩率高,支持索引。查询时的性能消耗可能比较大。
一般认为,Parquet和Spark适配的更好,而OCR更适合Hive; 如果Hadoop 生态系统中使用多种工具,那么Parquet的优秀的适应性会是一种更好的选择。
5.DWD层表设计
DWD层的表,更关注于对于源头数据,加工出可以使用的字段,形成事实表。ODS层的数据直接源于数据埋点和源头,DWD层主要是针对ODS层进行加工,一般遵守以下几个原则:
1)确定业务事实:DWD层作为事实表,一般需要反映一个具体的业务事实的明细,因此,需要先向下游业务方了解完全需要的业务数据和方向,便于自己按照要求取出所需数据放到DWD表。
2)确定粒度:再有了明确的业务过程后,就需要确定数据表的粒度。一般认为,数据的粒度越细越好,越细的粒度,更有助于发挥事实表的灵活性,不需要重复建表。当然,当数据量特别大的时候,DWD层可能也无法直接照顾到最细的粒度,这时要尽量选择常用的粒度,比如客户粒度较为复杂,可以按照一定特征归纳到客群粒度上来等等。
3)确定维度:维度是指事实数据归纳起来的角度,比如交易数据,可以从客户、产品、时间等方向来确定这行数据的内容,而这里的客户、产品、时间等就是维度。
4)确定口径:确定好下游计算的口径,进行加工处理,加工处理的结果应该与业务需要的口径相同,此外,如果有一个指标有多个口径,可以考虑分别加工出来,但要在表注释中写清口径差异。
6.DWS层表设计
在有ADS层和DWD层的情况下,DWS层实际上可以没有;但长期来看,DWS是需要且重要的,主要原因为:
1)DWD层很可能对于一个指标有多个口径(上面提到),需要在DWS层统一取数口径,否则容易造成指标混乱的情况;
2)DWD层的指标可能比较细化,尽管ADS层有计算好的指标,但ADS层主要服务于确定口径下的取数结果或报表,其适用性和灵活性很可能不足,在自主分析的时候,需要有一层可以做轻度的汇总,做到比DWS计算更方便,比ADS更灵活。
DWS表的设计一般遵守以下几个步骤:
1)确定汇总维度:确定汇总维度是重中之重,一般情况下,其实建表的时候,需要统计的是哪个指标是比较确定的,比如交易表要统计交易次数、金额等,但是维度一般需要多加揣摩,例如交易表计算的是客户维度、商家维度还是产品种类维度等等。因此,首先确定好汇总的维度,是表设计的基础。
2)确定统一口径:DWS的一大作用就是来确定取数的统一口径的,因此在设计的时候一定要确定好每个字段是从哪个表怎样加工而来。
3)确定统计周期:既然是汇总表,那就需要按一定周期来汇总,比如按照天,汇总1天、3天、7天、15天、30天的指标等等。这种汇总结果一般是直接通过DWD表聚合而来。
4)确定聚合事实:这里其实就是1)中说的统计哪个指标,一般在街道需求或加工之前就已经确定好了,否则也不可能思考维度、口径等等取什么。这一步会有派生指标的出现,比如7天内的某客户的交易总金额。
一般来说,一张DWS表尽量只放一个派生指标,比如一张表只计算交易总金额的聚合,不放交易次数等的聚合;但在实际的工作中,由于整体计算存储的资源有限,可能需要在DWS表中放多个派生指标,尽管表的使用面更广,但实际增加了使用难度。多个派生指标的聚合过程其实尽可能在ADS层的表中实现。
7.ADS层表设计
根据具体需求确定即可。
参考资料
三、数据处理
离线数据
离线数据又称为“批处理”,一般指的是数仓中的T+1数据,即今天的数据只能更新到昨天的情况,这些数据一般是在每天的凌晨0点开始,一个一个依次跑批完成。
数仓中的数据,绝大多数都是离线数据。离线数据的优劣势十分明显,优势就是数据量大、可以查询历史数据、方便精确计算等等;劣势也很显而易见,就是慢,今天的数据需要至少到明天才能看到。
离线数据最常用的框架依然是Hadoop,核心组件是HDFS、MapReduce、Hive。以HDFS进行数据存储,MapReduce计算,Hive进行数据仓库建设,基于HiveSQL、SparkSQL等引擎进行数据查询。
实时数据
实时数据又被称为“流处理”,数据一旦产生后,立即被加工处理到表里。优势在于数据处理及时,一旦有数据变化会立即处理;劣势在于消耗资源大,而且不可能保留很长时间,因为时间越长数据量和计算量将越来越大。
离线数据和实时数据的各自应用场景
1)离线数据:一般在数仓用的比较广泛,数仓一般是给业务方进行业务经营分析的,对于数据准确性的要求大于更新速度,即便是T-1的数据也是可以接受的。
2)实时数据:一般在实际业务系统会运用的较为常见,比如需要按照用户的点击做实时反馈,根据客户是否刚点击了注册发送新户礼包消息等,这时候数据更新速度远远比准确性重要的多。
一般情况下,企业的数据既要有实时数据也要有离线数据,实时数据便于实时运营业务,离线数据用于精准经营分析和数据报送等。
对于数仓来说,离线数据是比较成熟的流程,而实时数据实时数仓的建设目前还处于发展阶段。
实时数仓
实时数仓是指在数据处理过程中,能够及时地处理数据并提供实时的数据分析结果的数据仓库。 实时数仓的建设需要考虑多方面的因素,包括数据采集、数据处理、数据存储、数据查询等方面。
参考资料
四、反作弊处理
反作弊是指用数据分析(包括数据挖掘/机器学习/深度学习等)解决业务发展中遇到的作弊(spam)问题。作弊问题包括机器人刷单,僵尸粉等等问题。
反作弊处理一般在应用层数据之后,业务报表或业务数据分析前,进行处理。
处理方式有:通用技术(比如认为设置的规则流程图等)、数据分析(聚类模型、预测模型等预测是否作弊)、评分模型、机器学习。
实际上,评分模型、数据分析和机器学习会相结合,也有人认为评分模型是数据分析的一种。















 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









