






数据挖掘是从数据入手,分析数据,并数据中得到原本看不到的、隐藏的信息。对于数据分析师来说,数据挖掘也是必不可少的技能。
数据挖掘涵盖了数学、统计学、计算机、物理学、人工智能等多学科知识,因此数据挖掘篇也会较长,共分为五个篇幅:统计学问题、特征工程、分类聚类问题、关联回归问题、算法和评估指标。
本文为第三篇,主要内容为分类聚类问题。
一、分类问题
分类问题是日常生活中非常常见的一个问题,比如预测判断明天股票是涨还是跌、判断每个图片中的水果都是什么等等。分类问题的目的是利用已知信息判断事物的种类,而已知信息一般就是类似事物的特征,通常被认为属于监督式学习。
根据类别的数量还可以进一步将分类问题划分为二元分类和多元分类。
二元分类问题
二元分类的结果,一般是两个相互对立的集合,比如性别、是否是xx等01问题。这类问题通常我们只需要考虑一种情况的可能性大小,对应的1-该可能性,就是另一种情况的可能性。
二元分类问题的解法有几种:线性分类、SVM、树模型等。
线性分类
线性分类最基本的方法就是逻辑回归,实际上这也是在面对二元分类问题最基本的解决方法。逻辑回归会把二元分类中,一类记为1,则另一类自动记为0,计算属于1这一类的概率大小p,那么属于0这一类的概率就是1-p。由于线性回归的Y值一般是(-∞,+∞),需要一个函数将其单调的放缩到[0,1]中,而逻辑回归借助的这个放缩函数就是
1
1
+
e
−
x
\frac{1}{1+e^{-x} }
1+e−x1
这个函数也叫sigmoid函数或logistic函数,可以发现,当x从负无穷到正无穷的区间上,这个函数的会单调的变化在(0,1)内。
尽管我们可以构建出模型式子,但是并不清楚如何解。利用数学上的极大似然思想,找到一组参数,使得在这组参数下,我们的数据的似然度(概率)最大:
P
(
Y
=
1
∣
x
)
=
p
(
x
)
,
P
(
Y
=
0
∣
x
)
=
1
−
p
(
x
)
P(Y=1|x)=p(x),P(Y=0|x)=1-p(x)
P(Y=1∣x)=p(x),P(Y=0∣x)=1−p(x)
此时,对应的似然函数为:
∏
[
p
(
x
i
)
]
y
i
[
1
−
p
(
x
i
)
]
1
−
y
i
\prod [p(x_{i} )]^{y_{i} } [1-p(x_{i} )]^{1-y_{i} }
∏[p(xi)]yi[1−p(xi)]1−yi
两边取对数,再平均取相反数(这里最大似然与最小损失等价),就是我们熟悉的损失函数:
−
1
N
∑
[
y
i
l
n
p
(
x
i
)
+
(
1
−
y
i
)
l
n
(
1
−
p
(
x
i
)
)
]
-\frac{1}{N} \sum [y_{i}lnp(x_{i})+(1-y_{i})ln(1-p(x_{i}))]
−N1∑[yilnp(xi)+(1−yi)ln(1−p(xi))]
最大似然估计也就是最小损失估计。
有了损失函数后,可以使用梯度下降或牛顿法等方法求解。
支持向量机SVM
支持向量机SVM的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, wx+b=0,即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个,但是几何间隔最大的分离超平面却是唯一的。
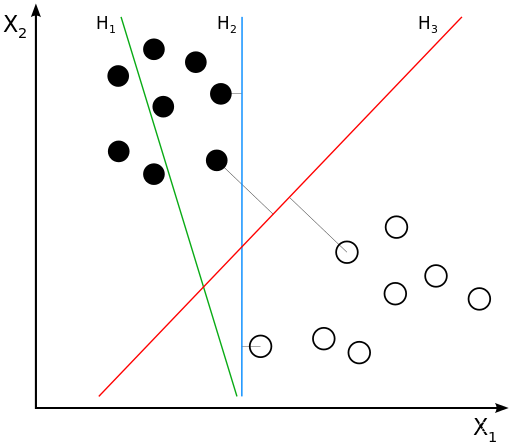
如图所示,这里有三条直线,哪一条的分类效果最好呢。首先,H1最小被排除,因为其根本没有区分能力,在H1右侧既有黑球也有白球;H2和H3都可以区分出来,但是很明显H3相较于H2区分效果更好,因为黑球和白球,相对离H3都更远,H2虽然也能区分,但是两类球都离H2比较近,感觉随时有可能在H2右侧出现黑球或H2左侧出现白球。而H3这个离得更远的直观感受,就是几何间隔最大的意思。
可以发现,这里介绍的SVM只能解决线性可分的问题,为了解决更加复杂的问题,支持向量机学习方法有一些由简至繁的模型:
(1)线性可分SVM
当训练数据线性可分时,通过硬间隔(hard margin,什么是硬、软间隔下面会讲)最大化可以学习得到一个线性分类器,即硬间隔SVM,如上图的的H3。
(2)线性SVM
当训练数据不能线性可分但是可以近似线性可分时,通过软间隔(soft margin)最大化也可以学习到一个线性分类器,即软间隔SVM。
(3)非线性SVM
当训练数据线性不可分时,通过使用核技巧(kernel trick)和软间隔最大化,可以学习到一个非线性SVM。
参考资料:看了这篇文章你还不懂SVM你就来打我
树模型
按照特征进行分类,每次分类会选择所有特征所有切分点中,选择分类后样本不纯度(基尼系数)下降最大(基尼增益)的切分点。直至最后达到不纯度阈值,或者无法再通过切分来降低不纯度,结束。这种计算方法就是树模型的基本逻辑。
树模型很适合分类问题,因为其计算本质就是切分、计算的循环。
多元分类问题
处理多元分类问题,可以将二元分类的0和1分别放到每一类上,比如三分类问题,三类可以用三个向量(1,0,0)、(0,1,0)、(0,0,1)分别表示。
这时候,我们需要判断的就是一个样本属于每一类的概率,比如计算出来的结果是(0,1,0.7,0.2),那么很明显,这个样本最有可能属于第二类。这时候我们需要的就不是sigmoid函数了,而是softmax函数:
s
o
f
t
m
a
x
(
x
i
)
=
e
x
p
(
x
i
)
∑
e
x
p
(
x
i
)
softmax(x_{i})=\frac{exp(x_{i})}{\sum exp(x_{i})}
softmax(xi)=∑exp(xi)exp(xi)
而对应的损失函数为:
−
1
N
∑
N
∑
C
Y
i
l
o
g
(
P
i
)
- \frac{1}{N}{\textstyle \sum_{N}^{}} {\textstyle \sum_{C}^{}} Y_{i}log(P_{i})
−N1∑N∑CYilog(Pi)
这里
P
=
[
p
1
,
p
2
,
.
.
.
,
p
C
]
P=[p_{1},p_{2},...,p_{C}]
P=[p1,p2,...,pC]
Y
=
[
y
1
,
y
2
,
.
.
.
,
y
C
]
Y=[y_{1},y_{2},...,y_{C}]
Y=[y1,y2,...,yC]
P是是一个概率分布,每个元素 pi表示样本属于第i类的概率;Y是样本标签的onehot表示,当样本属于第类别i时yi=1,否则yi=0。
这样,我们也构建出了多分类问题的求解方法。
二、聚类问题
分类问题是一个监督式学习的模型,即根据样本特征和样本所属的类,判断其他样本属于哪一类;而实际生活中,会有一些“分类”的问题,并没有参考结果,只是把样本按照特征来划分成几类,这种问题就成为聚类问题。
聚类分析算法
聚类分析的目的,实际上就是把特征相似的归为一类,相差较大的归为不同类。聚类分析的基本算法有:k-means算法、层次聚类、DBSCAN算法等。
k-means算法
k-means算法是一种被广泛用于实际问题的聚类算法。它将样本划分成个k类,参数k由人工设定。
先随机指定k个点作为k个类的质心,然后将每个样本划分到离它最近的质心所代表的类,分为后重新计算每个类的质心,再按照k个质心重新划分每个样本所属的类,以此往复迭代,直至收敛。
一般迭代终止的判定规则,是计算本次迭代后的类中心和上一次迭代时的类中心之间的距离,如果小于指定阈值,则迭代终止。
层次聚类
层次聚类的方法是,把每一个单个的观测都视为一个类,而后计算各类之间的距离,选取最相近的两个类,将它们合并为一个类。新的这些类再继续计算距离,合并到最近的两个类。如此往复,最后就只有一个类。然后用树状图记录这个过程,这个树状图就包含了我们所需要的信息。如下图所示:
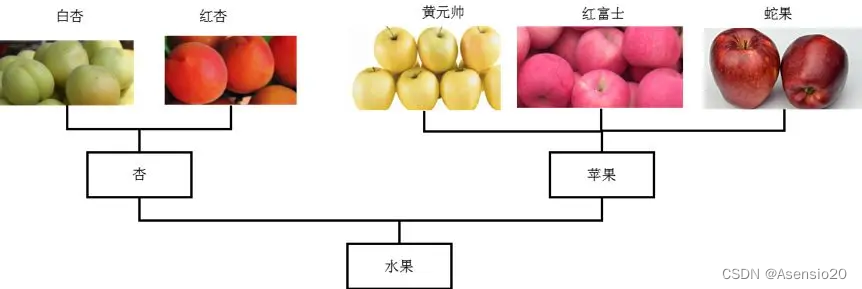
这里如果我们需要两个类,则这两个类是杏类和苹果类,如果只需要一个类,这个类就是水果类。
DBSCAN算法
DBSCAN算法是一种基于密度的算法。
方法是:
首先,从数据集中随机选择核心点,以一个核心点为圆心,做半径为V的圆;
然后,选择圆内圈入点的个数满足密度阈值的核心点,将这个圈内的点形成一个簇,则簇内每个点到该圈核心点的距离小于V;
最后,合并相互重合的簇,形成一类。
参考资料:
一篇文章透彻解读聚类分析(附数据和R代码)
深入浅出聚类算法
除此之外,还有基于概率的EM算法、基于图的聚类算法等。
聚类分析评价指标
聚类分析的评价指标分为外部评价指标和内部评价指标。所谓外部评价指标是指在知道真实标签的情况下来评估聚类结果好坏的指标;内部评价指标是不借助于外部信息,仅仅只是根据聚类结果来进行评估的指标。
外部评价指标类似于分类问题的评价指标,包括聚类纯度等,可以见文章《几种常见的聚类外部评价指标》。
内部评价指标包括轮廓系数、Calinski-Harabasz指数、Davies-Bouldin指数等,可以见文章轮廓系数、方差比、DB指数(三种常见的聚类内部评价指标)和【聚类指标】如何评估聚类算法:外部指标和内部指标、指标详解。
三、总结
本篇主要针对的是类别问题,分为有监督的分类和无监督的聚类问题进行讨论,实际上类别问题的种类和方法要比文章内介绍的多得多,本文只是重点介绍了一些常见常用的知识点。
除了离散型变量作为因变量,实际还会有连续型变量作为因变量的问题,而下一篇的关联回归,讨论的就是这类问题。















 513
513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









