






数据挖掘是从数据入手,分析数据,并数据中得到原本看不到的、隐藏的信息。对于数据分析师来说,数据挖掘也是必不可少的技能。
数据挖掘涵盖了数学、统计学、计算机、物理学、人工智能等多学科知识,因此数据挖掘篇也会较长,共分为五个篇幅:统计学问题、特征工程、分类聚类问题、关联回归问题、算法评估指标。
本文为第五篇,主要内容为算法评估指标。
一、算法
对于数据分析来说,算法并不是主要技能,但仍然需要了解一些基本算法,有助于拓宽对数据的处理思路。
对于数据分析来说,比较主要的分析目的有预测、溯源,常见的有线性回归、支持向量机、树模型等等。
二、评估指标
评估指标是针对模型性能优劣的一个定量指标。对于不同类的结果变量,有不同的评估指标。大致可以分为分类评估指标和回归评估指标,分别对应离散变量和连续变量。
分类评估指标
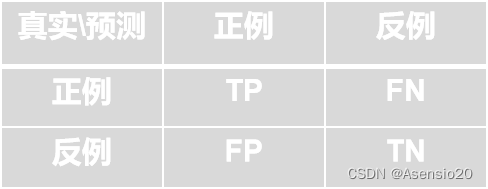
混淆矩阵
针对一个二分类问题,即将实例分成正类(positive)或负类(negative),在实际分类中会出现以下四种情况:
(1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive)
(2)若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative)
(3)若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive)
(4)若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative)
这样便可以得到一个混淆矩阵:
准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1 Score
准确率Accuracy=(TP+TN)/(TP+FP+TN+FN)
精确率Precision=TP/(TP+FP)
召回率Recall=TP/(TP+FN)
F1 Score=2×Precision×Recall/(Precision+Recall)
P-R曲线
P指精确率Precision,R指召回率Recall,P-R曲线是指设置不同的阈值,模型预测所有的正样本,计算对应的精准率和召回率为坐标点,形成的曲线。
模型与坐标轴围成的面积越大,则模型的性能越好。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
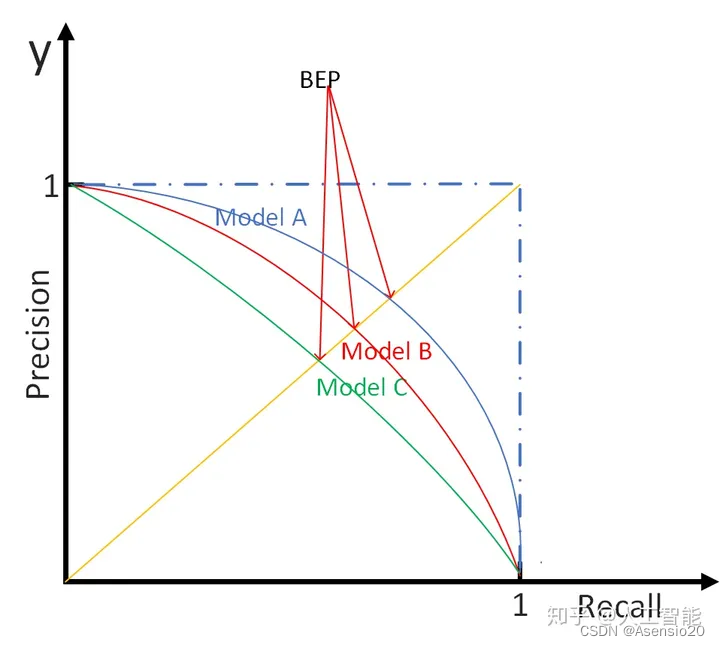
图片来源:https://zhuanlan.zhihu.com/p/110015537
ROC曲线和AUC
先明确三个概念:
灵敏度TPR=TP/(TP+FN)
特异度TNR=TN/(FP+TN)
FPR=1-TNR=FP/(FP+TN)
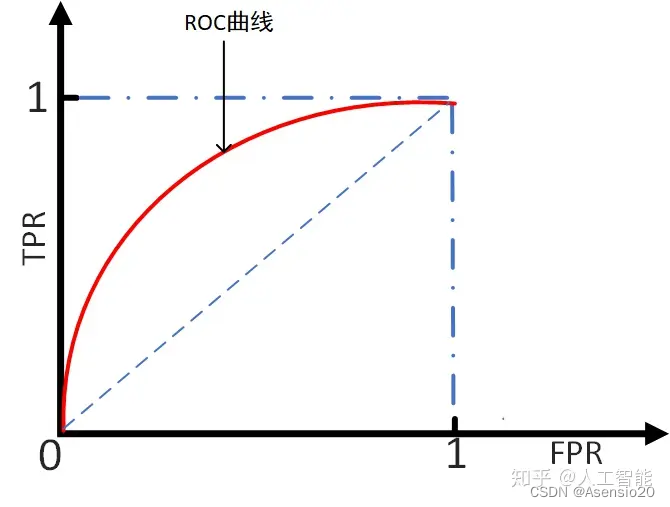
ROC(Receiver Operating Characteristic)曲线,又称接受者操作特征曲线。曲线对应的纵坐标是TPR,横坐标是FPR。
图片来源:https://zhuanlan.zhihu.com/p/110015537
绘制方法:
设置不同的阈值,会得到不同的TPR和FPR,而随着阈值的逐渐减小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着负类,即TPR和FPR会同时增大。阈值最大时,对应坐标点为(0,0),阈值最小时,对应坐标点(1,1)。
理想目标: TPR=1, FPR=0,即图中(0,1)点。故ROC曲线越靠拢(0,1)点,即,越偏离45度对角线越好。对应的就是TPR越大越好,FPR越小越好。
AUC(Area Under Curve)是处于ROC曲线下方的那部分面积的大小。AUC越大,代表模型的性能越好。
参考资料
分类算法评价指标详解
回归评估指标
回归模型的评估指标,可以集中在预测值和实际值的对比上,常用的评估指标有:平均绝对误差(MAE)、均方误差(MSE)、均方根误差(RMSE)、中位绝对误差(MedAE)、R Squared等。
具体公式可见参考资料链接。
除了R Squared,这些指标都是越小越好,因为这些都是描述误差的指标。
注意事项
(1)MAE和MedAE描述的是绝对误差,前者是绝对误差的平均值,后者是绝对误差的中位数,MedAE对于极端值相对不敏感;MSE和RMSE描述的是误差的平方。
(2)MAE,和RMSE或MAPE可以一起使用:比如RMSE远大于MAE时,可以得知不同样例的误差差别很大;MAE远大于MAPE×y均值,则模型对真实值小的样本预测更准,可以考虑为不同数量级的样本建立不同的模型。















 3937
3937











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









