






数据挖掘是从数据入手,分析数据,并数据中得到原本看不到的、隐藏的信息。对于数据分析师来说,数据挖掘也是必不可少的技能。
数据挖掘涵盖了数学、统计学、计算机、物理学、人工智能等多学科知识,因此数据挖掘篇也会较长,共分为五个篇幅:统计学问题、特征工程、分类聚类问题、关联回归问题、算法和评估指标。
本文为第四篇,主要内容为关联回归问题。
一、关联问题
什么是关联问题
关联问题就是已知某个事物,挖掘未知事物与已知事物在历史数据上的相关性,以判断事物间的关联。而关联分析,就是从大规模数据中,发现对象之间隐含关系与规律的过程。
为什么需要研究关联问题
关联问题会出现在日常生活的方方面面,我们接触到的“推荐算法”,实际就是关联问题的解决方法。关联分析在商业领域有广泛的应用,如市场分析、产品推荐、库存管理等,它可以帮助商家了解顾客的购买行为,从而制定更有效的营销策略和商品陈列方式。
关联问题的解决
确定关联规则
(1)支持度:所有事件中,同时发生A和B事件的概率,称作A和B之间的支持度,公式为支持度=(A&B)/N,A&B代表A发生且B发生的次数,N代表总次数。比如今天共有10笔订单,其中同时购买牛奶和面包的次数是6次,那么牛奶+面包组合的置信度就是6/10=60%。
(2)置信度:发生A的事件中,也发生B事件的概率,称作{A→B}的置信度,公式为置信度(A→B)=(A&B)/A,A&B代表A发生且B发生的次数,A代表A发生的次数。比如今天共有10笔订单,购买牛奶的有8笔,其中同时购买牛奶和面包的次数是6次,那么{牛奶→面包}的组合置信度就是6/8=75%。如果关联规则{A->B}的置信度较高,则说明当A发生时,B有很大概率也会发生,这样就可能会带来研究价值。
(3)提升度:支持度(A->B)表示包含项集A和B的事务数占总事务数的比例,支持度(B)表示包含项集B的事务数占总事务数的比例,大于1说明该组合方式有效,小于1则说明无效。公式为提升度(A->B) = 置信度(A->B) / 支持度(B)。
关联规则相关算法
(1)Apriori算法
Apriori算法是一种用于挖掘关联规则的经典算法,由Rakesh Agrawal等人在1993年提出。该算法通过迭代搜索的方式,从频繁项集中挖掘出关联规则。
Apriori算法的基本思想是利用先验知识(即频繁项集)来推断出更多的频繁项集。具体来说,该算法通过以下步骤实现:
(1)找出所有频繁项集,即支持度大于等于最小支持度阈值的项集,一般从1项集开始。
(2)根据频繁项集,生成更多的候选项集,即由频繁项集中的项组合而成的新项集。
(3)对候选项集进行扫描,找出其中的频繁项集。
(4)重复步骤2和3,直到无法再生成新的频繁项集为止。
最后也可以针对每一个关联规则,分别计算其置信度,仅保留符合最小置信度的关联规则。
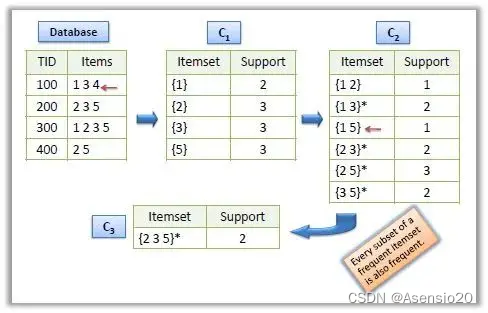
Apriori算法的优点是简单易懂,计算效率较高,适用于处理大规模数据集。但是,该算法也存在一些缺点,例如需要大量的内存空间存储候选项集,以及可能会产生大量的候选项集,导致计算时间较长。
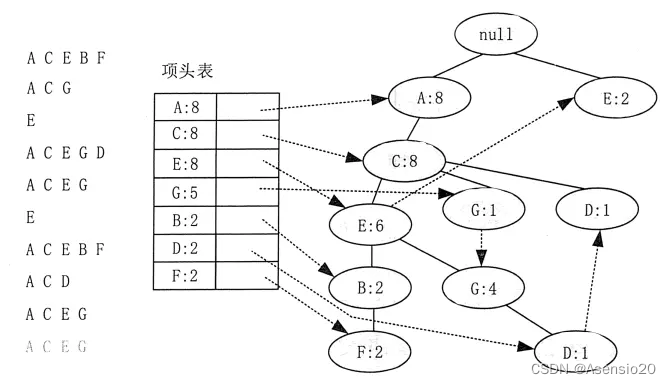
(2)FP-growth算法
FP-growth算法的基本思想是利用一棵频繁模式树来压缩数据集,从而减少计算时间。具体来说,该算法通过以下步骤实现:
(1)找出所有频繁项集,即支持度大于等于最小支持度阈值的项集。
(2)构建一棵频繁模式树,其中每个节点表示一个频繁项集,每个边表示两个频繁项集之间的关联关系。
(3)对于每个频繁项集,找出其对应的频繁模式树中的最长频繁子序列(LFP),即由该频繁项集中的项组合而成的最长频繁子序列。
(4)根据LFP,生成关联规则,并计算其支持度和置信度。
(5)重复步骤3和4,直到无法再生成新的频繁项集和关联规则为止。
FP-growth算法的优点是计算效率较高,可以处理大规模数据集,同时可以挖掘出高质量的关联规则。但是,该算法需要大量的内存空间存储频繁模式树,以及需要进行多次扫描数据集,因此在某些情况下可能会导致计算时间较长。
(3)参考资料
Apriori算法和FP-Tree算法简介
二、回归问题
什么是回归问题
回归分析是一种统计学上分析数据的方法,目的在于了解两个或多个变数间是否相关、相关方向与强度,并建立数学模型以便观察特定变数来预测研究者感兴趣的变数。一元线性回归分析是回归分析的一种,用于研究一个自变量和一个因变量之间的关系。
为什么需要解决回归问题
看上面的定义,会感觉回归与关联是类似的,实际上,回归不仅可以判断两个变量是否相关,还可以判断出相关的程度大小,以及相关的方向等信息,而这一切都会依赖于回归分析中的数学模型,这个模型不仅可以揭示出变量间的关系,还会给出强度大小和方向等具体值。
有了回归分析的结果,便可以用x→y来预测结果,也可以用y→x来寻找原因。也因此,回归问题在经济学、心理学、生物学、医学等领域都有广泛的应用。
回归问题的解决
模型选择
回归分析的方法有很多,其中一些常见的方法包括:一元线性回归分析、多元线性回归分析、逻辑回归分析、非线性回归分析、岭回归分析、逐步回归分析等。
按自变量与因变量的属性可以分为:
因变量-定量变量 , 自变量-定量变量 : 普通回归分析
因变量-定量变量 , 自变量-定性变量 : 含有哑变量(虚拟变量)的回归分析
因变量-定量变量 , 自变量-定性变量 : Logistic 回归分析
按照自变量的个数分为:
一元回归分析、多元回归分析。
回归分析容易遇到变量值较为极端或有噪音值的情况,面对这种情况可以使用Huber回归、Theil Sen回归和RANSAC回归等稳健回归模型。
回归分析也有可能自变量实际与因变量关系很小,需要筛选或剔除,可以使用逐步回归、岭回归、Lasso回归等。
数据处理
在数据分析笔记—数据挖掘篇(二)中,详细介绍了特征工程的步骤,同样适用于此处,因为回归分析实际上也是数据挖掘的过程,同样需要特征工程。
损失函数
损失函数用于衡量模型预测结果与真实结果之间的差异或误差。它是一个数值评估指标,通过对模型输出和真实标签之间的比较,提供了对模型性能的反馈。在训练模型时,我们的目标是最小化损失函数,以使模型的预测结果尽可能接近真实结果。常见的损失函数包括均方误差(MSE)、交叉熵损失(Cross-Entropy Loss)和绝对损失(MAE)等。
求解方法
回归问题,最后就是求回归模型的参数值,求解方法包括正规方程、梯度下降等方法。
评估指标
重新回到数据和模型,解完参数后,可以把模型预测值与实际值做个对比,计算模型效果如何。这个评价模型优劣的指标就是评估指标。回归模型评估指标是用于衡量回归模型性能的一组数值指标,它们可以帮助我们判断模型的预测能力和准确性,常见的回归模型评估指标包括:均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)、决定系数(R-squared)等。损失函数实际上也可以作为评估指标用来评价模型效果。
三、总结
关联分析和回归分析是两种常见的数据分析方法,它们的目的和应用场景有所不同。
关联分析是一种用于研究数据中变量之间关系的统计方法。它的目的是发现变量之间的关联规则,例如购物篮分析中的“买牛奶就会买面包”的规则。关联分析通常用于市场分析、推荐系统等领域。关联分析的常见算法包括Apriori算法、FP-growth算法等。
回归分析是一种用于研究两个或多个变量之间关系的统计方法。它的目的是通过对自变量和因变量之间的关系进行建模,来预测因变量的值。回归分析通常用于预测和建模,例如预测销售额、房价等。回归分析的常见模型包括线性回归、岭回归、Lasso回归等。
关联分析和回归分析都是用于研究变量之间关系的统计方法,但它们的目的和应用场景有所不同。关联分析用于发现变量之间的关联规则,回归分析用于预测和建模。















 2957
2957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









