






前言
本文为7月28日深度学习笔记, 分为三个章节:
- Theory behind GAN:Generation、max V(G, D)、Algorithm;
- Framework of GAN:f-divergence、Fenchel Conjugate;
- Tips for Improving GAN:JS divergence is not suitable、Least Square GAN(LSGAN)、Wasserstein GAN(WGAN).
一、Theory behind GAN
1、Generation
- x x x: an image(a high-dimensional vector) ;
- Find data distribution
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x).
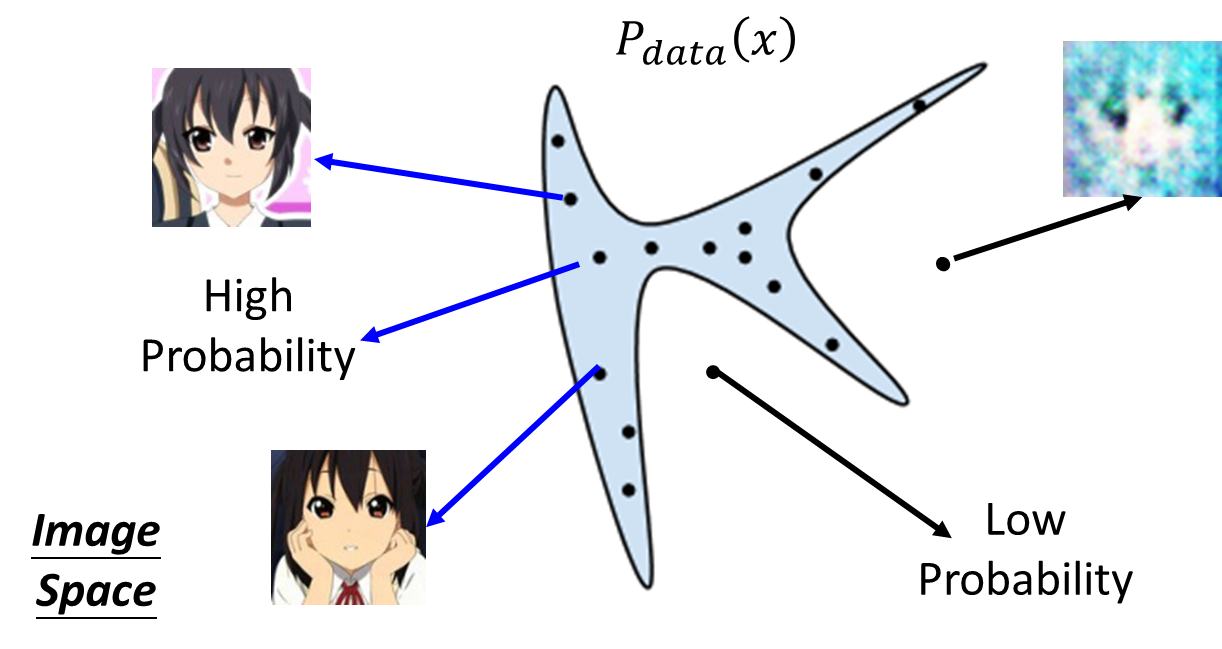
(1)、Maximum Likelihood Estimation = Minimize KL Divergence
- Given P d a t a ( x ) P_{data}(x) Pdata(x)(sample from it);
- We have a distribution
P
G
(
x
;
θ
)
P_G(x; \theta)
PG(x;θ):
- we want to find θ \theta θ such that P G ( x ; θ ) P_G(x; \theta) PG(x;θ) close to P d a t a ( x ) P_{data}(x) Pdata(x);
- Sample
{
x
1
,
x
2
,
…
,
x
m
}
\{x^1, x^2, …, x^m \}
{x1,x2,…,xm} from
P
d
a
t
a
(
x
)
P_{data}(x)
Pdata(x);
- we can compute P G ( x i ; θ ) P_G(x^i; \theta) PG(xi;θ)
- Likelihood of generating the samples:
L = ∏ i = 1 m P G ( x i ; θ ) L = \prod_{i=1}^{m}P_G(x^i;\theta ) L=i=1∏mPG(xi;θ) - Find
θ
∗
\theta^*
θ∗ maximizing the likelihood.
θ ∗ = a r g m a x ∏ i = 1 m P G ( x i ; θ ) = a r g m a x l o g ∏ i = 1 m P G ( x i ; θ ) = a r g m a x ∑ i = 1 m l o g P G ( x i ; θ ) ≈ a r g m a x E x P d a t a [ l o g P G ( x i ; θ ) ] = a r g m a x ∫ x P d a t a ( x ) l o g P G ( x ; θ ) d x − ∫ x P d a t a ( x ) l o g P d a t a ( x ) d x = a r g m i n K L ( P d a t a ∣ ∣ P G ) \theta^* = arg\ max \prod_{i=1}^{m}P_G(x^i;\theta ) = arg\ max\ log \prod_{i=1}^{m}P_G(x^i;\theta ) = arg\ max\ \sum_{i=1}^{m} logP_G(x^i; \theta) \approx arg\ max\ E_{x~P_{data}}[logP_G(x^i; \theta)] = arg\ max \int\limits_{x}P_{data}(x)logP_G(x;\theta )dx - \int \limits_{x}P_{data}(x)logP_{data}(x)dx = arg\ min\ KL(P_{data}||P_G) θ∗=arg maxi=1∏mPG(xi;θ)=arg max logi=1∏mPG(xi;θ)=arg max i=1∑mlogPG(xi;θ)≈arg max Ex Pdata[logPG(xi;θ)]=arg maxx∫Pdata(x)logPG(x;θ)dx−x∫Pdata(x)logPdata(x)dx=arg min KL(Pdata∣∣PG)
(2)、Generator
A generator
G
G
G is a network. The network defines a probability distribution
𝑃
𝐺
𝑃_𝐺
PG.
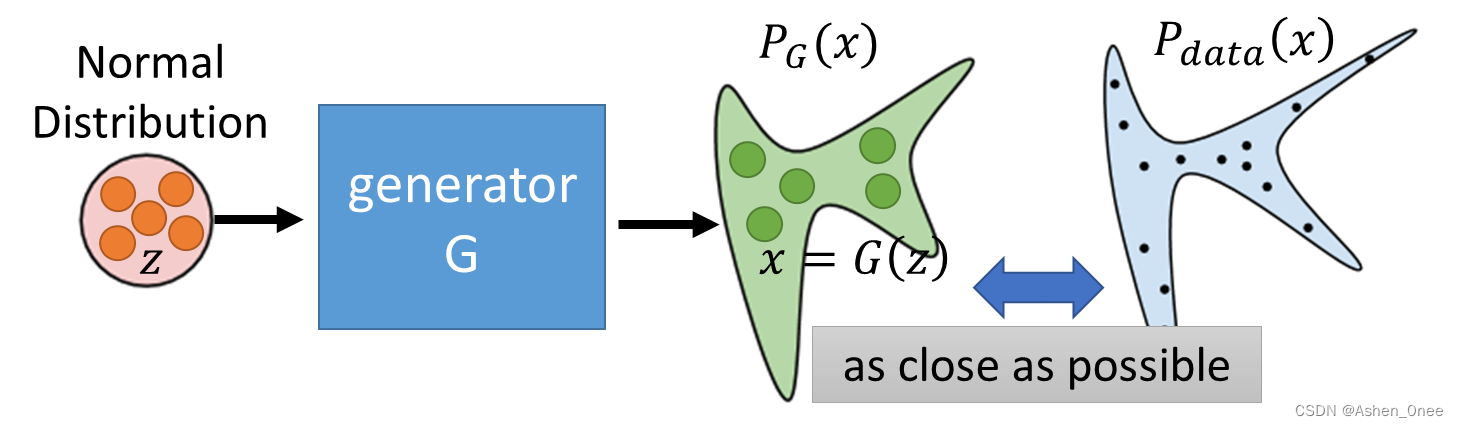
Divergence between distributions
P
G
P_G
PG and
P
d
a
t
a
P_{data}
Pdata:
G
∗
=
a
r
g
m
i
n
D
i
v
(
P
G
,
P
d
a
t
a
)
G^* = arg\ min\ Div(P_G, P_{data})
G∗=arg min Div(PG,Pdata)
(3)、Discriminator
Objective Function for D:
V
(
G
,
D
)
=
E
x
P
d
a
t
a
[
l
o
g
D
(
x
)
]
+
E
x
P
G
[
l
o
g
(
1
−
D
(
x
)
)
]
V(G, D) = E_{x~P_{data}}[logD(x)] + E_{x~P_G}[log(1 - D(x))]
V(G,D)=Ex Pdata[logD(x)]+Ex PG[log(1−D(x))]
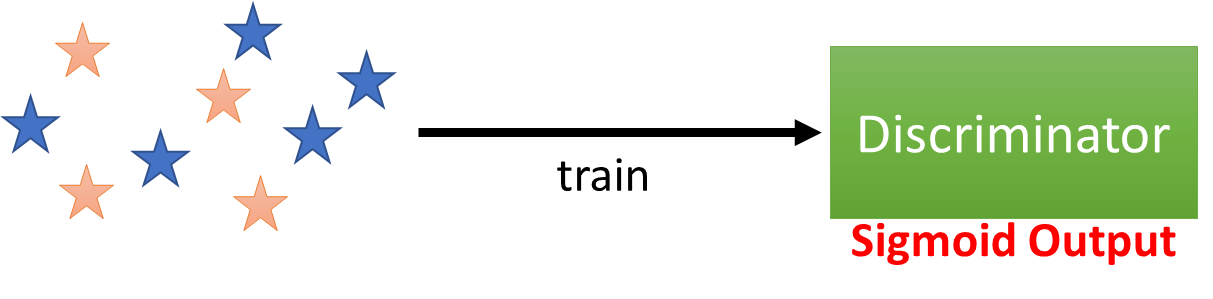
Training:
D
∗
=
a
r
g
m
a
x
V
(
D
,
G
)
D^* = arg\ max\ V(D, G)
D∗=arg max V(D,G)

2、max V(G, D)
- Given
G
G
G, what is the optimal
D
∗
D^*
D∗ maximizing:
V = E x P d a t a [ l o g D ( x ) ] + E x P G [ l o g ( 1 − D ( x ) ) ] = ∫ x [ P d a t a ( x ) l o g D ( x ) + P G ( x ) l o g ( 1 − D ( x ) ) ] d x V = E_{x~P_{data}}[logD(x)] + E_{x~P_G}[log(1 - D(x))]\\ = \int_{x}[P_{data}(x)logD(x) + P_G(x)log(1 - D(x))]dx V=Ex Pdata[logD(x)]+Ex PG[log(1−D(x))]=∫x[Pdata(x)logD(x)+PG(x)log(1−D(x))]dx - **Assume that D(x) can be any function, ** given
x
x
x, the optimal
D
∗
D^*
D∗ maximizing:
P d a t a ( x ) l o g D ( x ) + P G ( x ) l o g ( 1 − D ( x ) ) P_{data}(x)logD(x) + P_G(x)log(1 - D(x)) Pdata(x)logD(x)+PG(x)log(1−D(x))
令:
a = P d a t a ( x ) b = P G ( x ) D = D ( x ) a = P_{data}(x)\quad b = P_G(x)\quad D = D(x) a=Pdata(x)b=PG(x)D=D(x)
Find D ∗ D^* D∗ maximizing: f ( D ) = a l o g ( D ) + b l o g ( 1 − D ) f(D) = alog(D) + blog(1 - D) f(D)=alog(D)+blog(1−D)
d f ( D ) d D = a × 1 D + b × 1 1 − D × ( − 1 ) = 0 D ∗ = a a + b 0 < D ∗ ( x ) = P d a t a ( x ) P d a t a ( x ) + P G ( x ) < 1 D ∗ ( x ) = − 2 l o g 2 + 2 J S D ( P d a t a ∣ ∣ P G ) \frac{df(D)}{dD} = a\times \frac{1}{D} + b\times \frac{1}{1 - D}\times (-1) = 0\\ D^* = \frac{a}{a + b}\\ 0 < D^*(x) = \frac{P_{data}(x)}{P_{data}(x) + P_G(x)} < 1\\ D^*(x) = -2log2 + 2JSD(P_{data} || P_G) dDdf(D)=a×D1+b×1−D1×(−1)=0D∗=a+ba0<D∗(x)=Pdata(x)+PG(x)Pdata(x)<1D∗(x)=−2log2+2JSD(Pdata∣∣PG)
- Jensen-Shannon divergence:
J S D ( P ∣ ∣ Q ) = 1 2 D ( P ∣ ∣ M ) + 1 2 D ( Q ∣ ∣ M ) M = 1 2 ( P + Q ) JSD(P || Q) = \frac{1}{2}D(P || M) + \frac{1}{2}D(Q || M)\\ M = \frac{1}{2}(P + Q) JSD(P∣∣Q)=21D(P∣∣M)+21D(Q∣∣M)M=21(P+Q)
G ∗ = a r g m i n m a x V ( G , D ) D ∗ = a r g m a x V ( D , G ) G^* = arg\ min\ max\ V(G, D)\\ D^* = arg\ max\ V(D, G) G∗=arg min max V(G,D)D∗=arg max V(D,G)
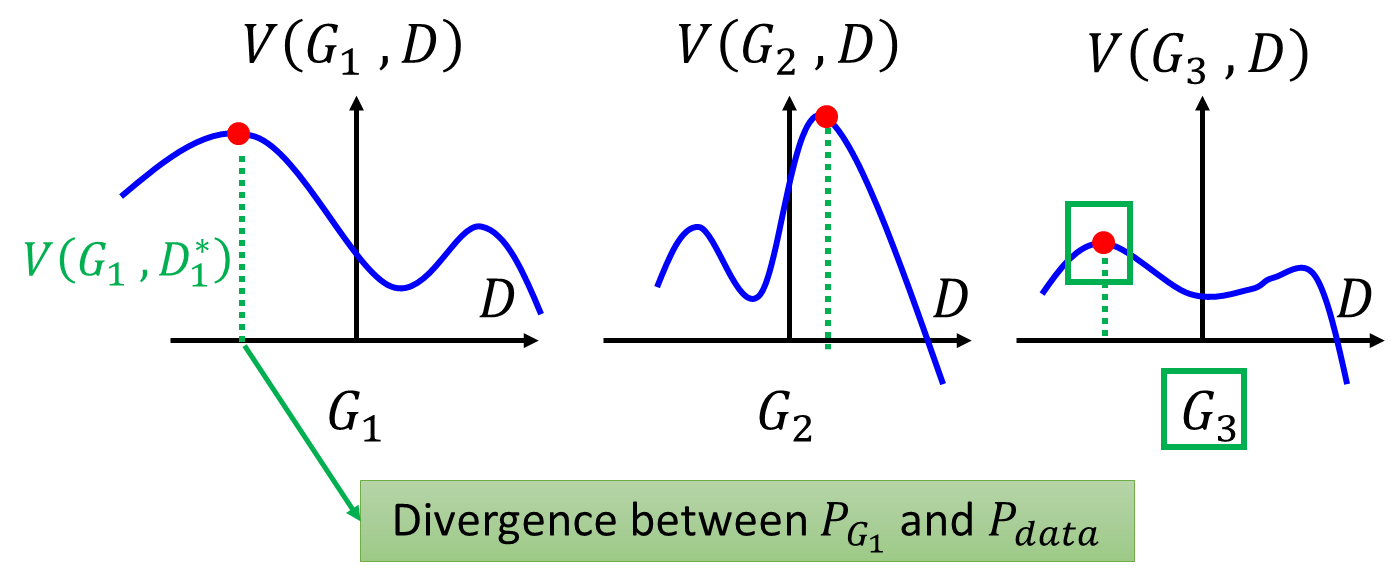
3、Algorithm
- To find the best
G
G
G minimizing the loss function
𝐿
(
𝐺
)
𝐿(𝐺)
L(G):
θ G − η ∂ L ( G ) ∂ θ G → θ G + 1 f ( x ) = m a x { f 1 ( x ) , f 2 ( x ) , f 3 ( x ) } \theta_G - \eta \frac{\partial L(G)}{\partial \theta_G} → \theta_{G + 1}\\ f(x) = max\{f_1(x), f_2(x), f_3(x)\} θG−η∂θG∂L(G)→θG+1f(x)=max{f1(x),f2(x),f3(x)}
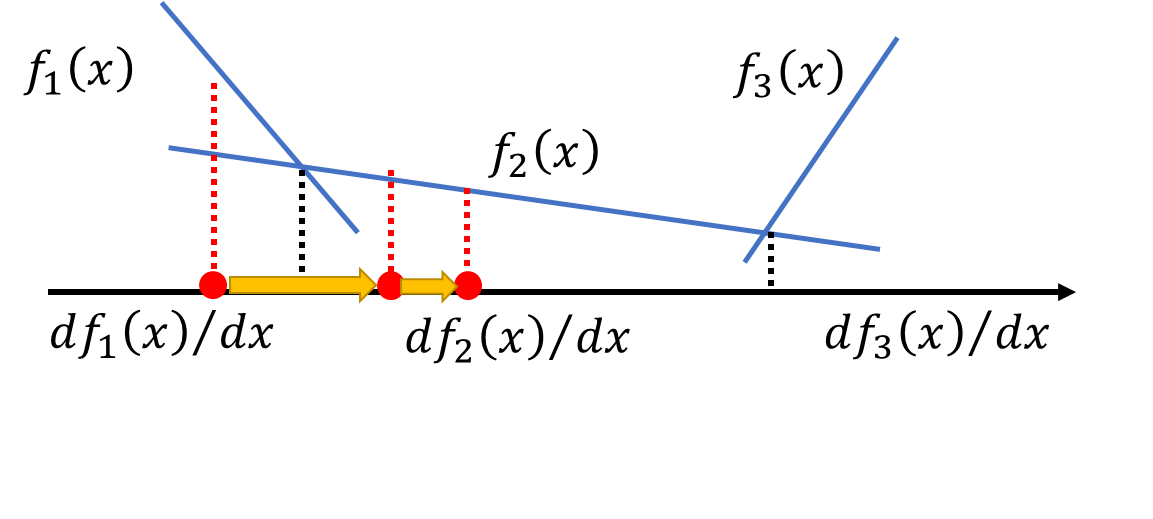
- Given G 0 G_0 G0;
- Find 𝐷 0 ∗ 𝐷_0^∗ D0∗ maximizing 𝑉 ( 𝐺 0 , 𝐷 ) 𝑉(𝐺_0,𝐷) V(G0,D)(gradient ascent);
- θ 0 − η ∂ V ( G , 𝐷 0 ∗ ) ∂ θ G → G 1 \theta_0 - \eta \frac{\partial V(G, 𝐷_0^∗)}{\partial \theta_G} → G_1 θ0−η∂θG∂V(G,D0∗)→G1;
- Find 𝐷 1 ∗ 𝐷_1^∗ D1∗ maximizing 𝑉 ( 𝐺 1 , 𝐷 ) 𝑉(𝐺_1,𝐷) V(G1,D);
二、Framework of GAN
1、f-divergence
𝑃 𝑃 P and 𝑄 𝑄 Q are two distributions. 𝑝 ( 𝑥 ) 𝑝(𝑥) p(x) and q ( 𝑥 ) q(𝑥) q(x) are the probability of sampling 𝑥 𝑥 x. D f ( P ∣ ∣ Q ) D_f(P || Q) Df(P∣∣Q) evaluates the difference of 𝑃 𝑃 P and 𝑄 𝑄 Q.
- f f f is convex;
- f(1) = 0.
D f ( P ∣ ∣ Q ) = ∫ x q ( x ) f ( p ( x ) q ( x ) ) d x D_f(P || Q) = \int_{x} q(x)f(\frac{p(x)}{q(x)})dx Df(P∣∣Q)=∫xq(x)f(q(x)p(x))dx
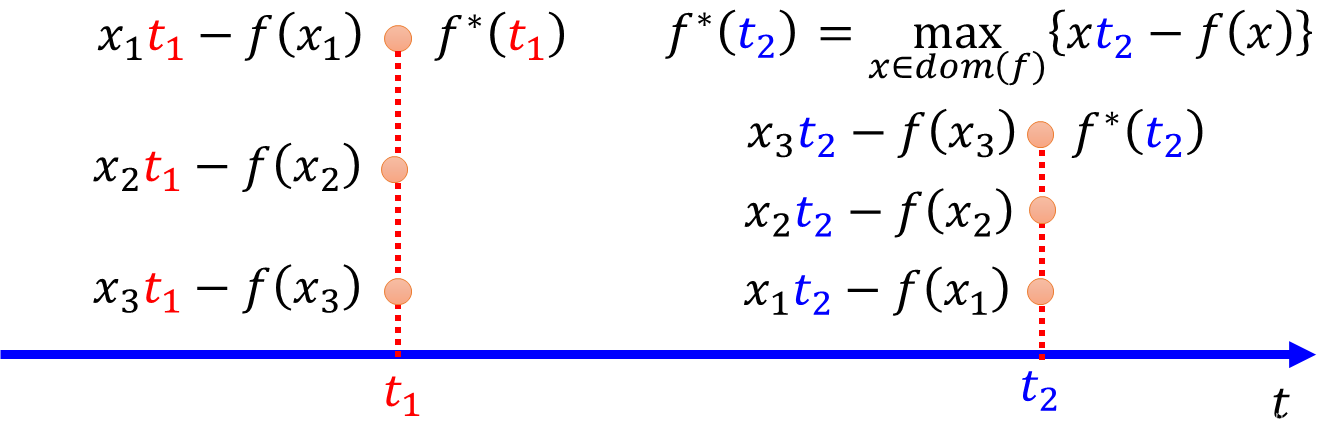
2、Fenchel Conjugate
Every convex function
f
f
f has a conjugate function (共轭函数)
f
∗
f^*
f∗:
f
∗
(
t
)
=
m
a
x
{
x
t
−
f
(
x
)
}
f^*(t) = max\{xt - f(x) \}
f∗(t)=max{xt−f(x)}
三、Tips for Improving GAN
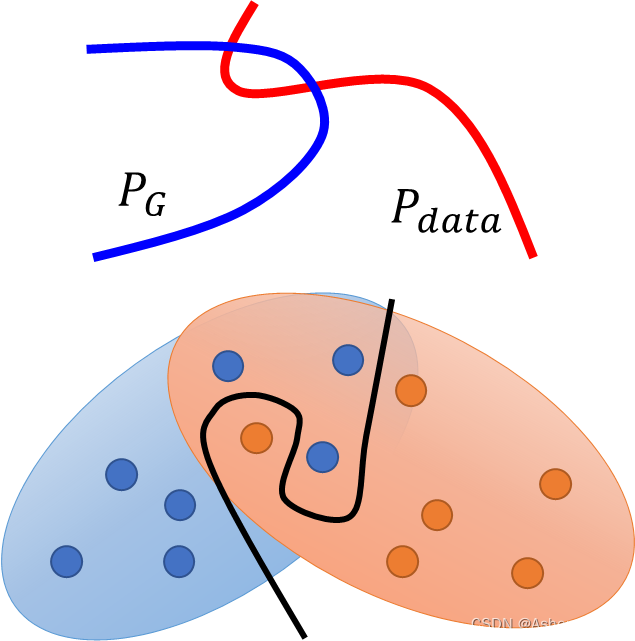
1、JS divergence is not suitable
In most cases,
𝑃
𝐺
𝑃_𝐺
PG and
𝑃
𝑑
𝑎
𝑡
𝑎
𝑃_{𝑑𝑎𝑡𝑎}
Pdata are not overlapped.
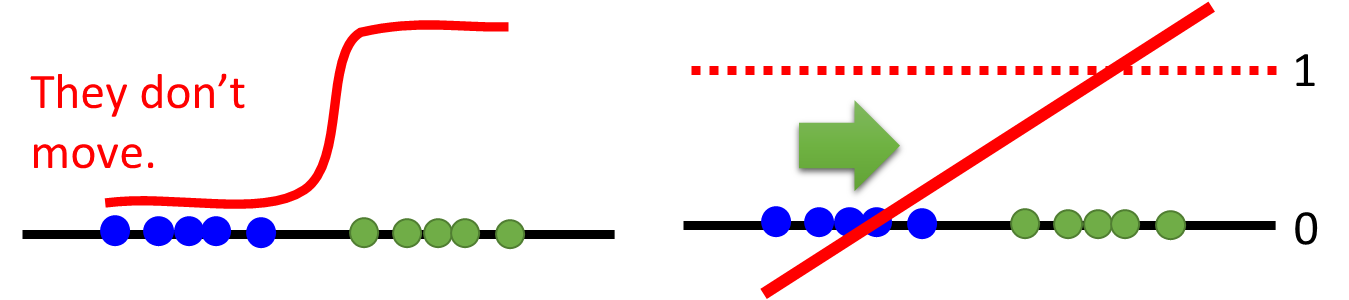
2、Least Square GAN(LSGAN)
Replace sigmoid with linear (replace classification with regression).
3、Wasserstein GAN(WGAN)

A “moving plan” is a matrix. Average distance of a plan
γ
\gamma
γ:
B
(
γ
)
=
∑
x
p
,
x
q
γ
(
x
p
,
x
q
)
∣
∣
x
p
−
x
q
∣
∣
B(\gamma) = \sum_{x_p, x_q} \gamma(x_p, x_q) ||x_p - x_q||
B(γ)=xp,xq∑γ(xp,xq)∣∣xp−xq∣∣
Earth Mover’s Distance:
W
(
P
,
Q
)
=
m
i
n
B
(
γ
)
W(P, Q) = min\ B(\gamma)
W(P,Q)=min B(γ)















 5019
5019











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









