






在本书第二章案例中,用BP神经网络拟合非线性函数,在此基础上用遗传算法对神经网络进行进一步优化。主要优化对象为神经网络的权值与阈值,以此达到更为精准的效果。
本文主要对代码进行解析,书中的实例代码有一些差错,运行不了。本文进行了一些修正,供大家参考。
遗传算法主函数
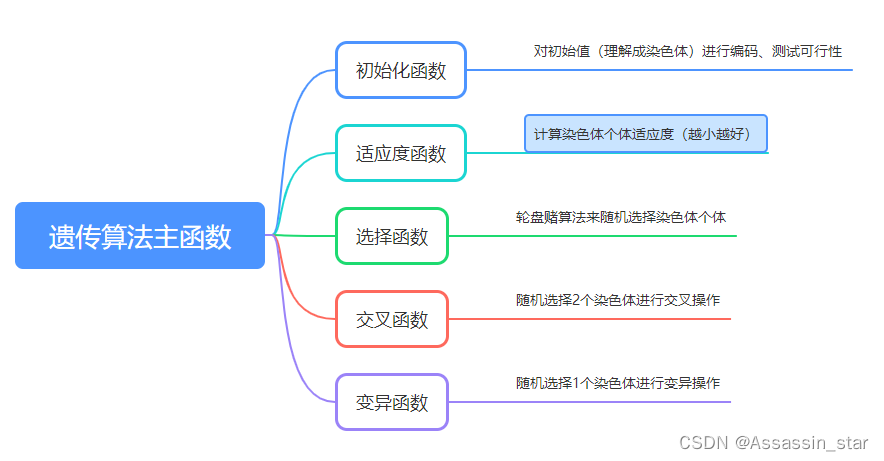
算法大致流程:
一、构建神经网络
%% 网络结构建立
%读取数据
load data input output
%节点个数
inputnum=2;
hiddennum=5;
outputnum=1;
%训练数据和预测数据
input_train=input(1:1900,:)';
input_test=input(1901:2000,:)';
output_train=output(1:1900)';
output_test=output(1901:2000)';
%选连样本输入输出数据归一化
[inputn,inputps]=mapminmax(input_train);
[outputn,outputps]=mapminmax(output_train);
%构建网络
net=newff(inputn,outputn,hiddennum);
二、遗传算法参数初始化
%% 遗传算法参数初始化
maxgen=20; %进化代数,即迭代次数
sizepop=10; %种群规模
pcross=[0.2]; %交叉概率选择,0和1之间
pmutation=[0.1]; %变异概率选择,0和1之间
%节点总数 w1+b1+w2+b2
numsum=inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum;%2*5+5+5*1+1=21
%w1=输入层与隐藏层之间的权值
%b1=隐藏层阈值
%w2=隐藏层与输出层之间的权值
%b2=输出层阈值
%用来进行染色体编码的参数
lenchrom=ones(1,numsum); %染色体长度 1*21行向量(全1
bound=[-3*ones(numsum,1) 3*ones(numsum,1)]; %数据范围[-3 3] 维度21*2
%种群信息初始化
individuals=struct('fitness',zeros(1,sizepop), 'chrom',[]); %将种群信息定义为一个结构体
avgfitness=[]; %每一代种群的平均适应度
bestfitness=[]; %每一代种群的最佳适应度
bestchrom=[]; %适应度最好的染色体三、计算个体适应度
注意理解x中的数据的含义,x(21位)实际上携带w1(1~10位)B1(11~15位)w2(16~20位)B2(第21位)的信息。
对染色体进行寻优的实际意义——找到最优的权值阈值组合。
for i=1:sizepop % 1:10
%个体初始化
individuals.chrom(i,:)=Code(lenchrom,bound); %编码
x=individuals.chrom(i,:);%x为编码后的染色体(携带权值阈值信息)
%计算适应度
individuals.fitness(i)=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn); %染色体的适应度
end
FitRecord=[];%拟合记录
%找最好的染色体(适应度最小)和它的下标
[bestfitness bestindex]=min(individuals.fitness);%最小适应度 及其下标
bestchrom=individuals.chrom(bestindex,:); %最好的染色体 即适应度最小的
avgfitness=sum(individuals.fitness)/sizepop; %染色体的平均适应度
trace=[avgfitness bestfitness]; % 记录初代平均适应度和最优适应度四、迭代寻优
整个算法的核心,也是最难理解的地方。本章先对主函数进行分析,其中的选择、交叉、变异函数接下来逐步详细讲解。
%% 迭代求解最佳初始阀值和权值
% 进化开始
for i=1:maxgen %迭代20代
%选择
individuals=Select(individuals,sizepop);
%交叉
individuals.chrom=Cross(pcross,lenchrom,individuals.chrom,sizepop,bound);
%变异
individuals.chrom=Mutation(pmutation,lenchrom,individuals.chrom,sizepop,i,maxgen,bound);
% 计算适应度
for j=1:sizepop
x=individuals.chrom(j,:);
individuals.fitness(j)=fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn);
end
%找到这一代最优和最差适应度的染色体及它们在种群中的位置
[newbestfitness,newbestindex]=min(individuals.fitness);
[worestfitness,worestindex]=max(individuals.fitness);
%代替上一次进化中最好的染色体
if bestfitness>newbestfitness %优胜
bestfitness=newbestfitness;
bestchrom=individuals.chrom(newbestindex,:);
end
%劣汰 淘汰适应度最差的染色体 用最优的取代
individuals.chrom(worestindex,:)=bestchrom;
individuals.fitness(worestindex)=bestfitness;
avgfitness=sum(individuals.fitness)/sizepop;
trace=[trace;avgfitness bestfitness]; %记录每一代进化的平均适应度和最优适应度 21代(加初代
FitRecord=[FitRecord;individuals.fitness];%记录每一代拟合后的适应度 共20代
end遗传算法结果展示 :
figure(1)
hold on
[r c]=size(trace);
plot([1:r],trace(:,1),'r-');%平均适应度
plot([1:r],trace(:,2),'b--');%trace(:,2) 第二列为最优适应度
title(['适应度曲线' '(终止代数=' num2str(maxgen)],'fontsize',12);
xlabel('进化代数','fontsize',12);ylabel('适应度','fontsize',12);
legend('平均适应度','最佳适应度');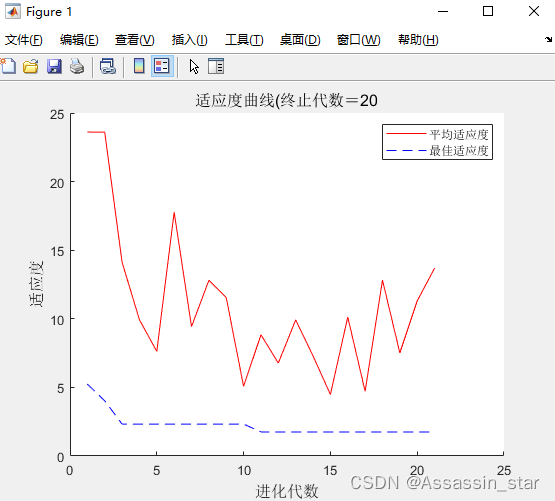
五、遗传算法优化BP神经网络
%% 把最优初始阀值权值赋予网络预测
x=bestchrom;%迭代后的最优染色体赋给x
w1=x(1:inputnum*hiddennum);%x(1:10)
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);%x(11:15)
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);%x(16:20)
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);%x(21)
%% BP网络参数设置
net.iw{1,1}=reshape(w1,hiddennum,inputnum);
net.lw{2,1}=reshape(w2,outputnum,hiddennum);
net.b{1}=reshape(B1,hiddennum,1);
net.b{2}=B2;
net.trainParam.epochs=100;
net.trainParam.lr=0.1;
net.trainParam.goal=0.00001;
%% BP网络训练
[net,per2]=train(net,inputn,outputn);
%% BP网络预测
inputn_test=mapminmax('apply',input_test,inputps);%数据归一化
an=sim(net,inputn_test);%预测输出
test_simu=mapminmax('reverse',an,outputps);%反归一化后的预测输出
error=test_simu-output_test;%误差=预测输出-期望输出
优化后的BP神经网络预测结果展示:
figure(2)
plot(test_simu,':og')
hold on
plot(output_test,'-*')
legend('预测输出','期望输出')
title('GA优化后的BP网络预测输出','fontsize',12)
ylabel('函数输出','fontsize',12);xlabel('样本','fontsize',12)
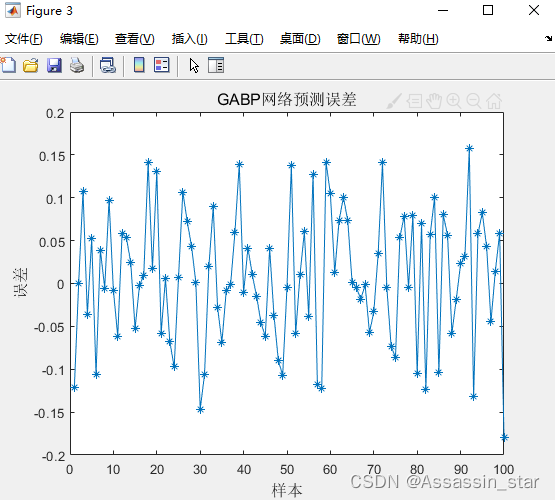
figure(3)
plot(error,'-*')
title('GABP网络预测误差','fontsize',12)
ylabel('误差','fontsize',12);xlabel('样本','fontsize',12)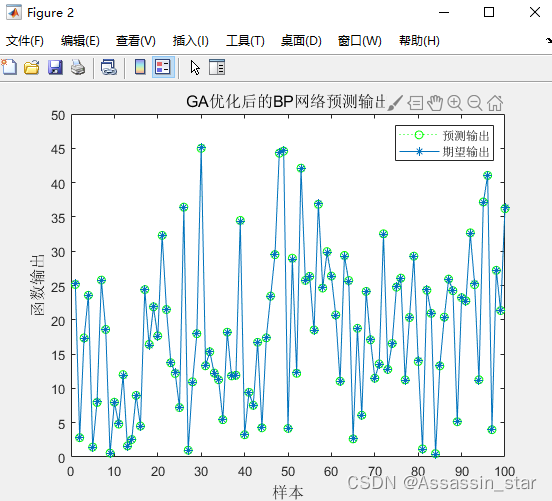
初始化函数
一、编码函数
编码函数对神经网络的权值和阈值信息进行编码,代码如下:
function ret=Code(lenchrom,bound)
%本函数将变量编码成染色体,用于随机初始化一个种群
% lenchrom input : 染色体长度
% bound input : 变量的取值范围
% ret output: 染色体的编码值
flag=0;
while flag==0
pick=rand(1,length(lenchrom));%随机数 1*21
ret=bound(:,1)'+(bound(:,2)-bound(:,1))'.*pick; %线性插值,编码结果以实数向量存入ret中
flag=test(lenchrom,bound,ret); %检验染色体的可行性 flag=1可行、结束循环 flag=0再循环
end二、测试函数
测试编码后的染色体是否可行,flag为1时可行,flag为0时不可行:
function flag=test(lenchrom,bound,code)
% lenchrom input : 染色体长度
% bound input : 变量的取值范围
% code output: 染色体的编码值
x=code;
flag=1;
if (x(1)<0)&&(x(2)<0)&&(x(3)<0)&&(x(1)>bound(1,2))&&(x(2)>bound(2,2))&&(x(3)>bound(3,2))
flag=0;
end 适应度函数
在遗传算法中,适应度(fitness)的具体含义取决于问题的性质。一般而言,适应度越大越好是常见的情况,因为遗传算法的目标通常是优化问题,即找到问题的最优解或接近最优解的解。
例如,如果遗传算法用于解决最大化问题(如最大化某个函数的值),那么个体的适应度值越大,说明该个体的性能越好。相反,如果遗传算法用于解决最小化问题(如最小化成本或误差),那么个体的适应度值越小,说明该个体的性能越好。
总体而言,适应度的选择应该与问题的优化目标相一致,以便遗传算法能够有效地搜索解空间并找到问题的良好解。下面对适应度函数代码进行分析:
function error = fun(x,inputnum,hiddennum,outputnum,net,inputn,outputn)
%该函数用来计算适应度值
%x input 个体(染色体:包含权值阈值信息)
%inputnum input 输入层节点数
%outputnum input 隐含层节点数
%net input 网络
%inputn input 训练输入数据
%outputn input 训练输出数据
%error output 个体适应度值
%提取
w1=x(1:inputnum*hiddennum);%输入层与隐含层的权值 x(1:10)
B1=x(inputnum*hiddennum+1:inputnum*hiddennum+hiddennum);%隐含层的阈值 x(11:15)
w2=x(inputnum*hiddennum+hiddennum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum);%隐含层与输出层的权值 x(16:20)
B2=x(inputnum*hiddennum+hiddennum+hiddennum*outputnum+1:inputnum*hiddennum+hiddennum+hiddennum*outputnum+outputnum);
%输出层阈值 x(21:21)
%网络进化参数
net.trainParam.epochs=20;%迭代次数
net.trainParam.lr=0.1;%学习率
net.trainParam.goal=0.00001;%目标函数 最小误差函数
net.trainParam.show=100;%显示训练迭代过程
net.trainParam.showWindow=0;%显示训练窗口
%网络权值/阈值赋值
net.iw{1,1}=reshape(w1,hiddennum,inputnum);%iw{1,1} i-h间的权值 5*2
net.lw{2,1}=reshape(w2,outputnum,hiddennum);%iw{2,1} h-o间的权值 1*5
net.b{1}=reshape(B1,hiddennum,1);%隐含层阈值 B1 5*1
net.b{2}=B2;%输出层阈值
%网络训练
net=train(net,inputn,outputn);
an=sim(net,inputn);%an为预测输出
error=sum(abs(an-outputn));%适应度(越小越好)由最后一行代码可见,遗传算法中的适应度为:神经网络的预测输出与期望输出差值的绝对值之和。
选择函数
选择函数涉及到概率论中的轮盘赌问题。轮盘赌是什么呢?听起来很复杂,其实很简单。相信大家都参加过超市的优惠活动,让你转转盘的指针,转盘上有各种奖项。一等奖的扇形区域很小,其余奖项的扇形区域面积逐渐增大。所以当你转动指针,大概率会停在低等奖的区域(因为它所占面积相较于其他奖更大)。
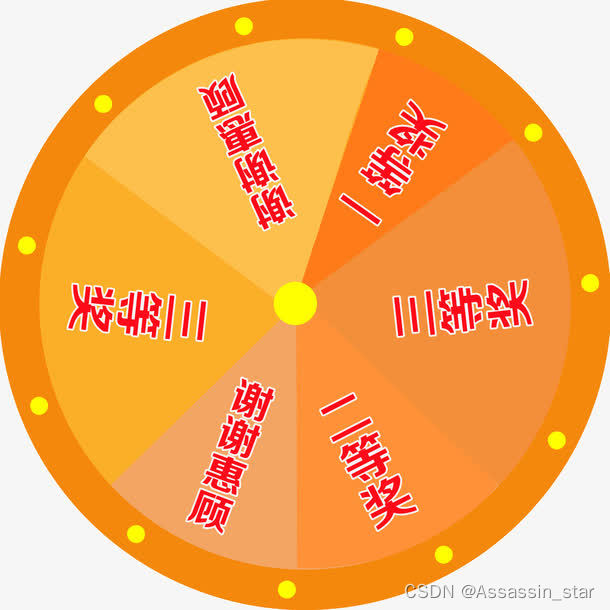
而遗传算法的选择函数,要选择适应度好的个体进入下一轮操作(交叉、变异)。因此采用这种转轮盘的方式随机选择染色体,适应度越好,那么该染色体被选中的概率也就越大。
function ret=select(individuals,sizepop)
% 本函数对每一代种群中的染色体进行选择,以进行后面的交叉和变异
% individuals input : 种群信息
% sizepop input : 种群规模
% ret output : 经过选择后的种群
%根据个体适应度值进行排序
fitness1=10./individuals.fitness;%由于适应度越小越好 对每个适应度求倒数 k为系数=10
sumfitness=sum(fitness1);%求和
p=fitness1./sumfitness;%每个个体的选择概率(概率之和为1)
%轮盘赌法选择新个体
index=[]; %j的值 选中的个体下标
for i=1:sizepop %转sizepop(10次轮盘
pick=rand;%返回一个在区间 (0,1) 内均匀分布的随机数
for j=1:sizepop
pick=pick-p(j); %这一步就是转轮盘
if pick<=0 %对应指针停下
index=[index j]; %寻找指针停下的区间,此次转轮盘选中了第j个染色体
break;
%注意:在转sizepop次轮盘的过程中,有可能会重复选择某些染色体
end
end
end
%更新种群信息(选中的染色体及其适应度)
individuals.chrom=individuals.chrom(index,:);
individuals.fitness=individuals.fitness(index);
ret=individuals;算法中,pick=pick-p(j) 这句的理解很关键。画个图大家就明白为啥这一步操作就是转轮盘了。把圆盘区域拉成一条线段,区域面积映射在线段上。pick是随机数,该随机数作累减操作,当pick=0时,它就落在了线段中某个区域里(相当于指针停下),这就完成了随机选择染色体。从图直观可见概率为0.4的染色体被选中的概率最大。
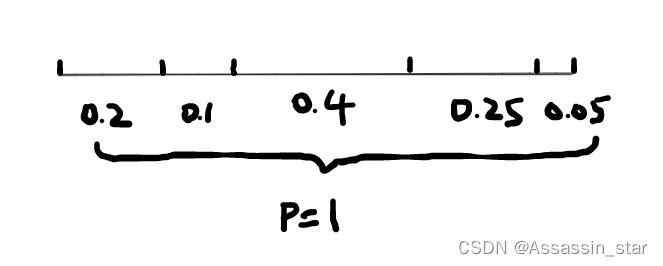
该算法中实际p的可视化图:
交叉函数
function ret=Cross(pcross,lenchrom,chrom,sizepop,bound)
%本函数完成交叉操作
% pcorss input : 交叉概率
% lenchrom input : 染色体的长度
% chrom input : 染色体群
% sizepop input : 种群规模
% ret output : 交叉后的染色体
for i=1:sizepop % 1:10
%每一轮for循环中,可能会进行一次交叉操作,染色体是随机选择的,交叉位置也是随机选择的,
%但该轮for循环中是否进行交叉操作则由交叉概率决定(continue控制)
% 随机选择两个染色体进行交叉
pick=rand(1,2);
index=ceil(pick.*sizepop);%随机选取2个染色体来进行交叉
% 交叉概率决定是否进行交叉
pick=rand;
if pick>pcross
continue;
end
flag=0;
while flag==0
% 随机选择交叉位
pick=rand;
% while pick==0
% pick=rand;
% end
%随机选择进行交叉的位置,即选择第几个变量进行交叉,注意:两个染色体交叉的位置相同
pos=ceil(pick.*sum(lenchrom));%要进行交叉的染色体元(21位)的位置
% temp=chrom(index(1),pos); %两元素调换位置
% chrom(index(1),pos)=chrom(index(2),pos);
% chrom(index(2),pos)=temp;
pick=rand; %交叉开始
v1=chrom(index(1),pos);%(随机选取的第一个染色体,对应元的位置)
v2=chrom(index(2),pos);%(随机选取的第二个染色体,对应元的位置)
%实数交叉法
chrom(index(1),pos)=pick*v2+(1-pick)*v1;
chrom(index(2),pos)=pick*v1+(1-pick)*v2; %交叉结束
flag1=test(lenchrom,bound,chrom(index(1),:)); %检验染色体1的可行性
flag2=test(lenchrom,bound,chrom(index(2),:)); %检验染色体2的可行性
if flag1*flag2==0
flag=0;
else flag=1;
end %如果两个染色体不是都可行,则重新交叉
end
end
ret=chrom;
变异函数
与交叉函数对应,基本思路是一致的。
function ret=Mutation(pmutation,lenchrom,chrom,sizepop,num,maxgen,bound)
% 本函数完成变异操作
% pmutation input : 变异概率
% lenchrom input : 染色体长度
% chrom input : 染色体群
% sizepop input : 种群规模
% num input : 当前迭代次数
% maxgen input :最大迭代次数
% bound input : 每个个体的上界和下界
% ret output : 变异后的染色体
for i=1:sizepop %每一轮for循环中,可能会进行一次变异操作,染色体是随机选择的,变异位置也是随机选择的,
%但该轮for循环中是否进行变异操作则由变异概率决定(continue控制)
% 随机选择一个染色体进行变异
pick=rand;
index=ceil(pick*sizepop);%随机选择1个染色体进行变异
% 变异概率决定该轮循环是否进行变异
pick=rand;
if pick>pmutation
continue;
end
flag=0;
while flag==0
pick=rand;
pos=ceil(pick*sum(lenchrom)); %随机选择了染色体变异的位置,即选择了第pos个变量进行变异
%变异开始
pick=rand;
fg=(rand*(1-num/maxgen))^2; %num为遗传算法当前迭代次数 maxgen为总迭代次数
if pick>0.5
chrom(index,pos)=chrom(index,pos)+(chrom(index,pos)-bound(pos,2))*fg;
else
chrom(index,pos)=chrom(index,pos)+(bound(pos,1)-chrom(index,pos))*fg;
end
%变异结束
flag=test(lenchrom,bound,chrom(index,:)); %检验变异的染色体的可行性
end
end
ret=chrom;ENDING
以主函数算法流程为基础,仔细分析每一个子函数作用,通过调试代码来加深理解,才能对整个算法流程有全面的认知。代码的实验数据来自《MATLAB神经网络43个案例分析》。本文是个人学习记录,以便回顾复习。若有错误之处,请大家指正。















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









