







大家好,我是 同学小张,+v: jasper_8017 一起交流,持续学习AI大模型应用实战案例,持续分享,欢迎大家点赞+关注,订阅我的大模型专栏,共同学习和进步。
在人工智能领域,大模型生成的效果往往和输入的提示词(Prompt)质量密切相关。如何设计出高质量的提示词,已成为提升模型性能的关键。MetaGPT通过引入SPO策略(Sequential Prompt Optimization),为我们提供了一套高效且自动的提示词优化方案,让我们在多轮迭代中不断提升生成效果。
今天,我们就来深入探讨MetaGPT的SPO提示词优化策略,解析其背后的流程,并通过代码实例解析深入了解这一提示词自动优化策略。
1. 什么是SPO策略?
SPO(Self-Supervised Prompt Optimization)是一种多轮优化策略,它通过逐步调整和优化提示词,使得模型能够更好地理解和生成符合要求的输出。在每一轮优化中,系统都会根据上轮的输出,调整提示词,并评估其效果。最终,经过多轮迭代,模型将输出一个最优的结果。
2. SPO策略的工作流程
SPO策略的核心流程包括三个重要的任务:
- 优化提示词:用来根据现有提示词生成更好的版本。
- 评估模型:用来判断优化后的提示词是否提高了输出质量。
- 执行模型:用来根据优化后的提示词生成输出。
这三个模型分别负责不同的任务,通过密切协作来不断提升提示词的质量。
2.1 优化模型
在每一轮优化中,SPO策略会根据前一轮的最佳提示词和答案,通过优化模型来生成新的提示词。优化模型的目标是让提示词更好地满足用户需求,从而生成更优质的输出。
2.2 评估模型
每一轮生成的新提示词都会交由评估模型来进行评估。评估模型会判断新生成的答案是否更符合要求。如果新生成的答案比原先的答案更好,那么新提示词就被认为是有效的,并进入下一轮优化;反之,则继续使用原有提示词。
2.3 执行模型
执行模型的任务是根据优化后的提示词生成最终的答案。这一过程决定了优化的效果是否能够在实际应用中得到体现。
3. 关键代码解析
在MetaGPT中,SPO策略的实现通过PromptOptimizer类来完成,以下是一些关键代码段及其解释:
3.1 初始化优化任务
SPO_LLM.initialize(
optimize_kwargs={
"model": args.opt_model, "temperature": args.opt_temp},
evaluate_kwargs={
"model": args.eval_model, "temperature": args.eval_temp},
execute_kwargs={
"model": args.exec_model, "temperature": args.exec_temp},
)
在这段代码中,初始化三个不同的模型:优化模型、评估模型和执行模型。每个模型的参数(如温度)可以根据需求进行调整。
demo文件:MetaGPT/examples/spo/optimize.py
3.2 优化函数
optimizer = PromptOptimizer(
optimized_path=args.workspace,
initial_round=args.initial_round,
max_rounds=args.max_rounds,
template=args.template,
name=args.name,
)
optimizer.optimize()
PromptOptimizer类负责执行整个优化过程。通过optimize()方法,它会开始进行多轮优化,每一轮都会生成新的提示词,并对其进行评估与调整。
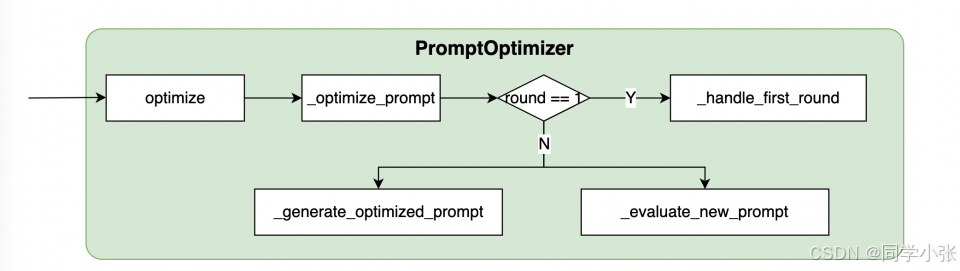
每一轮执行函数如下:self._optimize_prompt() 函数
async def _optimize_prompt(self):
prompt_path = self.root_path / "prompts"
load.set_file_name(self.template)
data = self.data_utils.load_results(prompt_path)
if self.round == 1:
await self._handle_first_round(prompt_path, data)
return
directory = self.prompt_utils.create_round_directory(prompt_path, self.round)
new_prompt = await self._generate_optimized_prompt()
self.prompt = new_prompt
logger.info(f"\nRound {
self.round} Prompt: {
self.prompt}\n")
self.prompt_utils.write_prompt(directory, prompt=self.prompt)
success, answers = await self._evaluate_new_prompt(prompt_path, data, directory)
self._log_optimization_result(success)
return self.prompt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











