







1.环境部署简述
Coder部署分为两块部分:Pytorch和transformers
前者网上一堆教程就省去了,后者使用pip install transformers
1.1.模型下载
此网站被限制访问,需要科学上网。
https://huggingface.co/deepseek-ai/deepseek-math-7b-base
1.1.1. git同步下载
Windows需要提前安装git。
git lfs install
git clone https://huggingface.co/deepseek-ai/deepseek-math-7b-base
1.1.2.手动下载
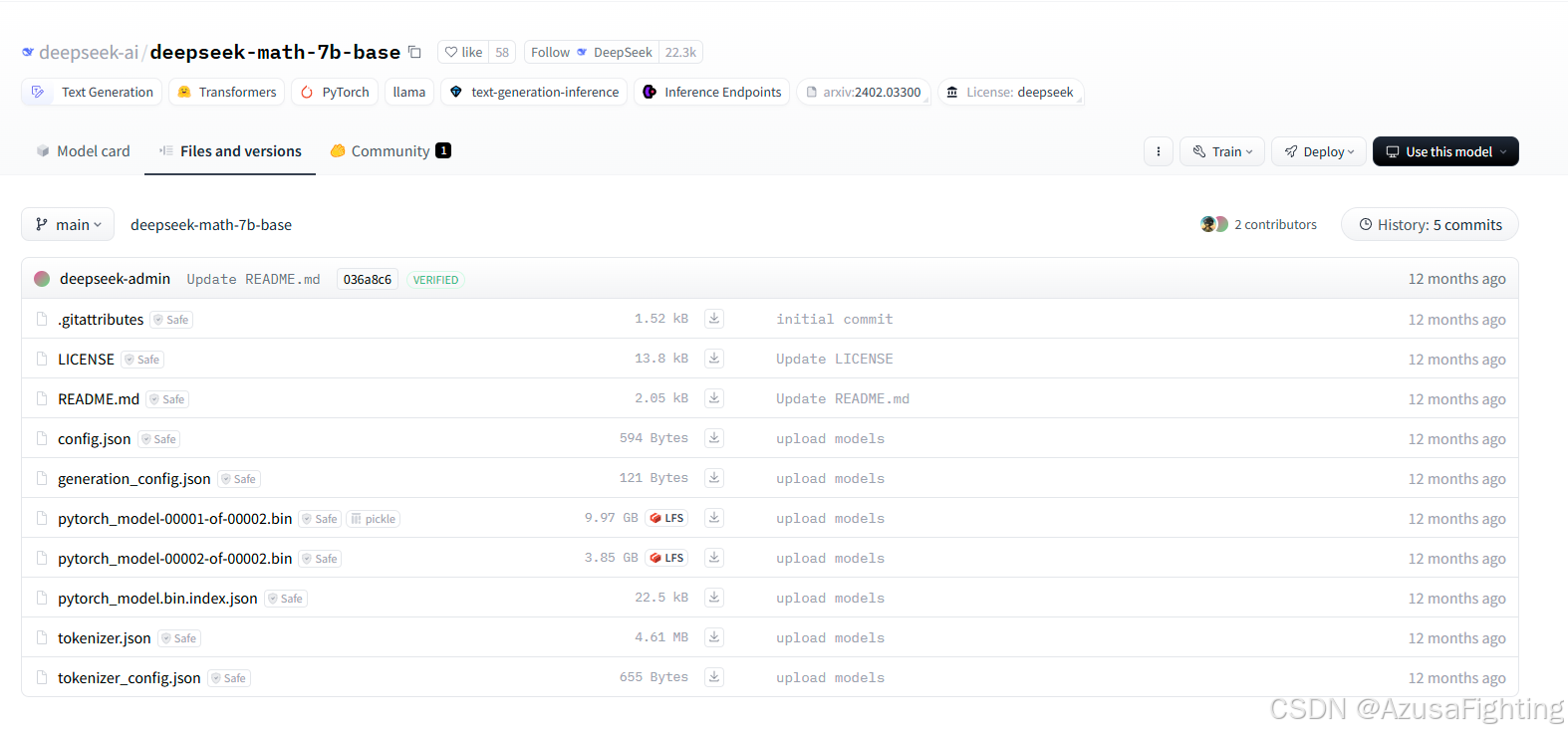
下载地址:https://huggingface.co/deepseek-ai/deepseek-math-7b-base/tree/main
进入该网址进行下载。
2.使用环境
Windows 11 + Intel 6C12T + Nvidia 12GB
Python 3.9
Pytorch 2.5.1+cu118
PyCharm 2023.2.1
可与Yolo共存于同一个环境中
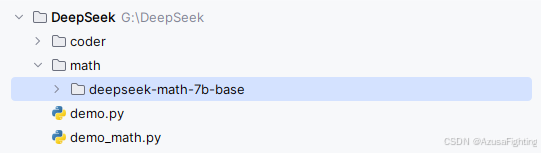
2.1.工程摆放路径
3.推理测试代码
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "./math/deepseek-math-7b-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "The integral of x^2 from 0 to 2 is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
4.测试结果

5.后续更新所提供的进阶思路
后续本人将搭建一个致力于构建一个解决数学问题的助手。
5.1.搭建具备GUI的ChatBox
5.2.对现有模型进行进一步训练
5.3.实现麦克风语音转文本功能并接入该输入部分
5.4.根据输出文本实现相对应的功能
6. 总结
该模型用于解决数学问题,7B参数与Float16的前提下,测试官方案例占用显存容量在9.5G至10.2G的情况。
使用GPU加速回答时间基本上控制在10-30秒附近。


















 2041
2041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











