






遗传算法配送中心选址问题matlab求解
可以修改需求点坐标,需求点的需求量,备选中心坐标,配送中心个数
注:2≤备选中心≤20,需求点中心可以无限个
YID:999781746291066
口合口合娃^-^
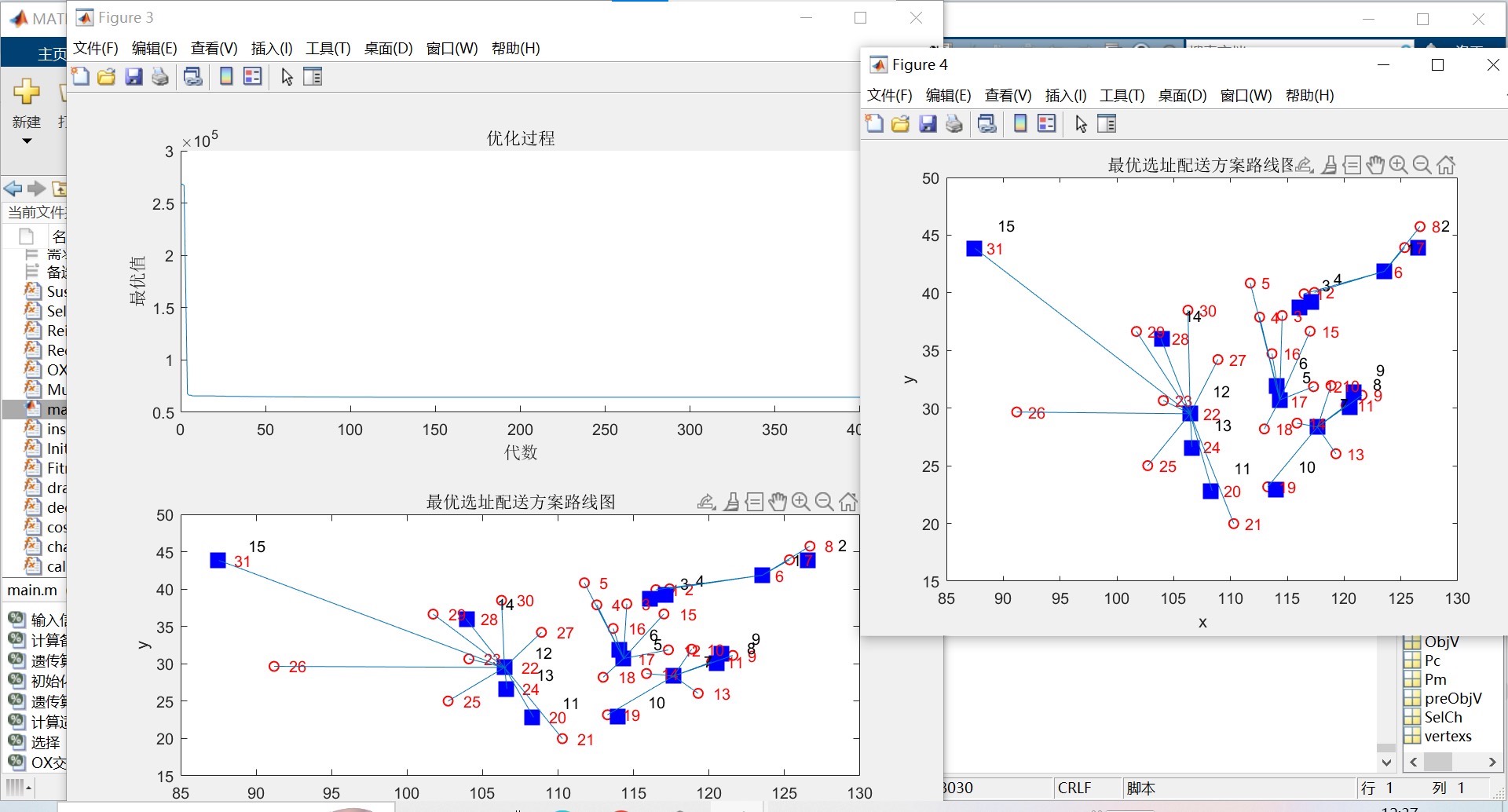
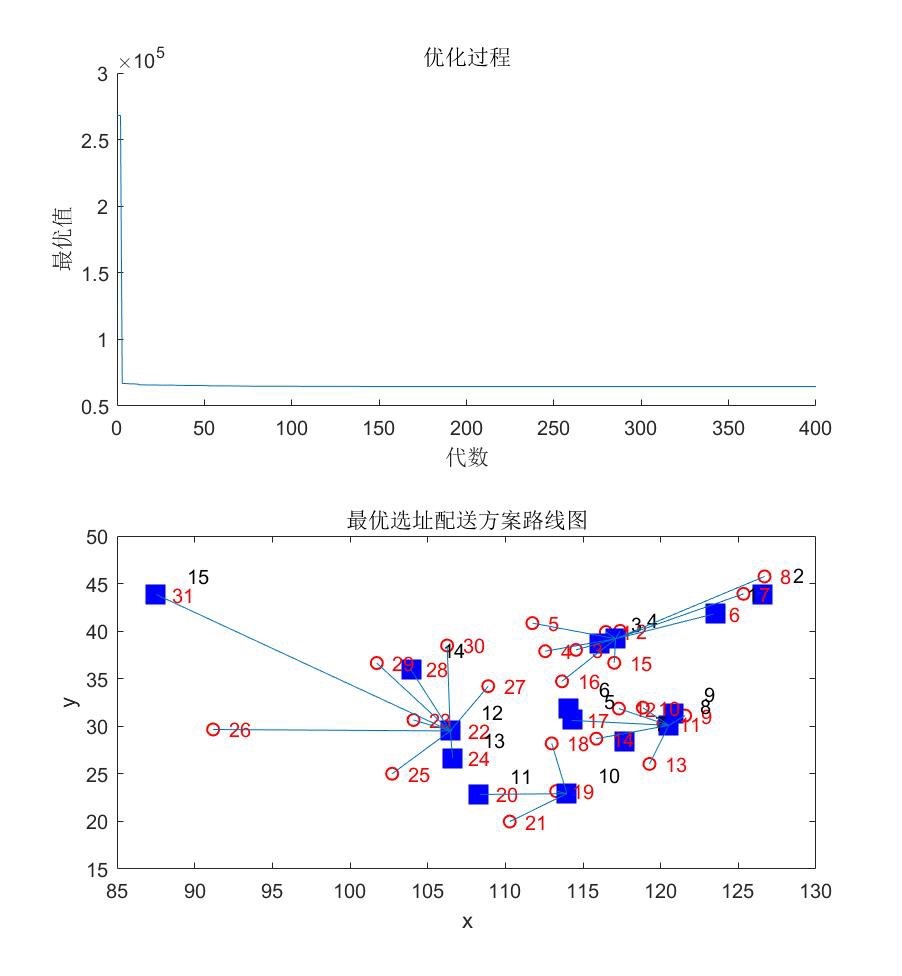
遗传算法是一种基于自然进化原理的优化算法,在许多实际问题中都表现出了良好的效果。其中,配送中心选址问题是一个具有一定难度和复杂性的问题,它在物流领域中具有重要的意义。本文将介绍使用遗传算法来解决配送中心选址问题,并使用Matlab进行求解。
配送中心选址问题的目标是在给定的区域内选择一定数量的配送中心,并确定它们的位置,以满足需求点的需求量。在实际应用中,需求点和备选中心的坐标以及需求量都是可以修改的。备选中心的个数范围为2至20,而需求点的中心个数则可以是无限个。
遗传算法是一种模拟生物进化过程的优化算法,它通过模拟进化的几个基本操作(选择、交叉和变异),逐步优化解的质量。在本问题中,可以将备选中心的位置和需求点的分配看作是解的基因型,并通过遗传算法来搜索最优解。
首先,需要定义适应度函数来评价每个解的质量。适应度函数可以考虑多个因素,比如配送距离、需求满足率等。然后,初始化种群并进行适应度计算。接着,通过选择、交叉和变异操作对种群进行遗传操作,生成新的子代种群。在遗传操作中,选择操作用于选择适应度较高的个体作为父代,交叉操作用于生成新的子代,变异操作用于引入新的基因组合。重复进行适应度计算和遗传操作,直到满足终止条件(比如迭代次数达到一定值)为止。
在使用遗传算法求解配送中心选址问题时,需要进行一些问题特定的处理。首先,需要根据具体问题设定合适的遗传算法参数,比如种群大小、交叉率和变异率等。其次,需要根据问题的实际情况设计适应度函数,考虑到配送距离、需求满足率和备选中心数量等因素。此外,还可以根据问题的特点设计一些专门的遗传操作,比如在选择操作中引入轮盘赌选择算法,或者在变异操作中引入局部搜索策略。
在使用Matlab来实现遗传算法求解配送中心选址问题时,可以利用Matlab提供的优化工具箱和遗传算法工具箱。通过编写相应的代码,可以方便地实现种群初始化、适应度计算和遗传操作等功能。在编写代码时,需要注意代码的可读性和可扩展性,以便后续的调试和优化工作。
通过使用遗传算法和Matlab求解配送中心选址问题,可以得到一组满足需求的最优解。然而,需要注意的是,遗传算法是一种启发式算法,无法保证一定能够找到全局最优解。因此,在实际应用中,需要综合考虑问题的实际情况和计算资源的限制,选择合适的算法和求解方法。
综上所述,遗传算法配送中心选址问题是一个具有一定难度和复杂性的问题,但利用遗传算法和Matlab可以有效地求解。通过合理地定义适应度函数、设置遗传算法参数和设计遗传操作,可以得到满足需求的最优解。在实际应用中,需要根据具体问题的特点和要求,进行相应的调整和优化,以得到更加准确和有效的结果。
相关的代码,程序地址如下:http://lanzoup.cn/781746291066.html
















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









