







本文来源公众号“江大白”,仅用于学术分享,侵权删,干货满满。
原文链接:万字长文,搞懂 AI 大模型的技术原理!
导读
大模型作为现今人工智能的研究热点,究竟是基于什么原理呢。本文从LIama 3报告出发,整理了一些现代LLM技术,囊括了从预训练到推理全流程的技术要点,赶紧收藏阅读吧。
本文从 Llama 3报告出发,基本整理一些现代LLM的技术。
'基本',是说对一些具体细节不会过于详尽,而是希望得到一篇相对全面,包括预训练,后训练,推理,又能介绍清楚一些具体技术,例如RM,DPO,KV Cache,GQA,PagedAttention,Data Parallelism等等的索引向文章。
由于东西比较多,且无法详尽细节,所以推荐大家二次整理为自己的笔记。
本文的主要参考是Llama Team的The Llama 3 Herd of Models报告原文,以及沐神回归B站新出的论文精读系列。同时也包括一些知乎的优秀文章。
1、简介
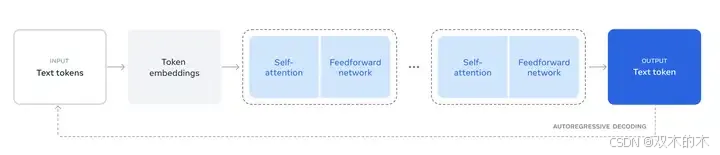
Illustration of the overall architecture and training of Llama 3

Overview of the Llama 3 Herd of models.
1.1 现代基础模型训练的主要阶段
(a)预训练阶段(pre-training stage):算法相对直接,一般是用大量的数据去做下一个词的预测(next-word prediction)。
(b)后训练阶段(post-training stage):算法比较丰富,包括SFT,RLHF,DPO等等。任务上看,包括让模型做一些指令跟随的任务(instruction following),将模型偏好对齐到人类喜好上(align with human preferences),或者提高模型在特定任务的能力,例如code,math,roleplay等等。
从过去的模型看,基本上可以认为GPT1,2,3都是在做pre-training,而InstructGPT和RLHF则是在做post-training。以上是较为笼统的介绍。
1.2 现代基础模型训练的关键
Meta:We believe there are three key levers in the development of high-quality foundation models: data, scale, and managing complexity.
meta认为现代基础模型训练的关键是:data, scale, and managing complexity。
(a)关于data ,Llama系列有堆数据的传统:相较于Llama 2 1.8T的预训练语料,Llama 3的预训练语料堆到了15T的multilingual tokens。
沐神:15个T可能是目前在公有的网络上面,能够抓到的文本数据的一个大概的上限,这个'上限'的意思是指,与其再找一些增量的数据,不如去调整现有的数据的质量。
(b)关于scale,Llama 3.1提供了8B,70B,405B三个规模。每个规模的性能差异可参考下面的benchmark。
(c)关于managing complexity,复杂度管理,说白了即Llama 3的算法相对简单。Llama 3选择了一个标准的稠密Transformer模型架构,只进行了少量调整,而没有选择MOE。后训练方面,Llama 3采用了SFT、RS和DPO,即一套'相对简单'的过程,而不是更复杂的RLHF算法,因为后者往往稳定性较差且更难以扩展。这些都属于design choice。2,3章会详细介绍相关技术。
1.3 benchmark表现
Llama 3各规格模型的benchmark表现如下。简要介绍其中的MMLU和IFEval。
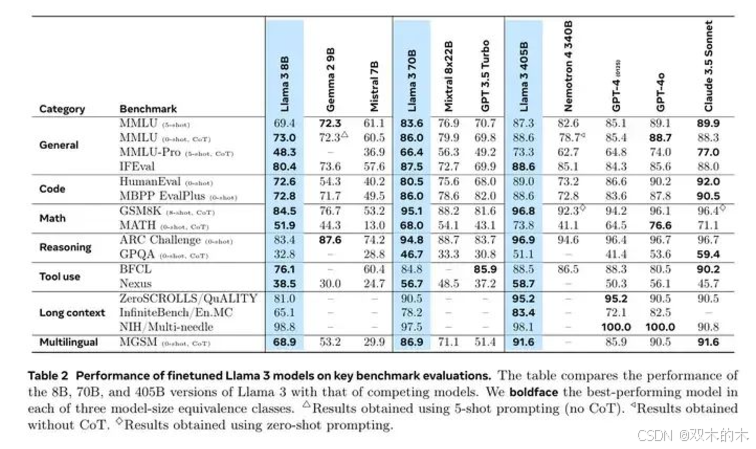
Performance of finetuned Llama 3 models on key benchmark evaluations.
(a)MMLU系列 :类似于各种考试里面的选择题,只是主要考察模型的知识面(背答案)。
Question: Glucose is transported into the muscle cell:
Choices:
A. via protein transporters called GLUT4.
B. only in the presence of insulin.
C. via hexokinase.
D. via monocarbylic acid transporters.
Correct answer: A
原版MMLU是比较老的benchmark,存在大家overfit的可能性。MMLU-Pro相对更新一些,可以看到在MMLU-Pro上,8B,70B,405B的差距相当大,说明参数规模和内化到权重中的知识量还是非常相关的。
(b)IFEval :IF即Instruction Following,考察模型对指令的理解和遵循能力。原文见:IFEval Dataset | Papers With Code[1]。
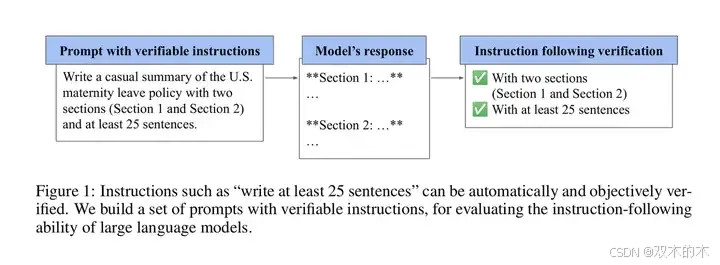
IFEval 示例
在IFEVAL上,8B和70B的差距还是很明显的(80.4/87.5),而70B和405B的差距已经不明显了(87.5/88.6)。说明参数规模到达一定程度后,再想通过扩大规模来提IF能力,可能会逐渐不显著。
(c)剩下的benchmark则偏垂直一些,分别包含了Code,Math,Reasoning,Tool use,Long context,Multilingual,可参见报告原文。
补充:上述评估集既然都有overfit和leaking的风险,那还有没有其他的benchmark呢?当然,比如LiveBench这种monthly更新的benchmark,LiveBench[2]。不过,天底下是没有完美的benchmark的,尤其是对于具体业务而言。
总体上看,8B和70B在各方面差距都还是比较明显,但70B和405B在以上的评估集中,则差异相对小一些。405B的推理和训练都比较慢,一般情况下,70B算是复杂应用的首选。如果特别复杂,再考虑405B,毕竟性价比还是会差一些。值得一提的是,Llama 3.1 70B在IFEval上接近Claude3.5 sonnet的水准。
2、Pre-Training
Meta:Language model pre-training involves: (1) the curation and filtering of a large-scale training corpus, (2) the development of a model architecture and corresponding scaling laws for determining model size, (3) the development of techniques for efficient pre-training at large scale, and (4) the development of a pre-training recipe. We present each of these components separately below.
上文比较笼统地说明了Pre-Training的要点。
2.1 Pre-Training Data
-
Web Data Curation
预训练数据处理的要点包括de-duplication methods and data cleaning mechanisms,即去重和清洗,如果做得不好,质量会
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1314
1314

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









