






这两天在看YOLO的论文,把看完的思路整理一下,同时结合网上的信息,如有侵权,请联系我。谢谢!如果有错误的地方还请大家指正。
YOLO的主要思想是找box+计算confidence,,然后去连接层分类,其示意图如下图所示:

我们输入一副图片,首先呢,我们把它分为s*s的cell,然后为每个方格计算相应的置信值也就是confidence .
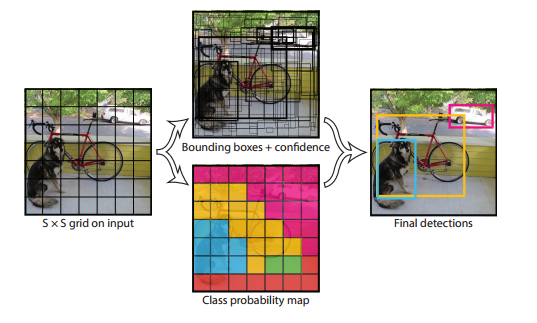
如果物体的中心落入这个Cell中,那么就要对这个cell进行计算,计算其confidence.如下图所示,我们红色区域是一个狗的中心,然后我们需要计算置信度。在这里我们要计算方框,以这个为中心,我们计算B 个bounding box信息,B在论文中为2。Bounding box信息包含5个数据值,分别是x,y,w,h,和confidence。其中x,y是指当前格子预测得到的物体的bounding box的中心位置的坐标。w,h是bounding box的宽度和高度。注意:实际训练过程中,w和h的值使用图像的宽度和高度进行归一化到[0,1]区间内;x,y是bounding box中心位置相对于当前格子位置的偏移值,并且被归一化到[0,1]。
这样我们的预测层就为S*S*(B* 5 + C)维

每个 1*1*30的维度对应原图7*7个cell中的一个,1*1*30中含有类别预测和bbox坐标预测。总得来讲就是让网格负责类别信息,



我们在做自己的训练的时候,只需要将C改为自己要识别的物体的类别就可以了,作者在进行训练的时候使用224 * 224 的图像,为了提高精度,作者对输入图像要缩放到448*448。最后一层分别对bouding box 的位置进行预测以及图像的类别,在对位置进行预测的时候我们要讲w以及h归一化到0-1之间。
在进行分类的P预测的时候我们使用非极大值抑制,具体原理如下图所示:

误差函数分为位置误差、IOU误差以及分类误差。
IOU(intersection over union)为预测boundingbox与物体真实区域的交集面积(以像素为单位,用真实区域的像素面积归一化到[0,1]区间)。
















 6287
6287

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









