








导读:随着 DALLE、CLIP 等里程碑式工作的横空出世,「视觉-语言」多模态任务成为了目前人工智能领域最火热的话题之一。近日,Hugging Face 研究负责人、斯坦福大学兼职教 Douwe Kiela 针对当前「视觉-语言」预训练任务存在的评测任务瓶颈展开了讨论,介绍了其团队在 NeurIPS、CVPR 等顶级会议上提出的新型多模态评测任务「Hateful Memes」、「AdVQA」、「Minoground」,以及它们针对上述新任务提出的基础性「视觉-语言」对齐模型「FLAVA」。
讲者:Douwe Kiela
整理:熊宇轩
编辑:李梦佳
注:本文为「2022北京智源大会」报告,回放视频请看:
https://2022-live.baai.ac.cn/2022/live/?room_id=17479
在真实世界中理解语言背后的意图
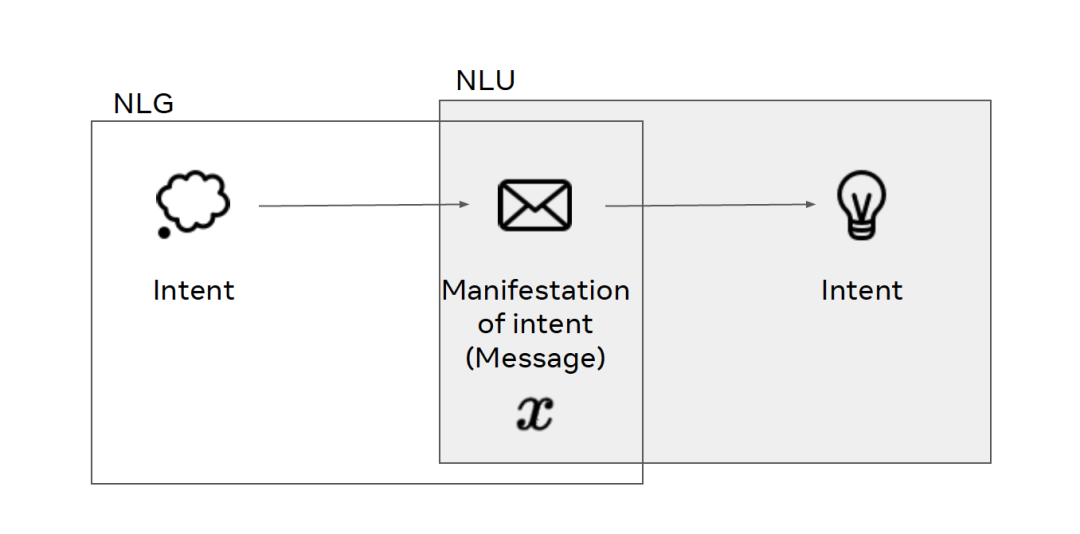
Kiela 在其研究生涯的大部分实践中专注于「让机器理解语言真正的意义」,这种语义是人类所理解的意义,而不仅仅是存在于计算机中的「虚假意义」。
从哲学的角度来说,对语言的定义还存在一定的争议。Kiela 认为,语言是思维的表现,它是一种消息,传递了一些真实的意图。人类精神世界的意图通过消息传递出来,沟通中的另一方也可以以此推断出正确的意图。
用自然语言处理(NLP)的术语来说,我们可以将上图中根据真实意图产生消息的过程看做自然语言生成(NLG),将根据消息推断意图的过程看做自然语言理解(NLU),而语言则是将从真实意图到推断意图的映射。

在机器学习领域中,我们根据给定的数据找到合适的映射模型的参数。具体到语言学习过程中,给定意图的表现(消息 x),我们要最大化预测意图正确的概率。对于大多数机器学习任务,我们往往假设训练数据和测试数据满足独立同分布,可以通过极大似然估计(MLE)来捕获底层流形。

如今,我们往往通过预训练的语言模型初始化模型参数,而非随机初始化。在预训练过程中,我们通过在巨大的语料库上进行一些基础的语言建模任务(例如,掩码语言模型)得到模型的初始化参数,进而完成极大似然估计任务。
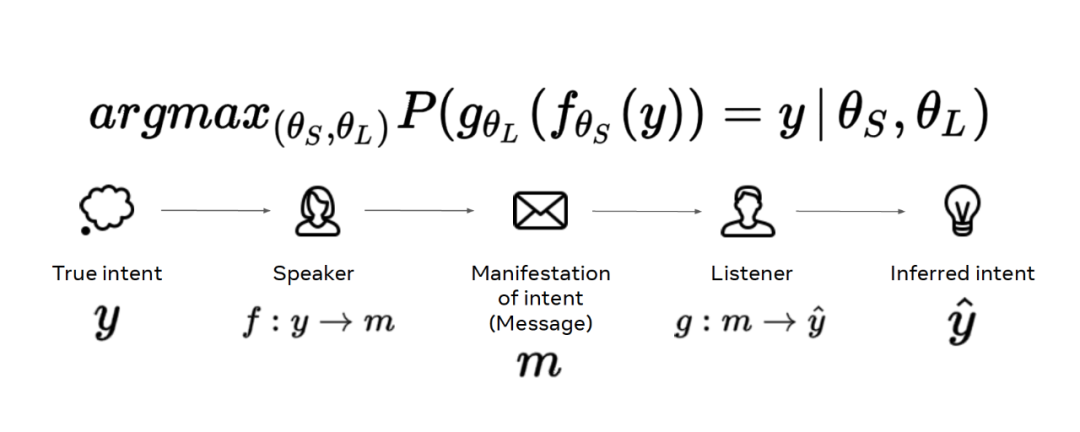
这种做法实际上将实际的语言问题极大简化了。人类真实的语言行为并不是直接将真实意图 y 通过信息 x 映射为预测 。对于人类来说,语言问题还涉及两个独立的函数:说话者 f 和倾听者 g。f 将真实意图映射为消息,g 将消息映射为预测的意图。我们要单独地对说话者和倾听者函数进行参数化,再将这些函数组合起来。
。对于人类来说,语言问题还涉及两个独立的函数:说话者 f 和倾听者 g。f 将真实意图映射为消息,g 将消息映射为预测的意图。我们要单独地对说话者和倾听者函数进行参数化,再将这些函数组合起来。
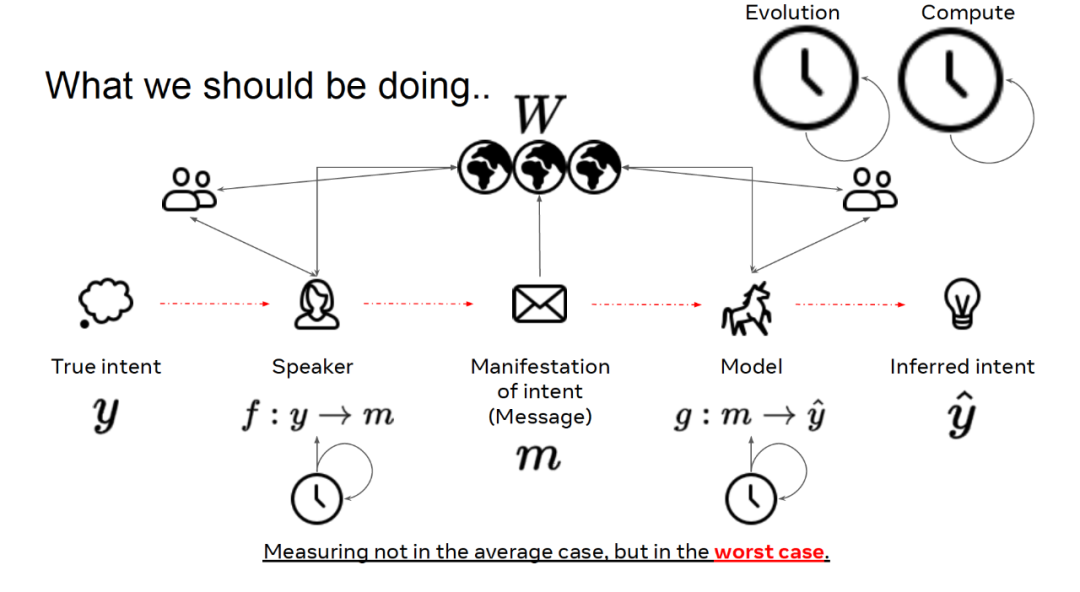
在现实世界中,情况往往更加复杂,对话的参与者不仅仅限于说话者和倾听者两方,可能周围还有其它参与对话的人。这种对话环境充满各种可能性,谈论的话题甚至可能是并不存在的事务(例如,独角兽)。我们确保所说的话与其它相同语言社会中的说话者和倾听者者兼容一致。这涉及到对宏观演进过程的先验、对文化的先验,以及我们个人的经验。因此,我们也要考虑时序信息,这与我们随时间学习、掌握语言、将语言用于沟通是有关的。
如前文所述,我们在现有的机器学习任务中,将真实意图转化为体现意图的消息文本,将其输入给通过分布式统计量初始化的模型,进而使用该模型推断标签。然而,这种做法忽略了语言中的大量其它因素,将问题过于简化了。
多模态任务的评估
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 7
7











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









