






MATLAB代码:配网+微网双层 多智体强化学习
关键词:强化学习 双层 配电网 微电网
参考文档:《Optimal energy management of multi-microgrids connected to distribution system based on deep reinforcement learning》2021 SCI一区复现 程度及难度超过原文
仿真平台:MATLAB
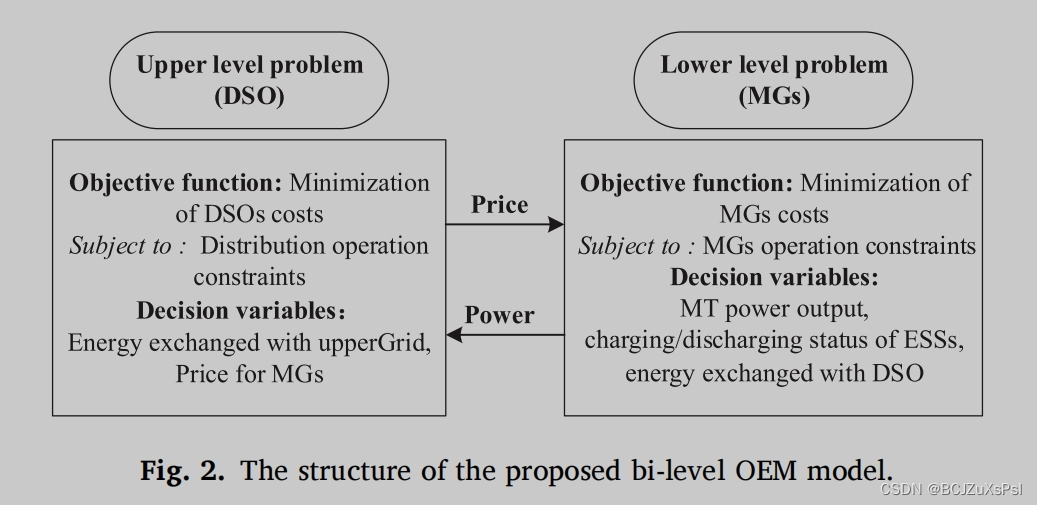
主要内容:本文首先提出了一种基于多微网-配电系统的双层协调最优能源管理(OEM)框架。
在这个框架中,分配系统操作员(DSO)在上层做出决策,而经理们在下层做出自己的决策。
其次,提出了一种基于领导-多追随博弈的交互机制,以DSO为领导者,总经理为追随者的动态博弈来提高双方的效用。
此外,还研究了一种数据驱动的多智能体深度强化学习(DRL)方法来计算OEM问题的斯塔克尔堡平衡。
最后,通过对改进的多mgsIEEE-33测试系统的案例研究,验证了该方法的性能。
通过调度结果验证了计算效率和准确性。

本文主要介绍一种基于多微网-配电系统的双层协调最优能源管理(OEM)框架,并在该框架中探讨了一种交互机制和一种数据驱动的多智能体深度强化学习(DRL)方法。同时,本文通过改进的多mgsIEEE-33测试系统的案例研究,验证了该方法的性能,结果表明其计算效率和准确性都得到了提高。
I. 引言
目前,电力系统已经成为了现代工业和生产生活中不可或缺的基础设施。在能源危机和环境保护的双重压力下,分布式能源技术和微电网技术越来越受到重视,这也为电力系统的可靠性、安全性和经济性提出了更高的要求。为了实现这些目标,需要开发一种优化的能源管理策略。
II. OEM框架
本文提出的基于多微网-配电系统的双层协调最优能源管理(OEM)框架,是一种将微电网和配电网结合起来的能源管理方案。此框架可以分为两个层次,分别是分配系统操作员(DSO)层和经理层。DSO层的任务是对用电需求进行监测和预测,并提出合理的能源分配方案。经理层的任务是对DSO提出的方案进行优化调整,以实现系统的最优化管理。此框架可以对系统进行全面的优化,从而提供更高效、更可靠的电能管理。
III. 交互机制
为了提高DSO和经理之间的效用,本文提出了一种基于领导-多追随博弈的交互机制。这种机制以DSO为领导者,经理为追随者,通过动态博弈实现双方的优化。在这个交互机制中,DSO将提出分配方案,经理将提出调整意见。DSO和经理之间通过博弈来协调不同的利益,以达到最优化的管理效果。
IV. DRL方法
为了进一步提高OEM问题的解决方案,在本文中还提出了一种数据驱动的多智能体深度强化学习(DRL)方法。这种方法可以计算OEM问题的斯塔克尔堡平衡,从而实现最优化的能源管理。在这个方法中,多个智能体通过深度强化学习进行协作,以达到最优化的管理效果。与传统的算法相比,DRL方法具有更高的计算效率和准确性。
V. 案例研究
为了验证提出的OEM框架和DRL方法的性能,本文进行了改进的多mgsIEEE-33测试系统的案例研究。通过对该系统的调度结果分析,验证了提出方法的计算效率和准确性得到了提升。同时,该框架也可以为其他类似的系统提供一种有效的能源管理方案。
VI. 结论
本文介绍的基于多微网-配电系统的双层协调最优能源管理(OEM)框架,以及交互机制和数据驱动的多智能体深度强化学习(DRL)方法,为电力系统的可靠性、安全性和经济性提供了一种有效的能源管理方案。同时,该框架也为其他类似的系统提供了一个有效的模型。
相关代码,程序地址:http://lanzouw.top/681990896596.html















 467
467











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









