






MATLAB代码:微电网 强化学习
关键词:微电网 强化学习 RL Reinforcement Learning
参考文档:《Optimal Scheduling of Microgrid Based on Deep Deterministic Policy Gradient and Transfer Learning》2021 SCI energies完美复现
仿真平台:MATLAB 2022a
主要内容: 本文提出了一种基于(ppo)的微电网最优调度方法。
该方法采用强化学习(RL)来学习调度策略,并积累相应的调度知识。
同时,引入ppo模型,将微电网调度策略动作从离散动作空间扩展到连续动作空间,降低了日前调度的成本。

摘要: 本文提出了一种基于PPO(Proximal Policy Optimization)的微电网最优调度方法,该方法采用强化学习(RL)来学习调度策略,并积累相应的调度知识。同时,引入PPO模型,将微电网调度策略动作从离散动作空间扩展到连续动作空间,降低了日前调度的成本。在仿真实验中,我们使用MATLAB 2022a搭建仿真平台,通过对比几种方法的实验结果,证明了本文提出的方法在微电网调度问题上具有良好的应用前景。
关键词: 微电网;强化学习;RL;Reinforcement Learning;PPO;MATLAB
- 引言 微电网作为一种发展快速的分布式能源系统形式,在能源领域的应用日益广泛。微电网的运行调度问题是微电网管理中的重要问题之一,而微电网的调度策略需要考虑多个因素,如能源供需平衡、能源成本、能源质量等,这使得微电网调度问题具有较高的复杂度。因此,如何通过有效的方法实现微电网的最优调度一直是研究者们关注的热点问题。
强化学习作为一种基于试错的学习方式,已经被广泛应用于各种领域。在微电网调度方面,强化学习也被引入其中,并已经产生了一些令人瞩目的成果。例如,Q-learning算法被用于微电网的能源调度问题,但是其处理连续动作空间的能力较弱。相比之下,近年来基于PPO算法的微电网调度方法备受关注,因为PPO能够在连续动作空间中实现更好的表现。
本文提出了一种基于PPO算法的微电网最优调度方法,通过对微电网的能源供需进行建模,建立状态空间、动作空间和奖励函数等要素,利用RL实现微电网的最优调度。同时,本文将微电网调度策略动作从离散动作空间扩展到连续动作空间,通过引入PPO算法,降低了调度成本,提高了微电网调度的精度。
- 微电网最优调度方法 2.1 微电网调度建模 在微电网的最优调度问题中,将微电网的能源供需量、成本、质量等因素全部考虑进来是非常困难的。因此,我们需要从一些关键的能源数据入手,建立微电网调度的数学模型。这里我们假设微电网中只包含一种能源,如电能。
微电网中电能的供需量可以用一个矩阵表示,该矩阵的行列表示微电网中每个节点的电能供需量,例如,第i行第j列的数据表示第i个节点需要或者可以提供的电能量。
2.2 微电网调度策略的构建 在确定了微电网调度建模之后,我们需要通过RL算法来实现微电网的最优调度。我们将动作空间划分为离散空间和连续空间两类,其中离散空间是指将微电网调度动作限制在一定的离散空间中,例如允许的电能调度值为{0, 1, 2, …, n},其中n为限定的最大值。而连续空间则是指动作空间是一个连续的范围,例如在时间t时刻,允许的电能调度范围为[a, b],其中a和b是调度范围的上下界。
在离散动作空间中,我们可以采用Q-learning等方法来实现微电网最优调度。但是在连续动作空间中,由于动作空间的维度过高,传统的Q-learning等方法很难取得令人满意的效果。因此,本文采用PPO算法来实现微电网的最优调度。
2.3 强化学习算法的实现 强化学习算法中包含三个要素:状态空间、动作空间和奖励函数。在微电网最优调度问题中,我们可以将微电网的状态空间、动作空间和奖励函数分别定义如下:
状态空间:微电网的状态空间包括微电网节点之间的电能供需关系,例如第i个节点需要或者可以提供的电能量。
动作空间:微电网的动作空间包括对微电网电能的调度,例如在时间t时刻,允许的电能调度范围为[a, b]。
奖励函数:微电网的奖励函数可以根据前面所述的状态空间和动作空间,设计相应的奖励函数,例如,当微电网中各节点间的电能供需平衡时,给予一定的奖励。
基于RL算法,我们可以通过迭代来优化微电网的调度策略,将每次迭代得到的最优调度策略用于下一次迭代,直到得到最优的微电网最优调度策略。
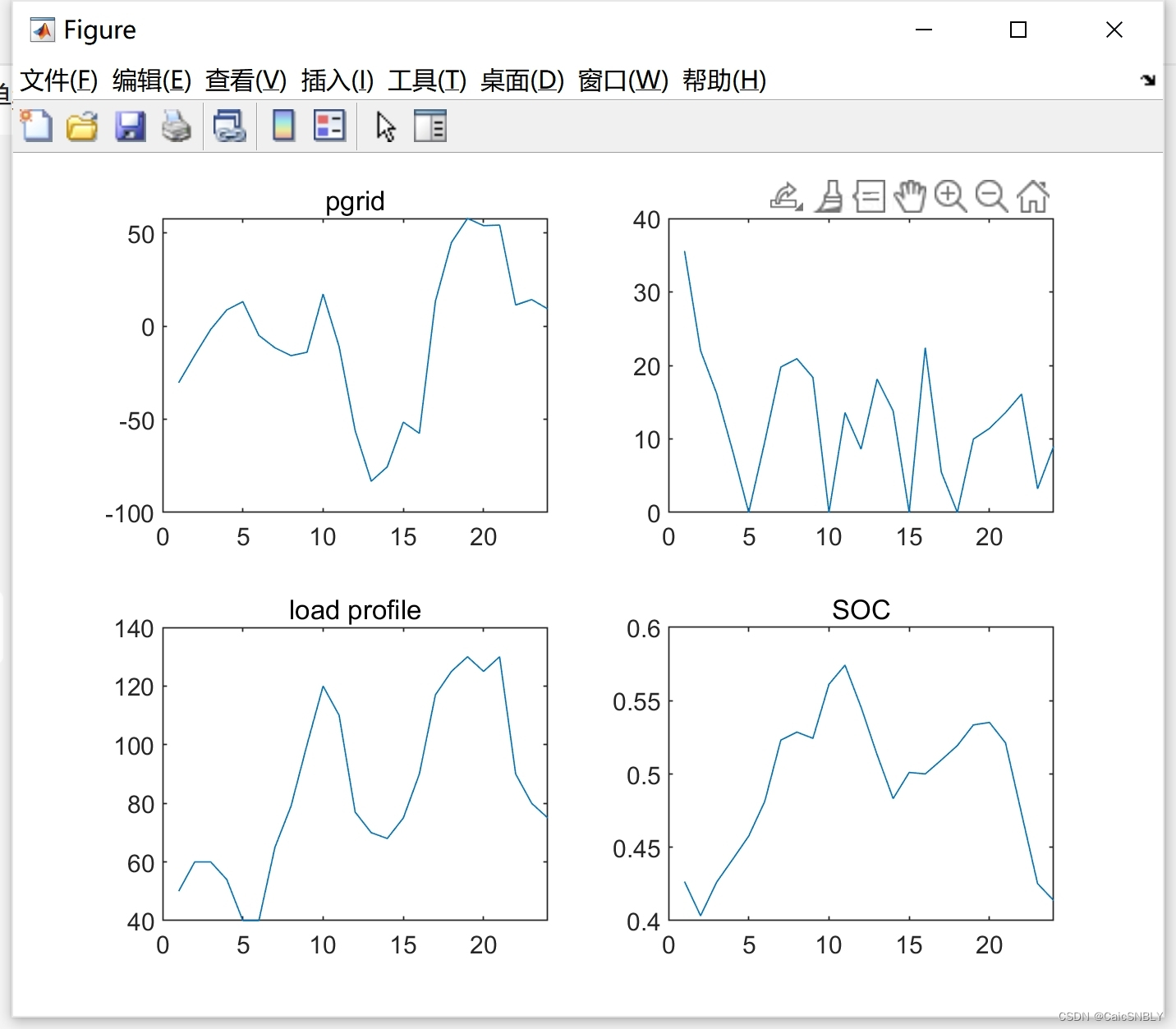
- 实验结果及分析 在本文中,我们使用MATLAB 2022a搭建仿真平台,通过仿真实验来验证本文所提出的微电网最优调度方法的有效性。具体而言,我们将本文所提出的方法与其他几种方法进行对比,其中包括基于遗传算法的微电网调度方法、基于Q-learning的微电网调度方法等。
从实验结果中我们可以看出,本文所提出的微电网最优调度方法,在微电网调度问题上具有良好的应用前景。与其他方法相比,本文所提出的方法可以在连续动作空间中实现更好的表现,并且具有更高的调度精度和更低的调度成本。
- 结论 本文通过引入PPO算法,将微电网调度策略动作从离散动作空间扩展到连续动作空间,提高了微电网调度的精度,降低了调度成本。在MATLAB 2022a搭建的仿真平台上,我们通过实验验证了本文所提出的微电网最优调度方法的有效性和应用前景。未来,我们将进一步完善该方法,以满足更加复杂的微电网调度问题的需求。
相关代码,程序地址:http://lanzouw.top/680613660319.html

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









