







目录
Bert在NLP领域刷新了很多记录,以及后来一些work基本是在Bert基础上做的相关改进,接下来总结下自己最近在阅读相关论文的一些理解和笔记整理。
1 Transformer结构
论文:attention is all you need
DL,我们知道,最基本结构大家所熟悉的DNN, CNN, RNN等结构。在CV领域,CNN结构更受青睐,而在NLP领域,则属RNN结构,由于RNN结构的序列表征学习能力,正好是自然语言处理所需要的。例如,在电商里,搜索“牛奶巧克力”和“巧克力牛奶”所代表的物体就完全不一样,一个指的是物体“巧克力”,一个指的是物体“牛奶”,而基本的DNN结构不能建模序列问题。但RNN结构,依赖于它序列建模能力,所以基于序列任务,RNN更胜一筹。但由于RNN模型的结构,下一步的预测依赖上一步的输出,所以不能很好的并行训练,导致速度相对较慢。接下来得说下transformer结构,一种基于attention的结构,可以并行计算,所以解决了RNN不能并行计算的问题,同时由于attention机制,同样可以较好的表征序列问题。
关于transformer结构,先对attention部分进行解说:
1.1 self attention的理解
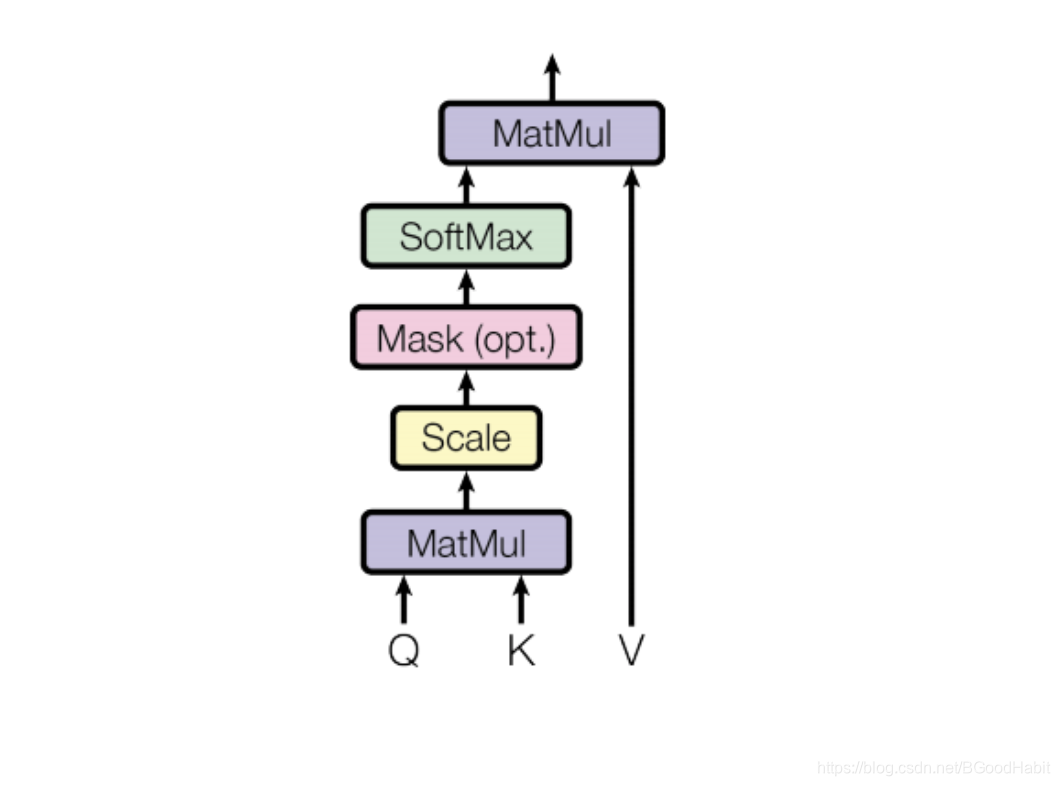
Q:L*embed_size 假如输入长度为L个词,每个词的向量大小为 embed_size
K: 同上述 Q
Q,K经过一层隐层变化后,得到相同维度的输出,再每个词同其他词的向量点乘之后,就是所谓的self权重,得到一个L大小 的权重矩阵
W
=
Q
∗
K
T
W=Q*K^T
W=Q∗KT
W矩阵里的每个元素的
x
i
j
x_{ij}
xij含义,代表第i个term与第j个term之间的权重值
V: 与Q定义一致,经过隐层变化后,再与权重W矩阵相乘,得到:
E
=
V
∗
W
E=V*W
E=V∗W
E矩阵的size和Q,K,V一致,其中的每一行i 代表了一个句向量,由当前第i个term与其他term相乘对应得到的权重再去乘以各自的term向量,再把对应的带权重相乘后的term向量相加得到整个句子向量。
原论文:Attention is all you need给出的具体公式如下:
A
t
t
e
n
t
i
o
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
k
)
V
Attention(Q,K,V) = softmax(\frac{QK^T}{\sqrt{d_k}})V
Attention(Q,K,V)=softmax(dkQKT)V
其中
d
k
d_k
dk表示Q和K各querys和keys的维度大小。计算attention和上面分解一步一步算的方法一致,但为什么要除以
d
k
\sqrt{d_k}
dk?,因为如果维度
d
k
d_k
dk很大的时候,这种点积相乘得到的数值可能会非常大,由于softmax是
e
x
e^x
ex的指数计算,有可能会导致数值越界,超出最大值表示,用python验证,计算
e
1000
e^{1000}
e1000就是inf结果了,所以为了数值的稳定性,除以
d
k
\sqrt{d_k}
dk
1.2 Multi head理解

论文中作者的理解是:Multi-head attention允许模型去学习在不同位置和空间上的不同表征特征。我们可以这么理解,有点“一词多意”的味道,希望模型在不同的空间维度可以学习不同的含义。Multi-head的表达形式如下:
M
u
l
t
i
H
e
a
d
(
Q
,
K
,
V
)
=
C
o
n
c
a
t
(
h
e
a
d
1
,
.
.
.
,
h
e
a
d
h
)
W
O
MultiHead(Q,K,V)=Concat(head_1,...,head_h)W^O
MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中
h
e
a
d
i
=
A
t
t
e
n
t
i
o
n
(
Q
W
i
Q
,
K
W
i
K
,
V
W
i
V
)
head_i = Attention(QW_i^Q, KW_i^K, VW_i^V)
headi=Attention(QWiQ,KWiK,VWiV)
映射变化层参数:
W
i
Q
∈
R
d
m
o
d
e
l
∗
d
q
,
W
i
K
∈
R
d
m
o
d
e
l
∗
d
k
,
W
i
V
∈
R
d
m
o
d
e
l
∗
d
v
,
W
O
∈
R
h
d
v
∗
d
m
o
d
e
l
W_i^Q \in R^{d_{model}*d_q}, W_i^K \in R^{d_{model}*d_k}, W_i^V \in R^{d_{model}*d_v}, W^O \in R^{hd_v*d_{model}}
WiQ∈Rdmodel∗dq,WiK∈Rdmodel∗dk,WiV∈Rdmodel∗dv,WO∈Rhdv∗dmodel
论文中作者设置Head
h
=
8
h=8
h=8个平行计算的attention head,为了降低每个Head的维度,所以
d
q
=
d
k
=
d
v
=
d
m
o
d
e
l
/
h
=
64
d_q=d_k=d_v=d_{model}/h=64
dq=dk=dv=dmodel/h=64,最后concat后,又和单个head的维度保持一致了。
注意:
(代码在计算的时候,将8个Head的映射层参数拼接为一个大的Q矩阵参数
W
d
m
o
d
e
l
∗
d
m
o
d
e
l
Q
W_{d_{model}*d_{model}}^Q
Wdmodel∗dmodelQ,K矩阵参数
W
d
m
o
d
e
l
∗
d
m
o
d
e
l
K
W_{d_{model}*d_{model}}^K
Wdmodel∗dmodelK和V矩阵参数
W
d
m
o
d
e
l
∗
d
m
o
d
e
l
V
W_{d_{model}*d_{model}}^V
Wdmodel∗dmodelV矩阵参数,对
Q
,
K
,
V
Q,K,V
Q,K,V进行转换后,再split还原各个head的输出值,每个head计算各自的attention值得到最终的向量表征,最后再concat到一起输出。各个head映射变换参数组合成一个大的矩阵计算,还是单独算都是一样的运算方式和结果,放到一起代码处理上更好矩阵相乘,并行计算)
1.3 transformer基本单元构成
上面讲解的是transformer的attenion中的一部分,假如输出为attention_output,还需再接一层subLayer全连接映射层, 最后将原始输入部分再加上映射层输出部分相加(所谓的跳跃连接)再做layer norm,形式如: attention_final = LayerNorm(input + Sublayer(attention_output)),这才是完整的attention部分,接下来一层中间全连接层,intermediate层, 定义输出inter_output,则完整的一个transformer结构输出为: transformer_output=LayerNorm(attentin_final + Sublayer(inter_output))
2 Bert
论文:bert:pre-training of deep bidirectional transformers for language understanding
bert是由12层的transformer结构构成,是一个较大的网络结构,接下来对bert的几个细节点进行分析理解。
2.1 bert的输入三部分向量

由上图可知,输入 input representation由三部分向量相加组成:第一部分,token embeddings,这个是我们常见的向量输入,每个token有对应的向量表示,vocab词汇决定了向量数量,bert中的vocab token有2w多个;另外一部分,segment embeddings,由于bert做的pre-train中的一个task是预测两句是否是连续的两个句子,不同的句子segment embedding区分是不一样的,总大小为2,索引0代表的向量是第一句,索引1代表的向量是第二句,最后就是position embeddings,这个是位置向量,假如相同的一句话中有两个token是一样的,虽然token embeddings和segment embeddings都相同,但是position embeddings是不一样的,所以这两个相同的token,在一个句子的不同位置,则最后表示这两个token的最终向量是不一样的,加入position embedding可以让不同的顺序的相同token有了区分性。
2.2 bert的两个task pre-train
bert的两个task做pre-train过程:
第一:Masked LM方式,就是对输入的sequence,15%的token会随机进行替换操作,而替换操作分三种:如果第i个token被选中,有80%情况用 [MASK] 代替,10%随机从词典中选中一个token替换,10%保持不变(主要是下游任务fine tune的时候,无[MASK]这个token),例如,输入原始token list是:
[’[CLS]’,‘我’,‘喜’,‘爱’,‘苹’,‘果’,’[SEP’],‘因’,‘为’,‘很’,‘好’,‘吃’,’[SEP]’]
经过随机替换操作后,token list 是:
[’[CLS]’,‘我’,‘喜’,’[MASK]’,‘苹’,‘果’,’[SEP’],‘因’,‘为’,‘很’,‘好’,‘来’,’[SEP]’]
上面的 ‘爱’替换成了 [MASK],‘为’ 保持原样,'吃’ 随机替换成了’来’
用三个做了处理的位置的token向量作为输入,每个原始token在vocab的位置转成one-hot形式作为label,换句话就是bert最后输出那层,取被替换操作掉的token i位置上的输出,来预测该索引位置原始token在vocab中的label,是一个vocab大小的multi class分类问题。
第二:Next sentence prediction (NSP)方式,50%概率选择连续的两部分text_a和text_b,50%概率选择不连续的两部分,连续的就是正样本,不连续的就是负样本,做二分类任务,用bert的最终输出,[CLS] token的位置,也就是第1个位置代表的向量输入到softmax分类层。在pre-train中,这两个task是同时一起训练的,可以看成是两套分类,一个分类是两个label大小的multi class,一个分类是vocab大小的multi class,最后把两者的loss相加,作为最终的loss,计算梯度,更新模型参数,论文中的一个图展示的很清楚,如下所示:

2.3 理解bert最后输出取第一个token [CLS] 位置作为分类层的输入
第一次看bert的时候,疑惑为什么最终的分类,用的是bert最后输出的第一个token位置对应的向量,深入分析才发现,第一个位置是[CLS]与输入的句子的每个token做self attention,然后得到对应的权重再与各自的token represation向量相乘,最后相加得到的是代表整个输入句子的represation,所以搞明白了第一个位置的向量其实是代表了整个句子的represation,当然模型输出层的每个位置都代表了整个句子向量,差别在于是用当前位置的token与其他的token相乘得到的self attention,那么为什么不用其他的,用第一个位置[CLS]这个?或者可不可以用[SEP]所在的位置的句子represation?整体分析下来,[CLS]对于每个输入来说,都代表了全局的一个contex vector,因为在每个输入中**[CLS]的token embeddings, segment embeddings,position embeddings都是一样的,但是[SEP]在不同的输入中,可能position embeddings是不一样**的,所以不能代替全局。
2.4 基于bert的分类与标注做multi task任务
之前做过用bert来做句子分类和标注的multi task任务,multi task的一个整体思路在我看来,就是底层的model共享,然后在最上层可以接多个task,从本质来看,多数任务,比如标注,分类,翻译等可以理解成是一个分类任务,分类可以是multi class的单标签分类,也可以是multi label的多标签分类,标注可以看成是更细粒度的分类,需要对每个token进行分类。模型学习需要计算loss,再获取梯度,更新模型参数。而multi task的最后loss可以简单的由这几个task的loss相加得来,或者带权重的loss相加,这些根据自己实际任务进行设置。multi task需要对数据做多个标签,如果有些数据的标签不是很好获取,数据合并到一起,需要保证打上多个标签,整体灵活性就降低了。但multi task可以让一个模型做多个任务,共同训练,整体会对单个任务有帮助,同时对存储和速度要求的任务可以提高效率。
3 RoBerta
论文:Roberta: A Robustly Optimized BERT Pretraining Approach
bert问世后,在NLP很多领域刷新了记录,后续也有不少的work基于bert做了改进和优化,这篇论文主要是对bert的pre-train进行了细节上的优化。
3.1 主要改动点
1.bert中对一个句子,进行随机的一次mask,是一个静态的static,该论文用dynamic mask方式,对训练语料进行10次重复采样,然后每个样本用10次不同的mask方式。
2. 试验发现去掉NSP pre-train task对下游任务有稍微的提升能力,所以去掉了NSP task
3. 训练语料更多,训练batch更大
4 AlBert
论文:Albert: A Lite Bert fro Self-Supervised Learning Of Language Representations
bert模型太大,对速度,内存要求较高的在线任务,会带来很大挑战,所以不少work也是针对模型的大小和速度进行优化,albert通过一些tricks对bert进行参数压缩,使得模型变小。
4.1 主要改动点
1.token向量矩阵分解
我们知道,模型很大块参数都是因为token embeddings,如果vocab很大,模型参数将增加很多,假设 V代表的token总数量,H代表的是embeddings维度,则整个需要学习的token embeddings参数有O(V × H),而这个矩阵可以用两个小的矩阵进行分解 V × H = (V × E) × (E × H),则参数从O(V × H) to O(V × E + E × H),由于H >> E,所以整个参数量就降低了很多
2.共享transformer层参数
我们知道bert是由12层的transformer构成的,每层的transformer都有自己的参数,整个参数量是比较庞大的,albert将所有层的transformer都共用第一层的transformer参数,所以整体将12层的transformer参数降低了12倍,只有一层的transformer参数
3.NSP改成SOP
将NSP预测下一句是不是相邻的任务,改成 sentence-order prediction (SOP),也就是在文章相邻的两个句子为正样本,把两个句子顺序颠倒做为负样本
最后论文中的模型大小对比图附上:

5 DistilBert
论文:DistilBert a distilled version of bert: smaller, faster, cheaper and lighter
这是一篇知识蒸馏bert模型,知识蒸馏按照我形象的理解就是,用小bert模型结构(student)去学些大的bert模型(teacher)预测能力。利用一些学习策略,获得一个更小,更快,但是预测效果和大的模型还几乎相当的一个小模型。
5.1 改动点
1.distilBert模型和Bert模型有相同的结构,但层数降低了一半,只有6层transformer结构
2.训练的时候让蒸馏distilBert模型尽量去学习bert模型的效果,主要在于Loss的设计由三部分组成,其中两部分都是与bert模型的输出有关,
第一:用 KL散度来度量bert与distilBert最后输出层概率分布(保证两模型预测的各个label概率分布尽可能的一致),用Lce 表示
第二: bert与distilBert最后输出向量的两者的cos loss(保证从模型中的输出向量表示尽可能的相似),用 Lcos表示
最后一部分就是,标准的交叉熵了,与真实label的交叉熵,用Lmlm表示
最终的loss由三部分带权重的loss相加得来:
Loss = 5Lce + 3Lmlm + 2*Lcos















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









