







目录
1 训练数据
中文分词,基于模型识别方法,主要是通过识别每个字的label,然后进行切词,其中字的label一般有如下4种标识:
| B | M | E | S |
|---|---|---|---|
| 词的开头 | 词的中间 | 词的结尾 | 单字的词 |
有了这些label,就可以进行切词了,从B开始直到E的片段就是一个词的切分。分词任务是一个有监督的学习任务,需要提供有标签的训练数据,所以训练数据需要对每个字打上一个label,例如 “宽松连衣裙红”对应的分词为“宽松,连衣裙,红",则对应的label如下:
| 宽 | 松 | 连 | 衣 | 裙 | 红 |
|---|---|---|---|---|---|
| B | E | B | M | E | S |
有了这样的带标签的数据,我们就可以训练模型了。
2 模型结构
2.1 BiLSTM
BiLSTM是RNN序列模型中较常见的一种结构,由于能够学习序列关系,在序列任务中比如标注等经常使用。接下来我们来看下BiLSTM模型如何训练一个分词模型。
2.1.1 结构
基于BiLSTM模型做分词任务,本质上就是对每个字进行分类,label为"B",“M”,“E”,“S”共4种label。如下图所示:
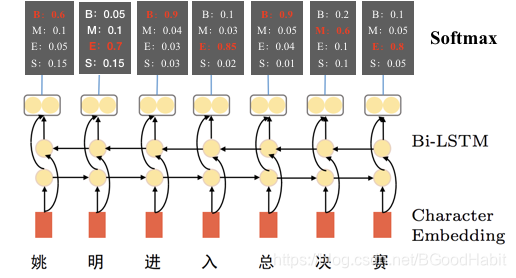
输入每个字的embedding,经过一个双向的LSTM,然后将前向和后向提取的字特征向量concat到一起作为最终的字向量特征,最后输入到包含4个类别的分类层,softmax后得到每个label的分值,其中分值最大的就是该字的label,用交叉熵作为loss,梯度下降方法更新整个模型参数。
2.1.2 预测
在预测阶段,模型对输入的每个字在4个label上预测一个概率分值,其中最大的一个概率分值对应的label就是当前字的label’,比如“姚明进入总决赛”预测每个字对应的label为“BEBEBME”,一个词是从"B"开头,"E"结尾,也就是B的位置是一个词的开始索引,E的位置时一个词的结束索引,根据这样的规则,我们得到分词结果:“姚明,进入,总决赛”。
2.1.3 缺点
BiLSTM模型做分词有什么问题呢?没有利用label与label之间的关系信息,在分词任务中,一个序列的label之间是有约束关系的,比如给出这样一组预测结果“BEBBME”,我们马上知道连续的两个B是不合理的,因为B后面只能够接M或者E。而BiLSTM模型在预测每个字的label时候并没有考虑label与label之间的约束关系(预测当前字的label只用到了上一个字和下一个字的文本特征,并没有用到字的label信息,若把上一个字的label也作为预测当前字的一个特征输入,有可能有缓解),这样会导致最终预测的序列label结果有可能是不合法的。
2.2 CRF
2.2.1 基础概念
基于BiLSTM做分词任务,任务模式如下:
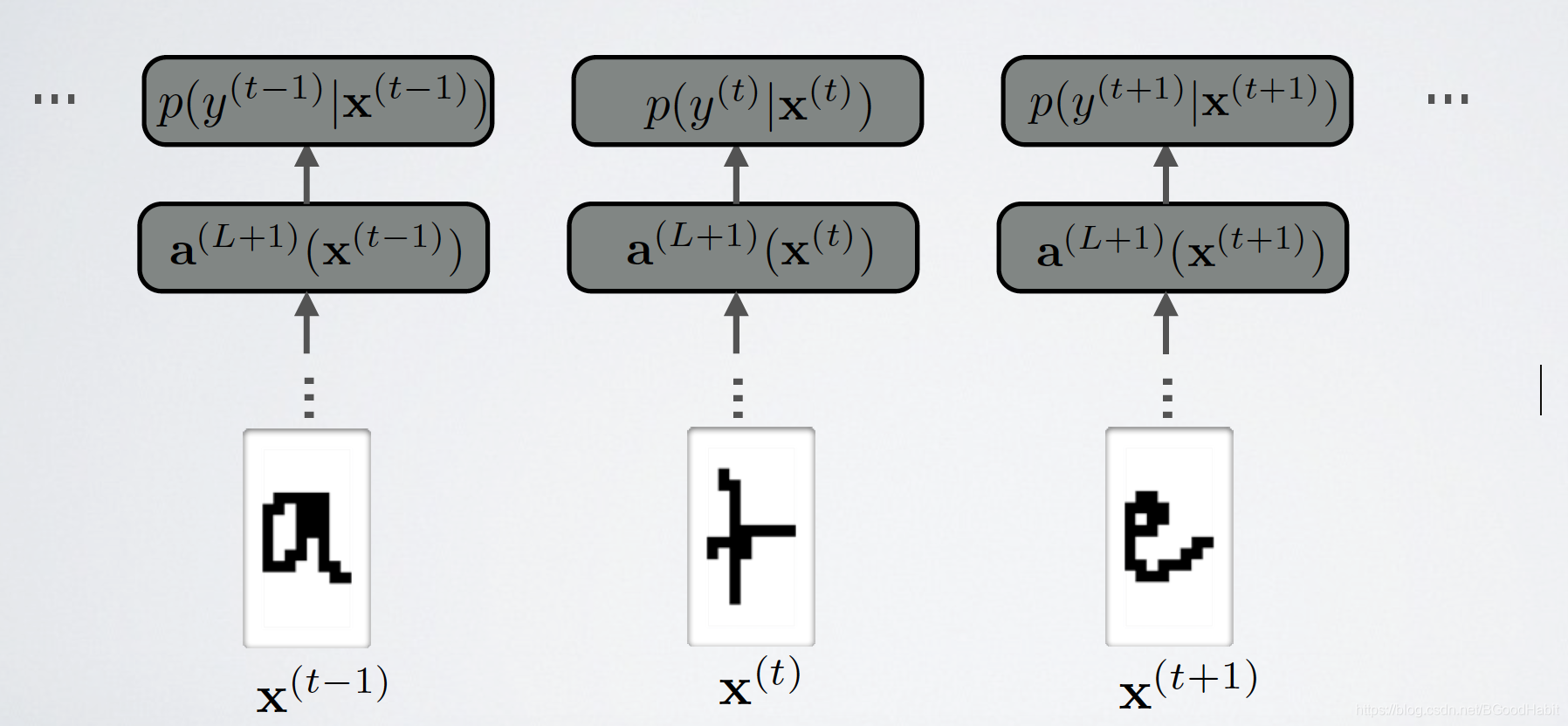
对每个输入预测各自的label,
p
(
y
i
∣
x
i
)
p(y_i|x_i)
p(yi∣xi),但是我们需要预测的是给定一个序列输入预测一个序列输出,
p
(
y
1
,
y
2
,
.
.
.
,
y
t
∣
x
1
,
x
2
,
.
.
.
x
t
)
p(y_1,y_2,...,y_t|x_1,x_2,...x_t)
p(y1,y2,...,yt∣x1,x2,...xt),模式如下图所示:
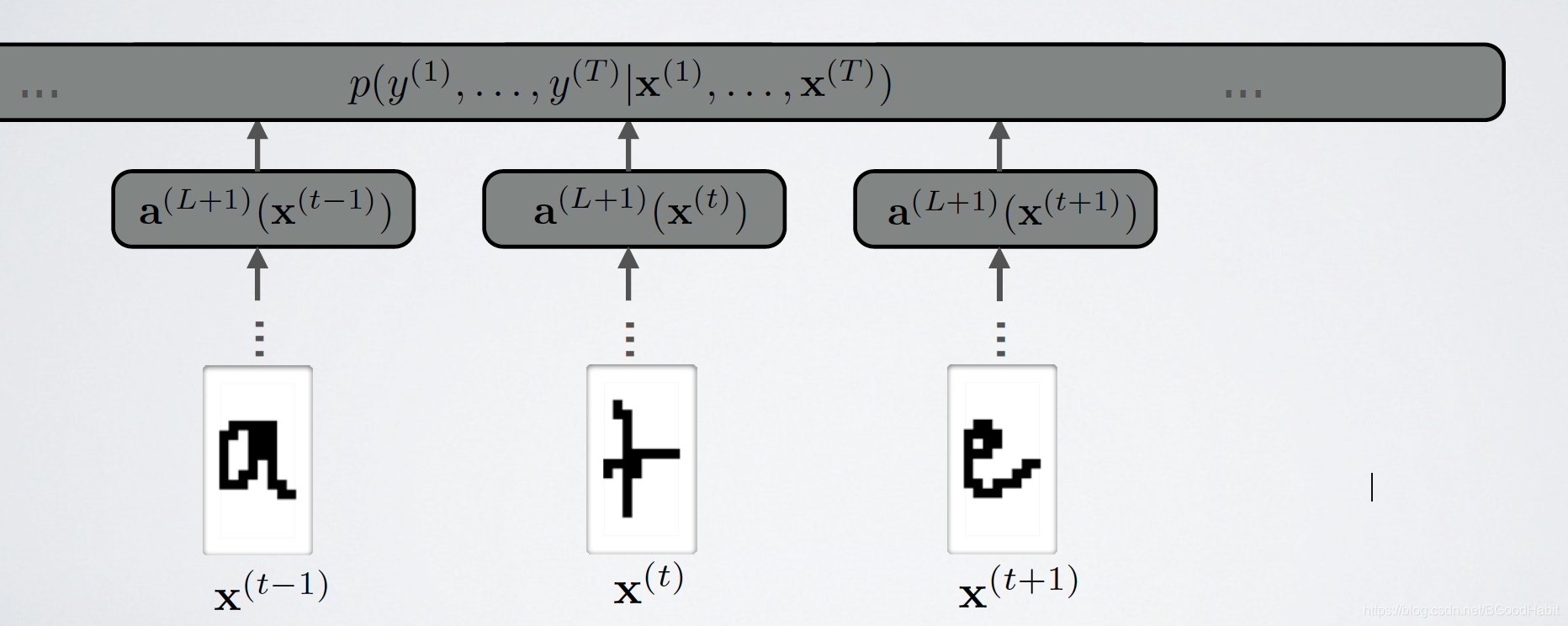
给定输入
X
=
x
1
,
x
2
,
.
.
.
,
x
t
X={x_1,x_2,...,x_t}
X=x1,x2,...,xt,我们需要预测
p
(
Y
∣
X
)
p(Y|X)
p(Y∣X),普通分类器概率分值计算结果如下:
p
(
Y
∣
X
)
=
∏
k
p
(
y
k
∣
x
k
)
=
∏
k
e
x
p
(
U
(
x
k
,
y
k
)
)
/
Z
(
x
k
)
p(Y|X) = \prod_k p(y_k|x_k) = \prod_k exp(U(x_k, y_k))/Z(x_k)
p(Y∣X)=k∏p(yk∣xk)=k∏exp(U(xk,yk))/Z(xk)
=
e
x
p
(
∑
k
U
(
x
k
,
y
k
)
)
/
(
∏
k
Z
(
x
k
)
)
= exp(\sum_kU(x_k,y_k))/(\prod_kZ(x_k))
=exp(k∑U(xk,yk))/(k∏Z(xk))
其中
U
(
x
,
y
)
U(x,y)
U(x,y)表示的unary分值,给定
x
x
x,对应的label
y
y
y的分值。其中
Z
(
x
)
Z(x)
Z(x)就是一个partition function,可以看做一个归一化因子,目的是得到一个概率分布,总和为1,
Z
(
x
)
Z(x)
Z(x)也可以看做是softmax函数的分母。
而通过建模label
y
k
y_k
yk与
y
k
+
1
y_{k+1}
yk+1之间的关系,我们就创建了连续label之间的依赖关系,这就是 linear-chain CRF。在
U
(
x
,
y
)
U(x,y)
U(x,y)上加上一项转移分值(transition score)
T
(
x
,
y
)
T(x,y)
T(x,y),表达公式如下:
p
(
Y
∣
X
)
=
e
x
p
(
∑
k
U
(
x
k
,
y
k
)
+
∑
k
T
(
y
k
−
1
,
y
k
,
x
k
)
)
/
Z
(
X
)
p(Y|X) = exp(\sum_kU(x_k,y_k)+\sum_{k}T(y_{k-1},y_{k},x_k))/Z(X)
p(Y∣X)=exp(k∑U(xk,yk)+k∑T(yk−1,yk,xk))/Z(X)
其中
T
(
.
)
T(.)
T(.)表示的是第
i
i
i个label到第
j
j
j个label的转移概率。所以在学习CRF之前,我们先来熟悉如下几个基本概念:
- 发射概率 (emissions or unary scores):对于输入 x k x_k xk,对应label 为 y k y_k yk的多大概率可能性。
- 转移概率 (transition scores):对于label y k − 1 y_{k-1} yk−1其后为label y k y_{k} yk多大概率可能性。
- 归一化因子 (partition function):归一化因子,为了得到最后的概率分布。
若label数量有
∣
y
∣
|y|
∣y∣,输入序列长度为
L
L
L,则输出的序列情况有
∣
y
∣
L
|y|^L
∣y∣L种可能,也就是计算归一化函数
Z
(
X
)
Z(X)
Z(X)复杂度为
O
(
∣
y
∣
L
)
O(|y|^L)
O(∣y∣L),若
L
L
L较大的情况下,将会十分耗时。所以,接下来我们就围绕以下几个问题一步步分析CRF训练和预测过程:
第一个问题:
U
(
x
i
,
y
i
)
U(x_i,y_i)
U(xi,yi),
T
(
y
i
,
y
i
+
1
)
T(y_i, y_{i+1})
T(yi,yi+1)特征函数如何计算
第二个问题:如何计算
Z
(
X
)
Z(X)
Z(X)
第三个问题:如何定义CRF模型损失函数
第四个问题:CRF如何进行预测
2.2.2 如何计算特征函数
我们先来了解下CRF中的特征函数,特征函数定义如下:
p
(
Y
∣
X
)
=
1
Z
(
x
)
e
x
p
(
∑
i
,
k
λ
k
t
k
(
y
i
,
y
i
+
1
,
x
,
i
)
+
∑
i
,
l
u
l
s
l
(
y
i
,
x
,
i
)
)
p(Y|X) = \frac{1}{Z(x)}exp(\sum_{i,k}\lambda_kt_k(y_i, y_{i+1}, x, i)+\sum_{i,l}u_ls_l(y_i,x,i))
p(Y∣X)=Z(x)1exp(i,k∑λktk(yi,yi+1,x,i)+i,l∑ulsl(yi,x,i))
其中,
t
k
(
.
)
,
s
l
(
.
)
t_k(.), s_l(.)
tk(.),sl(.)分别表示转移特征函数和状态特征函数,是二值函数,当条件满足时函数值为1否则为0:
t
k
(
y
i
−
1
,
y
i
,
x
,
i
)
=
{
1
,
条
件
0
,
其
它
t_k(y_{i-1}, y_i, x, i) = \begin{cases} 1,条件\\\\ 0 , 其它 \end{cases}
tk(yi−1,yi,x,i)=⎩⎪⎨⎪⎧1,条件0,其它
s l ( y i , x , i ) = { 1 , 条 件 0 , 其 它 s_l( y_i, x, i) = \begin{cases} 1,条件\\\\ 0 , 其它 \end{cases} sl(yi,x,i)=⎩⎪⎨⎪⎧1,条件0,其它
那这种特征函数又是怎么定义的呢?我们用crf++里定义特征模板进行一个简单说明。假设我们输入数据如下:
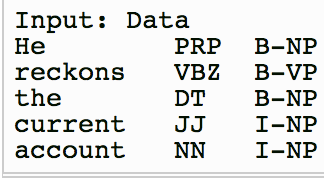
第一列是原始token,第二列是词性特征,第三例是label标签。在crf++中,模板设置如下:

其中Unigram定义的模板就是公式对应的状态特征函数,Bigram定义的就是转移特征函数,其中每一行代表一个模板特征,“U00:%x[0,0]”表示的是当前位置,假设是“the”,则“U12:%x[0,1]”表示的相对[0,0]的位移,对应的是“DT”。
给定了这些特征模板,那么征函数怎么生成呢?假设数据的所有token数量有
N
N
N个,label标签有
L
L
L个,在Unigram模板中,例如“U12:%x[0,1]”就会生成
N
×
L
N \times L
N×L个特征,对于每个token在每个label上是否满足条件,函数如下形式:
| 函数 | 权重参数 |
|---|---|
| func1 = if (output=B-NP and feature=“U12:PRP”) return 1 else return 0 | λ 1 \lambda_1 λ1 |
| func2 = if (output=B-VP and feature=“U12:PRP”) return 1 else return 0 | λ 2 \lambda_2 λ2 |
| func3 = if (output=I-NP and feature=“U12:PRP”) return 1 else return 0 | λ 3 \lambda_3 λ3 |
| … | … |
| funcxx = if (output=B-NP and feature=“U12:NN”) return 1 else return 0 | λ i \lambda_i λi |
| funcxx = if (output=B-VP and feature=“U12:NN”) return 1 else return 0 | λ i + 1 \lambda_{i+1} λi+1 |
| … | … |
每个模板都有对应生成的特征函数,每个函数都有对应的参数权重,每个参数
λ
i
\lambda_i
λi权重就是crf模型需要学习的权重。
在Bigram里,只有一个模板B,表示的是前一个输出label和当前输出label的组合关系,生成的特征函数有
L
×
L
×
N
L \times L \times N
L×L×N个,特征函数如下:
| 函数 | 权重参数 |
|---|---|
| func1 = if (pre_output=B-NP and output=B-NP and feature=“B:He”) return 1 else return 0 | u 1 u_1 u1 |
| func2 = if (pre_output=B-VP and output=B-NP and feature=“U12:He”) return 1 else return 0 | u 2 u_2 u2 |
| func3 = if (pre_output=I-NP and output=B-NP and feature=“U12:He”) return 1 else return 0 | u 3 u_3 u3 |
| … | … |
同样在状态转移函数里,每个函数有对应的参数权重
u
i
u_i
ui,这些参数权重是crf模型需要学习的。为简单起见,我们把转移特征函数和状态特征函数用一个公式表示,crf的公式如下:
p
(
y
∣
x
)
=
1
Z
(
x
)
e
x
p
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
p(y|x) = \frac{1}{Z(x)}exp\sum_{j=1}^n\sum_{i=1}^m\lambda_if_i(y_{j-1},y_j,x,j)
p(y∣x)=Z(x)1expj=1∑ni=1∑mλifi(yj−1,yj,x,j)
其中
Z
(
x
)
=
∑
y
e
x
p
(
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
)
Z(x) = \sum_y exp(\sum_{j=1}^n\sum_{i=1}^m\lambda_if_i(y_{j-1},y_j,x,j))
Z(x)=∑yexp(∑j=1n∑i=1mλifi(yj−1,yj,x,j))是归一化因子,是所有输出序列标签结果的分值相加。其中
∑
j
=
1
n
\sum_{j=1}^n
∑j=1n是对序列长度遍历,而
∑
i
=
1
m
\sum_{i=1}^m
∑i=1m是对特征总数量遍历,特征函数
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
f_i(y_{j-1},y_j,x,j)
fi(yj−1,yj,x,j)我们可以自己定义,其值为0或者1,每个特征函数对应一个参数权重
λ
i
\lambda_i
λi,这个参数权重就是crf模型基于训练语料需要学习的。
在语料中经常出现的模式对应的特征函数,会越多频率去更新参数,进而学习的参数权重也会越大。crf模型的整个表现主要依赖两点:第一,训练语料的质量和数量;第二:特征的设计,越能够提取对于任务有区别特征,模型的准确率就会越高。
2.2.3 如何求解归一化因子 Z ( x ) Z(x) Z(x)
从上面公式我们知道,归一化因子
Z
(
x
)
Z(x)
Z(x)是对所有可能的路径打分,并求指数和,假设label数量为
k
k
k,序列长度为
n
n
n,则有
k
n
k^n
kn条路径数,因此直接算是不可能的。如下图所示:
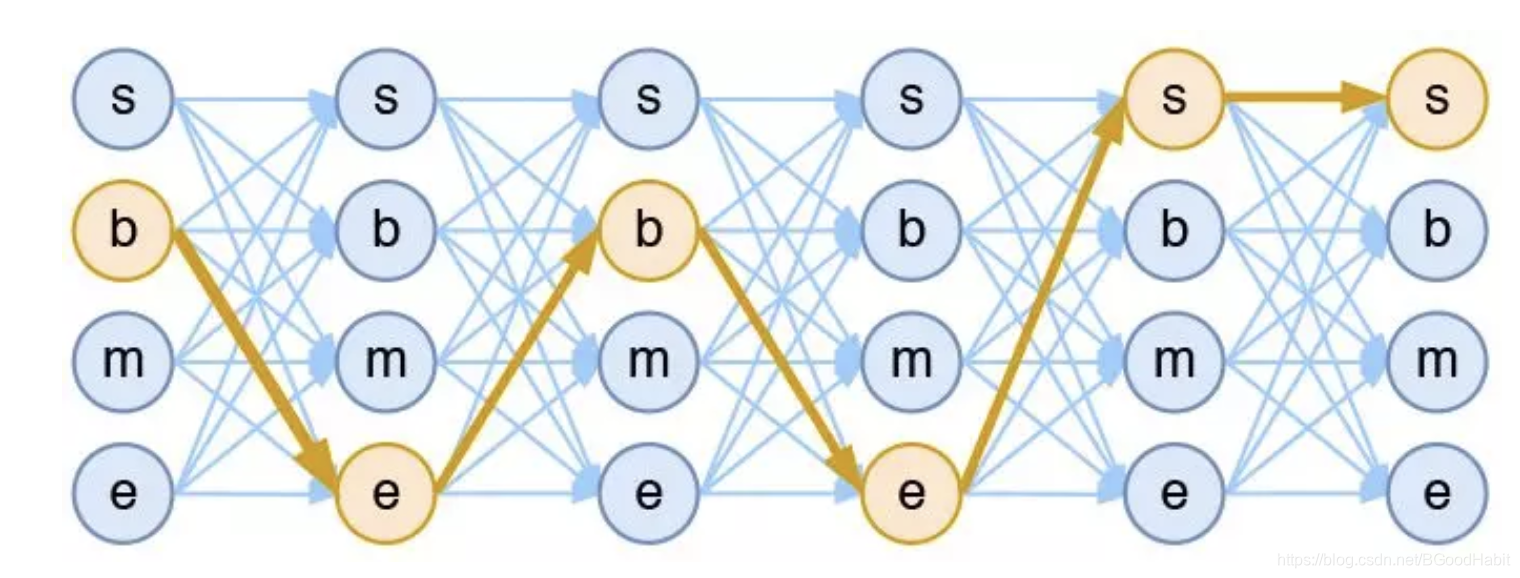
假设输入序列是“兔子喜欢吃菜”,对应的label序列为“b->e->b->e->s->s“:
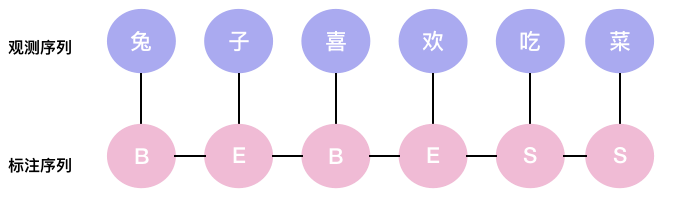
从crf定义的公式可知,目标序列的概率分值计算为:
p
(
y
∣
x
)
=
1
Z
(
x
)
e
s
(
兔
,
B
)
+
t
(
B
,
E
)
+
s
(
子
,
E
)
+
t
(
E
,
B
)
+
s
(
喜
,
B
)
+
t
(
B
,
E
)
+
s
(
欢
,
E
)
+
t
(
E
,
S
)
+
s
(
吃
,
s
)
+
t
(
S
,
S
)
+
s
(
菜
,
s
)
p(y|x) = \frac{1}{Z(x)}e^{s(兔,B)+t(B,E)+s(子,E)+t(E,B)+s(喜,B)+t(B,E)+s(欢,E)+t(E,S)+s(吃,s)+t(S,S)+s(菜,s)}
p(y∣x)=Z(x)1es(兔,B)+t(B,E)+s(子,E)+t(E,B)+s(喜,B)+t(B,E)+s(欢,E)+t(E,S)+s(吃,s)+t(S,S)+s(菜,s)
分子的指数项主要是发射概率分值加上转移概率分值,而在crf++中,根据定义的特征函数(函数值为0或者1),每个特征函数有对应的权重参数(模型需要学习的参数)进行加权相加。分子是很容易求得,而分母
Z
(
x
)
Z(x)
Z(x)归一化因子路径数量是指数级别的,所以不能直接计算。那该怎么计算?
通过递归计算归一化因子
首先,我们将计算到t时刻的归一化因子记为
Z
t
Z_t
Zt,并将他分为k个部分:
Z
t
=
Z
t
(
1
)
+
Z
t
(
2
)
+
.
.
.
+
Z
t
(
k
)
Z_t = Z_t^{(1)}+Z_t^{(2)}+...+Z_t^{(k)}
Zt=Zt(1)+Zt(2)+...+Zt(k)
其中
Z
t
(
1
)
,
.
.
.
,
Z
t
(
k
)
Z_t^{(1)}, ..., Z_t^{(k)}
Zt(1),...,Zt(k)分别表示到当前时刻t中,以标签1,…,k为终点的所有路径的得分指数和。那么我们可以递归的计算:
Z
t
+
1
(
1
)
=
(
Z
t
(
1
)
T
11
+
Z
t
(
2
)
T
21
+
.
.
.
+
Z
t
(
k
)
T
k
1
)
s
t
+
1
(
1
∣
x
)
Z_{t+1}^{(1)} = (Z_t^{(1)}T_{11}+Z_t^{(2)}T_{21}+...+Z_t^{(k)}T_{k1})s_{t+1}(1|x)
Zt+1(1)=(Zt(1)T11+Zt(2)T21+...+Zt(k)Tk1)st+1(1∣x)
Z
t
+
1
(
2
)
=
(
Z
t
(
1
)
T
12
+
Z
t
(
2
)
T
22
+
.
.
.
+
Z
t
(
k
)
T
k
2
)
s
t
+
1
(
2
∣
x
)
Z_{t+1}^{(2)} = (Z_t^{(1)}T_{12}+Z_t^{(2)}T_{22}+...+Z_t^{(k)}T_{k2})s_{t+1}(2|x)
Zt+1(2)=(Zt(1)T12+Zt(2)T22+...+Zt(k)Tk2)st+1(2∣x)
…
Z
t
+
1
(
1
)
=
(
Z
t
(
k
)
T
1
k
+
Z
t
(
2
)
T
2
k
+
.
.
.
+
Z
t
(
k
)
T
k
k
)
s
t
+
1
(
k
∣
x
)
Z_{t+1}^{(1)} = (Z_t^{(k)}T_{1k}+Z_t^{(2)}T_{2k}+...+Z_t^{(k)}T_{kk})s_{t+1}(k|x)
Zt+1(1)=(Zt(k)T1k+Zt(2)T2k+...+Zt(k)Tkk)st+1(k∣x)
其中
T
(
i
,
j
)
T(i, j)
T(i,j)元素表示的是label
y
i
y_i
yi到label
y
j
y_j
yj的转移取指数后的分值,而
s
t
+
1
(
i
∣
x
)
s_{t+1}(i|x)
st+1(i∣x)表示的是对label标签为
i
i
i的发射分值。上述可以简写为矩阵乘法形式如下:
Z
t
+
1
=
Z
t
T
⊗
S
(
y
t
+
1
∣
x
)
Z_{t+1} = Z_tT \otimes S(y_{t+1}|x)
Zt+1=ZtT⊗S(yt+1∣x)
其中
S
(
y
t
+
1
∣
x
)
S(y_{t+1}|x)
S(yt+1∣x)表示的是在位置t+1时刻,对每个label标签打分的指数值。
2.2.4 如何定义crf损失函数
训练crf模型,我们用负对数似然函数为损失函数,如:
L
(
θ
)
=
−
l
o
g
P
(
y
∣
x
)
L(\theta)=-logP(y|x)
L(θ)=−logP(y∣x)
=
−
l
o
g
(
e
x
p
(
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
)
∑
y
e
x
p
(
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
)
)
=-log(\frac{exp(\sum_{j=1}^n\sum_{i=1}^m \lambda_i f_i(y_{j-1},y_j,x,j))}{\sum_yexp(\sum_{j=1}^n\sum_{i=1}^m \lambda_i f_i(y_{j-1},y_j,x,j))})
=−log(∑yexp(∑j=1n∑i=1mλifi(yj−1,yj,x,j))exp(∑j=1n∑i=1mλifi(yj−1,yj,x,j)))
=
−
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
+
l
o
g
(
∑
y
e
x
p
(
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
)
)
=-\sum_{j=1}^n\sum_{i=1}^m\lambda_if_i(y_{j-1},y_j,x,j) + log(\sum_y exp(\sum_{j=1}^n\sum_{i=1}^m \lambda_i f_i(y_{j-1},y_j,x,j)))
=−j=1∑ni=1∑mλifi(yj−1,yj,x,j)+log(y∑exp(j=1∑ni=1∑mλifi(yj−1,yj,x,j)))
我们的优化目标是使得正确的label序列
P
(
y
1
,
.
.
.
,
y
n
∣
x
)
P(y_1,...,y_n|x)
P(y1,...,yn∣x)概率值尽可能的大,则
−
l
o
g
P
(
y
1
,
.
.
.
,
y
n
)
-logP(y_1,...,y_n)
−logP(y1,...,yn)损失函数loss就会尽可能的小。
那如何求导参数
λ
k
\lambda_k
λk梯度?
∂
L
(
θ
)
∂
λ
k
=
−
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
+
1
Z
(
x
)
∂
Z
(
x
)
∂
λ
k
\frac{ \partial L(\theta)}{\partial \lambda_k} = -\sum_{j=1}^nf_k(y_{j-1},y_j,x,j)+\frac{1}{Z(x)}\frac{\partial Z(x)}{\partial \lambda_k}
∂λk∂L(θ)=−j=1∑nfk(yj−1,yj,x,j)+Z(x)1∂λk∂Z(x)
=
−
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
+
∑
y
p
(
y
∣
x
)
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
=-\sum_{j=1}^nf_k(y_{j-1},y_j,x,j)+ \sum_y p(y|x)\sum_{j=1}^nf_k(y_{j-1},y_j,x,j)
=−j=1∑nfk(yj−1,yj,x,j)+y∑p(y∣x)j=1∑nfk(yj−1,yj,x,j)
其中,
1
Z
(
x
)
∂
Z
(
x
)
∂
λ
k
\frac{1}{Z(x)}\frac{\partial Z(x)}{\partial \lambda_k}
Z(x)1∂λk∂Z(x)
=
1
Z
(
x
)
∑
y
e
x
p
(
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
)
⋅
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
=\frac{1}{Z(x)}\sum_yexp(\sum_{j=1}^n\sum_{i=1}^m\lambda_if_i(y_{j-1},y_j,x,j))\cdot \sum_{j=1}^nf_k(y_{j-1},y_j,x,j)
=Z(x)1y∑exp(j=1∑ni=1∑mλifi(yj−1,yj,x,j))⋅j=1∑nfk(yj−1,yj,x,j)
=
∑
y
1
Z
(
x
)
e
x
p
(
∑
j
=
1
n
∑
i
=
1
m
λ
i
f
i
(
y
j
−
1
,
y
j
,
x
,
j
)
)
⋅
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
= \sum_y \frac{1}{Z(x)} exp(\sum_{j=1}^n\sum_{i=1}^m\lambda_if_i(y_{j-1},y_j,x,j))\cdot \sum_{j=1}^nf_k(y_{j-1},y_j,x,j)
=y∑Z(x)1exp(j=1∑ni=1∑mλifi(yj−1,yj,x,j))⋅j=1∑nfk(yj−1,yj,x,j)
=
∑
y
p
(
y
∣
x
)
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
= \sum_y p(y|x)\sum_{j=1}^nf_k(y_{j-1},y_j,x,j)
=y∑p(y∣x)j=1∑nfk(yj−1,yj,x,j)
最终,我们可以得到对参数
λ
k
\lambda_k
λk的导数公式为:
∂
L
(
θ
)
∂
λ
k
=
∑
y
p
(
y
∣
x
)
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
−
∑
j
=
1
n
f
k
(
y
j
−
1
,
y
j
,
x
,
j
)
\frac{ \partial L(\theta)}{\partial \lambda_k} =\sum_y p(y|x)\sum_{j=1}^nf_k(y_{j-1},y_j,x,j)-\sum_{j=1}^nf_k(y_{j-1},y_j,x,j)
∂λk∂L(θ)=y∑p(y∣x)j=1∑nfk(yj−1,yj,x,j)−j=1∑nfk(yj−1,yj,x,j)
=
E
λ
[
f
i
]
−
E
D
[
f
i
]
=E_{\lambda}[f_i]-E_D[f_i]
=Eλ[fi]−ED[fi]
其中
E
λ
[
f
i
]
E_{\lambda}[f_i]
Eλ[fi]表示的是模型对特征的期望,更直观的解释是,模型对每条路径预测的概率分值
p
(
y
∣
x
)
p(y|x)
p(y∣x)与该条路径对应的在参数为
λ
k
\lambda_k
λk对应的特征函数分值的加权之和,
E
D
[
f
i
]
E_D[f_i]
ED[fi]表示的是数据对特征的期望,也就是说在参数为
λ
k
\lambda_k
λk对应的特征函数分值。从公式可以看出,当
E
λ
[
f
i
]
E_{\lambda}[f_i]
Eλ[fi]与
E
D
[
f
i
]
E_D[f_i]
ED[fi]越接近的时候,对应的导数越接近0,则更新参数不需调整,而当
E
λ
[
f
i
]
E_{\lambda}[f_i]
Eλ[fi]>
E
D
[
f
i
]
E_D[f_i]
ED[fi]时,则梯度>0,模型的参数需要调小,相反,需要调大。整体就是希望模型对特征的期望与数据对特征的期望尽可能的一致,这样我们学出来的模型才能够尽可能的拟合我们训练的数据。
2.2.4 预测 (Viterbi)
crf训练完后,我们可以得到每个特征函数对应的参数权重,在分词任务中,我们对应的label是4种,对于一个6个字的输入,eg: “兔子喜欢吃菜”,穷举计算的话,我们需要计算
4
6
=
256
4^6=256
46=256条路径,而对应最大分值的路径就是我们的全局最优解。但如果输入序列长100,则需要计算
4
100
4^{100}
4100,复杂度太高。
有没有更高效的算法?答案肯定是有,这就是维特比 (viterbi) 算法,viterbi算法的思想就是基于每一步结果的局部最优去寻找全局最优,如下图所示:
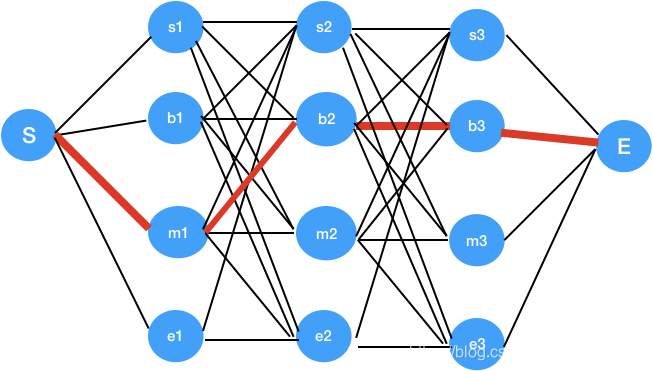
我们要求从S (开始)到E (结束) 的分值最大路径,假设全局最优解是红色的路径“S->m1->b2->b3->E”,若穷举法,我们需要计算
4
3
=
64
4^3=64
43=64条路径,也就是复杂度为
O
(
K
N
)
O(K^N)
O(KN),其中
K
K
K表示label总数量,在这里等于4,而
N
N
N表示的输入序列长度,那基于viterbi算法,则时间复杂度降为
O
(
N
K
2
)
O(NK^2)
O(NK2),当N很大,维特比算法大大降低了时间复杂度。
首先我们从图可知,全局分值最大路径“S->m1->b2->b3->E”,经过中间节点"m1",“b2”, "b3"也必是局部分值最大路径,也就是说路径"S->m1->b2"是S到b2的分值最大路径,这样我们就可以把问题分成一个更小的问题,通过局部的最优去寻找全局最优。每一层的节点都只记录到达该节点的分值最大路径,其余到达该节点的路径可以丢弃,减少计算量。计算步骤如下:
- 从S到第一层分值最大路径计算:由于第一层的4个节点s1,b1,m1,e1,从S出发,只有一条路径可到达,所以每个节点保留的最优路径为"S->s1", “S->b1”, “S->m1”, “S->e1”
- 从第一层到第二层分值最大路径计算:第二层有4个节点s2,b2,m2,e2,对于s2节点,可以从s1,b1,m1,e1这4个节点经过,我们只需要保留到达s2节点分值最大的路径,计算量为 4 × 4 4\times4 4×4,同理计算其它节点
- 从第二层到第三层分值最大路径计算:第三层4个节点s3,b3,m3,e3,同上,到达每个节点路径有4条,只需保留分值最大路径,计算量为 4 × 4 4\times4 4×4
- 从第三层到E分值最大路径计算:计算到这来,我们已经得到到达s3,b3,m3,e3的最大分值路径(共4条),到达E, 只需要计算这4条路径分值分别加上s3,b3,m3,e3节点到E的分值,然后选取最大的分值路径就是我们的全局最优路径。
所以整个计算复杂度由 O ( K N ) O(K^N) O(KN)变为 O ( N K 2 ) O(NK^2) O(NK2),减少的计算量核心是两点:第一,全局分值最大解路径必定经过这些局部分值最大路径;第二,通过将问题的规模缩小,把不是局部分值最大路径都可以丢弃
代码实现:
import numpy as np
import sys
def viterbi(score, transition):
"""
输入
score: [labelnum, seqlen], 发射分值
trasition: [labelnum, labelnum], 转移概率, 这里假设每一层的label i 到label j 的转移的分值一致
输出
decode: [seqlen], path索引
"""
labelnum,seqlen = score.shape
# 记录每一层到达该节点的最大累积分值
trellis = score.copy()
# 记录到达当前节点的最大分值路径的上一个节点索引位置
backpointers = np.zeros((labelnum,seqlen),dtype=int)
# 全局分值最大路径path对应的节点索引
decode = [0]*seqlen
for i in range(1,seqlen):
#转移分值加上发射分值
tran_score = transition+trellis[:,i-1:i]
#当前层的节点最大分值更新
trellis[:,i] += np.max(tran_score, axis=0)
#记录到达当前节点最大路径分值的上一层节点位置
backpointers[:,i] = np.argmax(tran_score,axis=0)
#记录最后一层分值最大的节点索引位置
idxpath = np.argmax(tran_score[:,seqlen-1])
#存储
decode[seqlen-1] = idxpath
print(trellis)
print(backpointers)
#读取最后一层最大值位置索引内容(上一层的节点位置),依次回溯)
for t in range(seqlen-1,0,-1):
idxpath = backpointers[idxpath,t]
decode[t-1] = idxpath
return decode
if __name__ == '__main__':
score = np.array([[0.9, 0.1, 0.3],
[0.1, 0.8, 0.4],
[0.0, 0.1, 0.3]])
transition = np.array([[0.1, 0.4, 0.5], [0.2, 0.7, 0.1], [0.9, 0.0, 0.1]])
print(viterbi(score,transition))
2.3 BiLSTM+CRF
上述介绍了BiLSTM和CRF分别是怎么做分词任务的,对于BiLSTM+CRF我们就容易理解多了,BiLSTM+CRF结合了BiLSTM模型较强的语义向量表征能力和CRF对label与label的转移概率学习的优点,进而提升整个模型的效果。
2.3.1 BiLSTM作用
我们知道,在crf中,目标序列概率分值简约计算公式如下:
p
(
y
∣
x
)
=
e
s
(
x
,
y
)
+
t
(
y
,
y
)
Z
(
x
)
p(y|x) = \frac{e^{s(x,y)+t(y,y)}}{Z(x)}
p(y∣x)=Z(x)es(x,y)+t(y,y)
其中
s
(
x
,
y
)
s(x,y)
s(x,y)表示的是发射分值,
t
(
y
,
y
)
t(y,y)
t(y,y)表示的是转移分值。在BiLSTM+CRF中,BiLSTM作用是对每个输入,预测对应的label分值,作为crf中的发射概率分值,也就是
s
(
x
,
y
)
s(x,y)
s(x,y)的分值由BiLSTM计算提供。
2.3.2 CRF作用
而crf层只需要学习转移概率分值 t ( y , y ) t(y,y) t(y,y),也就是学习一个 n u m s _ l a b e l × n u m s _ l a b e l nums\_label \times nums\_label nums_label×nums_label大小的转移概率矩阵。有了发射概率分值和转移概率分值,我们就可以得到序列的概率 p ( y ∣ x ) p(y|x) p(y∣x)分值,loss用负对数似然函数, − l o g p ( y ∣ x ) -logp(y|x) −logp(y∣x),这样就可以进行end-to-end的训练了。
2.3.2· 预测 (Viterbi)
BiLSTM模型对每个输入打分(图上的节点分值),crf提供label与label的转移分值(图的边分值),然后用viterbi算法,求解全局分值最大的路径。具体预测过程可参考上述的viterbi算法代码,其中score分值由BiLSTM对序列输入计算得到,transition转移矩阵分值是CRF训练得到的参数矩阵。

















 6639
6639

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









