






Introduction:
作者通过LAM的方法发现现有的 Transformer 方法在利用输入信息时只能使用有限的空间范围。因此,为了激活更多的输入像素以实现更好的重建效果,本文构建了一种新颖的混合注意力 Transformer(HAT)方法。该方法结合了通道注意力和基于窗口的自注意力机制,充分利用它们在利用全局统计信息和强大的局部拟合能力方面的互补优势。此外,作者引入了一个重叠的交叉注意力模块,增强了相邻窗口特征之间的交互作用。
Motivation:
提出了一个新颖的混合注意力 Transformer(HAT)方法和重叠交叉注意力模块,提高基于窗口自注意力方法的信息交互,在LAM方法中HAT方法能激活更多像素进行图像重建,使产生的图像纹理更加清晰。
Architecture Details:
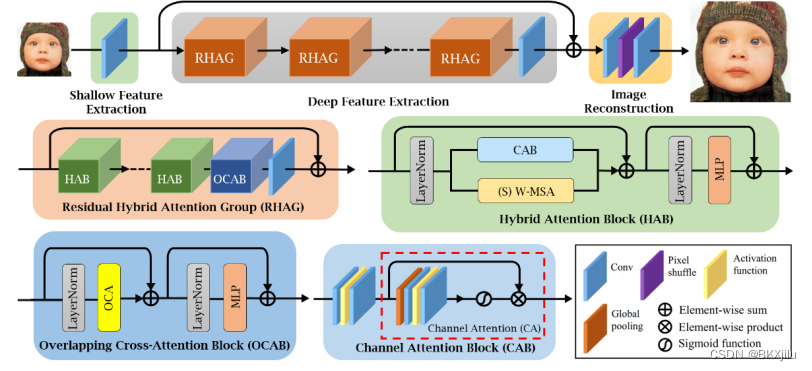
- RHAG:每个 RHAG 包含 M 个混合注意力块 (HAB)、一个重叠的交叉注意力块 (OCAB) 和一个 3×3 卷积层。OCAB 来扩大基于窗口的 self-attention 的感受野并更好地聚合跨窗口信息。
- HAB:包含通道注意力块CAB和多头自注意力块W-MSA以及移位窗口自注意力块SW-MSA。在连续 HAB 中,每隔一段时间就会采用基于移位窗口的自我注意 (SW-MSA)。为了防止CAB和MSA的视觉表示发生冲突,CAB的输出需要乘上一个常数。
- CAB :由两个标准卷积层组成,它们之间有一个 GELU 激活函数 和一个通道注意 (CA) 模块。
- OCAB: OCAB 由一个重叠交叉注意力 (OCA) 层和一个类似于标准 Swin Transformer 块的 MLP 层组成。
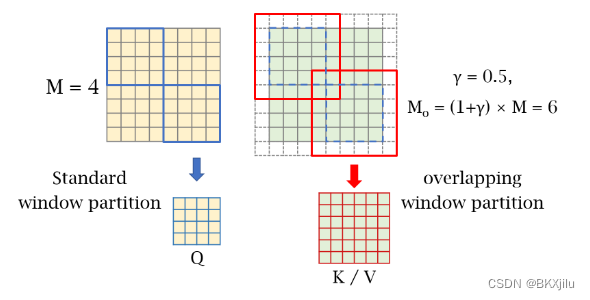
- OCA:使用不同尺寸的窗口去分割映射的图像特征,XQ被分成HW/M2个不重叠的窗口,尺寸为M x M。Xk和XV被分割成HW/M2重叠的窗口,尺寸为M0 x M0 ,其中
是一个常数。
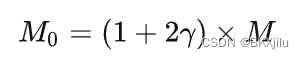
Experience:
1.探究自注意力块窗户尺寸如何影响表示能力
作者在SwinIR上进行实验,发现在大部分数据集上窗口尺寸为16x16的模型上效果更好。

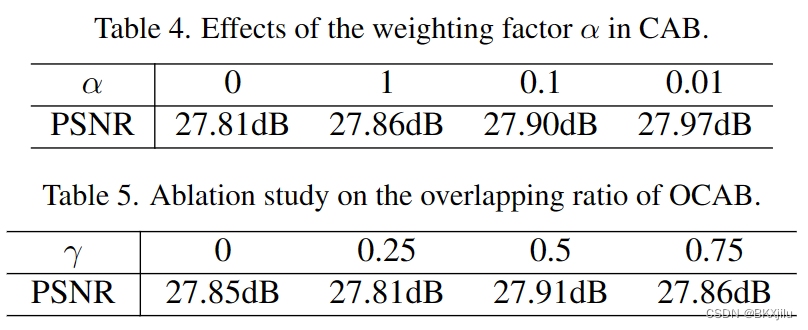
2.测试CA和重叠率对网络性能的影响。
Summary:
- 作者提出了一个重叠的交叉注意力模块,它计算不同窗口大小的特征之间的注意力,以更好地聚合交叉窗口信息。
- 在所有数据集上达到最先进水平。















 6215
6215











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









